Co-occurrence networks
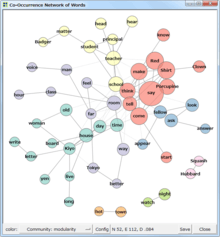
Co-occurrence networks are generally used to provide a graphic visualization of potential relationships between people, organizations, concepts or other entities represented within written material. The generation and visualization of co-occurrence networks has become practical with the advent of electronically stored text amenable to text mining.
By way of definition, co-occurrence networks are the collective interconnection of terms based on their paired presence within a specified unit of text. Networks are generated by connecting pairs of terms using a set of criteria defining co-occurrence. For example, terms A and B may be said to “co-occur” if they both appear in a particular article. Another article may contain terms B and C. Linking A to B and B to C creates a co-occurrence network of these three terms. Rules to define co-occurrence within a text corpus can be set according to desired criteria. For example, a more stringent criteria for co-occurrence may require a pair of terms to appear in the same sentence.
Methods and development
Co-occurrence networks can be created for any given list of terms (any dictionary) in relation to any collection of texts (any text corpus). Co-occurring pairs of terms can be called “neighbors” and these often group into “neighborhoods” based on their interconnections. Individual terms may have several neighbors. Neighborhoods may connect to one another through at least one individual term or may remain unconnected.
Individual terms are, within the context of text mining, symbolically represented as text strings. In the real world, the entity identified by a term normally has several symbolic representations. It is therefore useful to consider terms as being represented by one primary symbol and up to several synonymous alternative symbols. Occurrence of an individual term is established by searching for each known symbolic representations of the term. The process can be augmented through NLP (natural language processing) algorithms that interrogate segments of text for possible alternatives such as word order, spacing and hyphenation. NLP can also be used to identify sentence structure and categorize text strings according to grammar (for example, categorizing a string of text as a noun based on a preceding string of text known to be an article).
Graphic representation of co-occurrence networks allow them to be visualized and inferences drawn regarding relationships between entities in the domain represented by the dictionary of terms applied to the text corpus. Meaningful visualization normally requires simplifications of the network. For example, networks may be drawn such that the number of neighbors connecting to each term is limited. The criteria for limiting neighbors might be based on the absolute number of co-occurrences or more subtle criteria such as “probability” of co-occurrence or the presence of an intervening descriptive term.
Quantitative aspects of the underlying structure of a co-occurrence network might also be informative, such as the overall number of connections between entities, clustering of entities representing sub-domains, detecting synonyms,[1] etc.
Applications and use
Some working applications of the co-occurrence approach are available to the public through the internet. PubGene is an example of an application that addresses the interests of biomedical community by presenting networks based on the co-occurrence of genetics related terms as these appear in MEDLINE records.[2][3] The website NameBase is an example of how human relationships can be inferred by examining networks constructed from the co-occurrence of personal names in newspapers and other texts (as in Ozgur et al.[4]).
Networks of information are also used to facilitate efforts to organize and focus publicly available information for law enforcement and intelligence purposes (so called "open source intelligence" or OSINT). Related techniques include co-citation networks as well as the analysis of hyperlink and content structure on the internet (such as in the analysis of web sites connected to terrorism[5]).
See also
- Takada H, Saito K, Yamada T, Kimura M: “Analysis of Growing Co-occurrence Networks” SIG-KBS (Journal Code:X0831A) 2006, VOL.73rd;NO.;PAGE.117-122 Language;Japanese
- Liu, Chua T-S; “Building semantic perceptron net for topic spotting.” Proceedings of the 39th Annual Meeting on Association for Computational Linguistics, 2001; 378 - 385
References
- ↑ Cohen AM, Hersh WR, Dubay C, Spackman, K: “Using co-occurrence network structure to extract synonymous gene and protein names from MEDLINE abstracts” BMC Bioinformatics 2005, 6:103
- ↑ Jenssen TK, Laegreid A, Komorowski J, Hovig E: "A literature network of human genes for high-throughput analysis of gene expression. " Nature Genetics, 2001 May; 28(1):21-8. PMID 11326270
- ↑ Grivell L: “Mining the bibliome: searching for a needle in a haystack? New computing tools are needed to effectively scan the growing amount of scientific literature for useful information.” EMBO reports 2001 Mar;3(3):200-3: doi:10.1093/embo-reports/kvf059 PMID 11882534
- ↑ Ozgur A, Cetin B, Bingol H: “Co-occurrence Network of Reuters News” (15 Dec 2007) http://arxiv.org/abs/0712.2491
- ↑ Zhou Y, Reid E, Qin J, Chen H, Lai G: "US Domestic Extremist Groups on the Web: Link and Content Analysis" http://doi.ieeecomputersociety.org/10.1109/MIS.2005.96