Sliding window based part-of-speech tagging
Sliding window based part-of-speech tagging is used to part-of-speech tag a text.
A high percentage of words in a natural language are words which out of context can be assigned more than one part of speech. The percentage of these ambiguous words is typically around 30%, although it depends greatly on the language. Solving this problem is very important in many areas of natural language processing. For example in machine translation changing the part-of-speech of a word can dramatically change its translation.
Sliding window based part-of-speech taggers are programs which assign a single part-of-speech to a given lexical form of a word, by looking at a fixed sized "window" of words around the word to be disambiguated.
The two main advantages of this approach are:
- It is possible to automatically train the tagger, getting rid of the need of manually tagging a corpus.
- The tagger can be implemented as a finite state automaton (Mealy machine)
Formal definition
Let
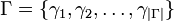
be the set of grammatical tags of the application, that is, the set of all possible tags which may be assigned to a word, and let
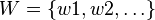
be the vocabulary of the application. Let
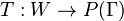
be a function for morphological analysis which assigns each 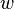 its set of possible tags,
its set of possible tags, 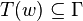 , that can be implemented by a full-form lexicon, or a morphological analyser. Let
, that can be implemented by a full-form lexicon, or a morphological analyser. Let
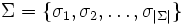
be the set of word classes, that in general will be a partition of 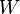 with the restriction that for each
with the restriction that for each 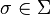 all of the words
all of the words 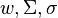 will receive the same set of tags, that is, all of the words in each word class
will receive the same set of tags, that is, all of the words in each word class 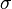 belong to the same ambiguity class.
belong to the same ambiguity class.
Normally, 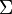 is constructed in a way that for high frequency words, each word class contains a single word, while for low frequency words, each word class corresponds to a single ambiguity class. This allows good performance for high frequency ambiguous words, and doesn't require too many parameters for the tagger.
is constructed in a way that for high frequency words, each word class contains a single word, while for low frequency words, each word class corresponds to a single ambiguity class. This allows good performance for high frequency ambiguous words, and doesn't require too many parameters for the tagger.
With these definitions it is possible to state problem in the following way: Given a text ![w[1] w[2] \ldots w[L] \in W^*](../I/m/fce70b9581df757b37c726f7f4e1d859.png) each word
each word ![w[t]](../I/m/9c1cca86e1b38572f4d0105e4a605634.png) is assigned a word class
is assigned a word class ![T ( w[t] ) \in \Sigma](../I/m/329e8339ae36ee516b88da020c3fd4c1.png) (either by using the lexicon or morphological analyser) in order to get an ambiguously tagged text
(either by using the lexicon or morphological analyser) in order to get an ambiguously tagged text ![\sigma[1] \sigma[2] \ldots \sigma[L] \in W^*](../I/m/a83a9f500cee9c5a59cf104f94b6fe49.png) . The job of the tagger is to get a tagged text
. The job of the tagger is to get a tagged text ![\gamma[1] \gamma[2] \ldots \gamma[L]](../I/m/97b712bf28b14d54173db2608850ae95.png) (with
(with ![\gamma[t] \in T(\sigma[t])](../I/m/59b0165c344d2ec8a5813f07fce5da10.png) ) as correct as possible.
) as correct as possible.
A statistical tagger looks for the most probable tag for an ambiguously tagged text ![\sigma[1] \sigma[2] \ldots \sigma[L]](../I/m/d47fdfe1d245a0da69eaa03241a302e2.png) :
:
![\gamma^*[1] \ldots \gamma^*[L] = \operatorname{\arg\,max}_{\gamma[t] \in T(\sigma[t])} p(\gamma[1] \ldots \gamma[L] \sigma[1] \ldots \sigma[L])](../I/m/96c7a754f8af538058c8fc1d37921604.png)
Using Bayes formula, this is converted into:
![\gamma^*[1] \ldots \gamma^*[L] = \operatorname{\arg\,max}_{\gamma[t] \in T(\sigma[t])} p(\gamma[1] \ldots \gamma[L]) p(\sigma[1] \ldots \sigma[L] \gamma[1] \ldots \gamma[L])](../I/m/c35d3fead3de4c64b35d252fea9533fe.png)
where ![p(\gamma[1] \gamma[2] \ldots \gamma[L])](../I/m/0353464c02c2b4176e41d75b634eb9a6.png) is the probability that a particular tag (syntactic probability) and
is the probability that a particular tag (syntactic probability) and ![p(\sigma[1] \dots \sigma[L] \gamma[1] \ldots \gamma[L])](../I/m/f5fcc81a097841795e0cb8c814199d36.png) is the probability that this tag corresponds to the text
is the probability that this tag corresponds to the text ![\sigma[1] \ldots \sigma[L]](../I/m/03702b76f67ce9a2c58aa18998e623e4.png) (lexical probability).
(lexical probability).
In a Markov model, these probabilities are approximated as products. The syntactic probabilities are modelled by a first order Markov process:
![p(\gamma[1] \gamma[2] \ldots \gamma[L]) = \prod_{t=1}^{t=L} p(\gamma[t+1] \gamma[t])](../I/m/3876053ea29da5e13dbed48afdf71f90.png)
where ![\gamma[0]](../I/m/e3c1ee1cc68a3707ebd0d23f34508ec8.png) and
and ![\gamma[L+1]](../I/m/4efd04678c8771c3dfc4e90426fc4a34.png) are delimiter symbols.
are delimiter symbols.
Lexical probabilities are independent of context:
![p(\sigma[1] \sigma[2] \ldots \sigma[L] \gamma[1] \gamma[2] \ldots \gamma[L]) = \prod_{t=1}^{t=L} p(\sigma[t] \gamma[t])](../I/m/6ccd2b40c61a02501986c77692685dae.png)
One form of tagging is to approximate the first probability formula:
![p(\sigma[1] \sigma[2] \ldots \sigma[L] \gamma[1] \gamma[2] \ldots \gamma[L]) = \prod_{t=1}^{t=L} p(\gamma[t] C_{(-)}[t] \sigma[t] C_{(+)}[t])](../I/m/4f4f9cbbb30243e145663457615c4702.png)
where ![C_{(-)}[t] = \sigma[t - N_{(-)}] \sigma [t - N_{(-)}] \ldots \sigma[t - 1]](../I/m/e8d585393b6ba438ee1b1d42ac639215.png) is the right context of the size
is the right context of the size 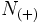 .
.
In this way the sliding window algorithm only has to take into account a context of size 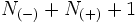 . For most applications
. For most applications 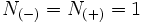 . For example to tag the ambiguous word "run" in the sentence "He runs from danger", only the tags of the words "He" and "from" are needed to be taken into account.
. For example to tag the ambiguous word "run" in the sentence "He runs from danger", only the tags of the words "He" and "from" are needed to be taken into account.
Further reading
- Sanchez-Villamil, E., Forcada, M. L., and Carrasco, R. C. (2005). "Unsupervised training of a finite-state sliding-window part-of-speech tagger". Lecture Notes in Computer Science / Lecture Notes in Artificial Intelligence, vol. 3230, p. 454-463