Contextual image classification
Contextual image classification, a topic of pattern recognition in computer vision, is an approach of classification based on contextual information in images. "Contextual" means this approach is focusing on the relationship of the nearby pixels, which is also called neighbourhood. The goal of this approach is to classify the images by using the contextual information.
Introduction
Similar as processing language, a single word may have multiple meanings unless the context is provided, and the patterns within the sentences are the only informative segments we care about. For images, the principle is same. Find out the patterns and associate proper meanings to them.
As the image illustrated below, if only a small portion of the image is shown, it is very difficult to tell what the image is about.

Even try another portion of the image, it is still difficult to classify the image.

However, if we increase the contextual of the image, then it makes more sense to recognize.

As the full images shows below, almost everyone can classify it easily.

During the procedure of segmentation, the methods which do not use the contextual information are sensitive to noise and variations, thus the result of segmentation will contain a great deal of misclassified regions, and often these regions are small (e.g., one pixel).
Compared to other techniques, this approach is robust to noise and substantial variations for it takes the continuity of the segments into account.
Several methods of this approach will be described below.
Applications
Functioning as a post-processing filter to a labelled image
This approach is very effective against small regions caused by noise. And these small regions are usually formed by few pixels or one pixel. The most probable label is assigned to these regions. However, there is a drawback of this method. The small regions also can be formed by correct regions rather than noise, and in this case the method is actually making the classification worse. This approach is widely used in remote sensing applications.
Improving the post-processing classification
This is a two-stage classification process:
- For each pixel, label the pixel and form a new feature vector for it.
- Use the new feature vector and combine the contextual information to assign the final label to the
Merging the pixels in earlier stages
Instead of using single pixels, the neighbour pixels can be merged into homogeneous regions benefiting from contextual information. And provide these regions to classifier.
Acquiring pixel feature from neighbourhood
The original spectral data can be enriched by adding the contextual information carried by the neighbour pixels, or even replaced in some occasions. This kind of pre-processing methods are widely used in textured image recognition. The typical approaches include mean values, variances, texture description, etc.
Combining spectral and spatial information
The classifier uses the grey level and pixel neighbourhood (contextual information) to assign labels to pixels. In such case the information is a combination of spectral and spatial information.
Powered by the Bayes minimum error classifier
Contextual classification of image data is based on the Bayes minimum error classifier (also known as a naive Bayes classifier).
Present the pixel:
- A pixel is denoted as
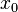 .
. - The neighbourhood of each pixel is a vector and denoted as
 .
.
- The values in the neighbourhood vector is denoted as
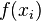 .
. - Each pixel is presented by the vector
- The values in the neighbourhood vector is denoted as
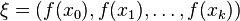

- The labels (classification) of pixels in the neighbourhood are presented as a vector
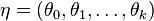
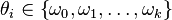
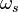 here denotes the assigned class.
here denotes the assigned class.
- A vector presents the labels in the neighbourhood without the pixel
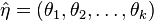
The neighbourhood:
Size of the neighbourhood. There is no limitation of the size, but it is considered to be relatively small for each pixel .
A reasonable size of neighbourhood would be 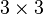 of 4-connectivity or 8-connectivity ( is marked as red and placed in the centre).
of 4-connectivity or 8-connectivity ( is marked as red and placed in the centre).
-

4-connectivity neighbourhood,
-

8-connectivity neighbourhood
The calculation:
Apply the minimum error classification on a pixel , if the probability of a class 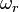 being presenting the pixel is the highest among all, then assign as its class.
being presenting the pixel is the highest among all, then assign as its class.
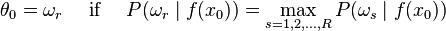
The contextual classification rule is described as below, it uses the feature vector 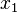 rather than .
rather than .
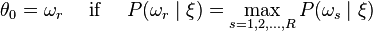
Use the Bayes formula to calculate the posteriori probability 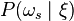
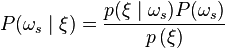
The amount of vectors is the same as the number of pixels in the image. For the classifier uses a vector corresponding to each pixel  , and the vector is generated from the pixel's neighbourhood.
, and the vector is generated from the pixel's neighbourhood.
The basic steps of contextual image classification:
- Calculate the feature vector
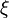 for each pixel.
for each pixel. - Calculate the parameters of probability distribution
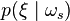 and
and 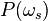
- Calculate the posterior probabilities
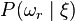 and all labels
and all labels 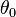 . Get the image classification result.
. Get the image classification result.
Algorithms
Template matching
The template matching is a "brute force" implementation of this approach.[1] The concept is first create a set of templates, and then look for small parts in the image match with a template.
This method is computationally high and inefficient. It keeps an entire templates list during the whole process and the number of combinations is extremely high. For a 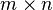 pixel image, there could be a maximum of
pixel image, there could be a maximum of 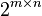 combinations, which leads to high computation. This method is a top down method and often called table look-up or dictionary look-up.
combinations, which leads to high computation. This method is a top down method and often called table look-up or dictionary look-up.
Lower-order Markov chain
The Markov chain[2] also can be applied in pattern recognition. The pixels in an image can be recognised as a set of random variables, then use the lower order Markov chain to find the relationship among the pixels. The image is treated as a virtual line, and the method uses conditional probability.
Hilbert space-filling curves
The Hilbert curve runs in a unique pattern through the whole image, it traverses every pixel without visiting any of them twice and keeps a continuous curve. It is fast and efficient.
Markov meshes
The lower-order Markov chain and Hilbert space-filling curves mentioned above are treating the image as a line structure. The Markov meshes however will take the two dimensional information into account.
Dependency tree
The dependency tree[3] is a method using tree dependency to approximate probability distributions.
References
- ↑ G.T. Toussaint, "The Use of Context in Pattern Recognition," Pattern Recognition, vol. 10, 1977, pp. 189–204.
- ↑ K. Abend, T.J. Harley, and L.N. Kanal, "Classification of Binary Random Patterns," IEEE Transactions on Information Theory, vol. 11, no. 4, October 1965, pp. 538–544.
- ↑ C.K. Chow and C.N. Liu, "Approximating Discrete Probability Distributions with Dependence Trees," IEEE Transaction on Information Theory, vol.14, no. 3, May 1965, pp. 462–467.
External links
- Advanced Vision homepage
- The Use of Context in Pattern Recognition
- Image Analysis and Understanding: contextual image classification