Kogge–Stone adder
The Kogge–Stone adder is a parallel prefix form carry look-ahead adder. Other parallel prefix adders include the Brent-Kung adder, the Han Carlson adder, and the fastest known variation, the Lynch-Swartzlander Spanning Tree adder.[1]
The Kogge–Stone adder takes more area to implement than the Brent–Kung adder, but has a lower fan-out at each stage, which increases performance for typical CMOS process nodes. However, wiring congestion is often a problem for Kogge–Stone adders. The Lynch-Swartzlander design is smaller, has lower fan-out, and does not suffer from wiring congestion; however to be used the process node must support Manchester Carry Chain implementations. The general problem of optimizing parallel prefix adders is identical to the variable block size, multi level, carry-skip adder optimization problem, a solution of which is found in.[2]
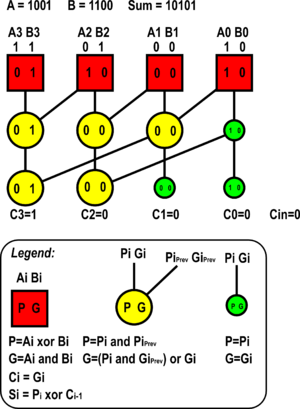
An example of a 4-bit Kogge–Stone adder is shown in the diagram. Each vertical stage produces a "propagate" and a "generate" bit, as shown. The culminating generate bits (the carries) are produced in the last stage (vertically), and these bits are XOR'd with the initial propagate after the input (the red boxes) to produce the sum bits. E.g., the first (least-significant) sum bit is calculated by XORing the propagate in the farthest-right red box (a "1") with the carry-in (a "0"), producing a "1". The second bit is calculated by XORing the propagate in second box from the right (a "0") with C0 (a "0"), producing a "0".
The Kogge–Stone adder concept was developed by Peter M. Kogge and Harold S. Stone, which they published in 1973 in a seminal paper titled A Parallel Algorithm for the Efficient Solution of a General Class of Recurrence Equations.[3]
Enhancements
Enhancements to the original implementation include increasing the radix and sparsity of the adder. The radix of the adder refers to how many results from the previous level of computation are used to generate the next one. The original implementation uses radix-2, although it's possible to create radix-4 and higher. Doing so increases the power and delay of each stage, but reduces the number of required stages. The sparsity of the adder refers to how many carry bits are generated by the carry-tree. Generating every carry bit is called sparsity-1, whereas generating every other is sparsity-2 and every fourth is sparsity-4. The resulting carries are then used as the carry-in inputs for much shorter ripple carry adders or some other adder design, which generates the final sum bits. Increasing sparsity reduces the total needed computation and can reduce the amount of routing congestion.

Above is an example of a Kogge–Stone adder with sparsity-4. Elements eliminated by sparsity shown marked with transparency. As shown, power and area of the carry generation is improved significantly, and routing congestion is substantially reduced. Each generated carry feeds a multiplexer for a carry select adder or the carry-in of a ripple carry adder.
Expansion
- this example is a Carry look ahead - In a 4 bit adder like the one shown in the introductory image of this article, there are 5 outputs. Below is the expansion:
S0 = (A0 XOR B0) XOR Cin S1 = (A1 XOR B1) XOR ((A0 AND B0) OR (A0 XOR B0) AND Cin) S2 = (A2 XOR B2) XOR (((A1 XOR B1) AND ((A0 AND B0) OR (A0 XOR B0) AND Cin)) OR (A1 AND B1)) S3 = (A3 XOR B3) XOR ((((A2 XOR B2) AND (A1 XOR B1)) AND ((A0 AND B0) OR (A0 XOR B0) AND Cin)) OR (((A2 XOR B2) AND (A1 AND B1)) OR (A2 AND B2))) S4 = (A3 AND B3) OR (A3 XOR B3) AND ((((A2 XOR B2) AND (A1 XOR B1)) AND ((A0 AND B0)or(A0 XOR B0) AND Cin)) OR (((A2 XOR B2) AND (A1 AND B1)) OR (A2 AND B2)))
References
- ↑ Lynch, Thomas W. "Binary Adders", University of Texas Thesis, May 1996
- ↑ Lynch, Thomas W. "Binary Adders", University of Texas Thesis, May 1996
- ↑ Kogge, P. & Stone, H. "A Parallel Algorithm for the Efficient Solution of a General Class of Recurrence Equations". IEEE Transactions on Computers, 1973, C-22, 783-791
Further reading
- Oklobdzija, V. G.; Zeydel, B. R. (2006). "Energy-Delay Characteristics of CMOS Adders". High-Performance Energy-Efficient Microprocessor Design. Series on Integrated Circuits and Systems. p. 147. doi:10.1007/978-0-387-34047-0_6. ISBN 978-0-387-28594-8.