Markov chains on a measurable state space
A Markov chain on a measurable state space is a discrete-time-homogenous Markov chain with a measurable space as state space.
History
The definition of Markov chains has evolved during the 20th century. In 1953 the term Markov chain was used for stochastic processes with discrete or continuous index set, living on a countable or finite state space, see Doob.[1] or Chung.[2] Since the late 20th century it became more popular to consider a Markov chain as a stochastic process with discrete index set, living on a measurable state space.[3][4][5]
Definition
Denote with 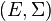 a measurable space and with
a measurable space and with 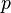 a Markov kernel with source and target .
A stochastic process
a Markov kernel with source and target .
A stochastic process 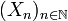 on
on 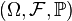 is called a time homogeneous Markov chain with Markov kernel and start distribution
is called a time homogeneous Markov chain with Markov kernel and start distribution 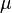 if
if
![\mathbb{P}[X_0 \in A_0 , X_1 \in A_1, \dots , X_n \in A_n] = \int_{A_0} \dots \int_{A_{n-1}} p(y_{n-1},A_n) \, p(y_{n-2},dy_{n-1}) \dots p(y_0,dy_1) \, \mu(dy_0)](../I/m/0f81552d343a94039a2ab9aeb59737a3.png)
is satisfied for any 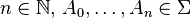 . One can construct for any Markov kernel and any probability measure an associated Markov chain.[4]
. One can construct for any Markov kernel and any probability measure an associated Markov chain.[4]
Remark about Markov kernel integration
For any measure ![\mu \colon \Sigma \to [0,\infty]](../I/m/a87c36f5c5affaf118790acf557cdeb7.png) we denote for -integrable function
we denote for -integrable function 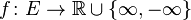 the Lebesgue integral as
the Lebesgue integral as 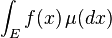 . For the measure
. For the measure ![\nu_x \colon \Sigma \to [0,\infty]](../I/m/ff270c987d98f78d92380d7c94cf5bf9.png) defined by
defined by 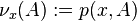 we used the following notation:
we used the following notation:
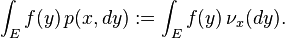
Basic properties
Starting in a single point
If is a Dirac measure in 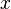 , we denote for a Markov kernel with starting distribution the associated Markov chain as on
, we denote for a Markov kernel with starting distribution the associated Markov chain as on 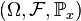 and the expectation value
and the expectation value
![\mathbb{E}_x[X] = \int_\Omega X(\omega) \, \mathbb{P}_x(d\omega)](../I/m/13540006fdceca20311dd389ecdd2033.png)
for a 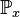 -integrable function
-integrable function 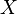 . By definition, we have then
. By definition, we have then
![\mathbb{P}_x[X_0 = x] = 1](../I/m/a00961dacd85779442498f56f3d9ce26.png) .
.
We have for any measurable function ![f \colon E \to [0,\infty]](../I/m/4505ddc59960d089d19381ccf3130242.png) the following relation:[4]
the following relation:[4]
![\int_E f(y) \, p(x,dy) = \mathbb{E}_x[f(X_1)].](../I/m/62cddf49252e7eae0aec879e32affb43.png)
Family of Markov kernels
For a Markov kernel with starting distribution one can introduce a family of Markov kernels 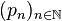 by
by
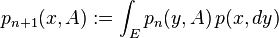
for  and
and 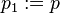 . For the associated Markov chain according to and one obtains
. For the associated Markov chain according to and one obtains
![\mathbb{P}[X_0 \in A , \, X_n \in B ] = \int_A p_n(x,B) \, \mu(dx)](../I/m/bb09a3c36dca33171dff271f15286900.png) .
.
Stationary measure
A probability measure is called stationary measure of a Markov kernel if
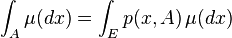
holds for any 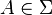 . If on
denotes the Markov chain according to a Markov kernel with stationary measure , then all
. If on
denotes the Markov chain according to a Markov kernel with stationary measure , then all 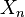 have the same probability distribution, namely:
have the same probability distribution, namely:
![\mathbb{P}[X_n \in A ] = \mu(A)](../I/m/c950a5845ee98bd5032317b9081276cd.png)
for any .
Reversibility
A Markov kernel is called reversible according to a probability measure if
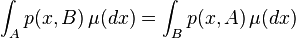
holds for any 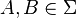 .
Replacing
.
Replacing  shows that if is reversible according to , then must be a stationary measure of .
shows that if is reversible according to , then must be a stationary measure of .
References
- ↑ Joseph L. Doob: Stochastic Processes. New York: John Wiley & Sons, 1953.
- ↑ Kai L. Chung: Markov Chains with Stationary Transition Probabilities. Second edition. Berlin: Springer-Verlag, 1974.
- ↑ Sean Meyn and Richard L. Tweedie: Markov Chains and Stochastic Stability. 2nd edition, 2009.
- 1 2 3 Daniel Revuz: Markov Chains. 2nd edition, 1984.
- ↑ Rick Durrett: Probability:Theory and Examples' Fourth edition, 2005.