ext4
| Developer(s) | Mingming Cao, Andreas Dilger, Alex Zhuravlev (Tomas), Dave Kleikamp, Theodore Ts'o, Eric Sandeen, Sam Naghshineh, others |
|---|---|
| Full name | Fourth extended file system |
| Introduced |
Stable: 21 October 2008 Unstable: 10 October 2006 with Linux 2.6.28, 2.6.19 |
| Partition identifier |
0x83: MBR/EBR. |
| Structures | |
| Directory contents | Linked list, hashed B-tree |
| File allocation | Extents/Bitmap |
| Bad blocks | Table |
| Limits | |
| Max. volume size |
1 EiB |
| Max. file size | 16 TiB (for 4k block filesystem) |
| Max. number of files | 4 billion (specified at filesystem creation time) |
| Max. filename length | 255 bytes |
| Allowed characters in filenames | All bytes except NUL ('\0') and '/' and the special file names "." and ".." |
| Features | |
| Dates recorded | modification (mtime), attribute modification (ctime), access (atime), delete (dtime), create (crtime) |
| Date range | 14 December 1901 - 25 April 2514 |
| Date resolution | Nanosecond |
| Forks | No |
| Attributes | acl, bh, bsddf, commit=nrsec, data=journal, data=ordered, data=writeback, delalloc, extents, journal_dev, mballoc, minixdf, noacl, nobh, nodelalloc,noextents, nomballoc, nouser_xattr, oldalloc, orlov, user_xattr |
| File system permissions | POSIX |
| Transparent compression | No |
| Transparent encryption | Yes |
| Data deduplication | No |
| Other | |
| Supported operating systems |
Linux FreeBSD (read-only in kernel since version 10.1) Mac OS X (read-only with ext4fuse, full with ExtFS) Windows (Read/Write without journaling with ext2fsd) |
The ext4 or fourth extended filesystem is a journaling file system for Linux, developed as the successor to ext3.
History
ext4 was born as a series of backward compatible extensions to ext3, many of them originally developed by Cluster File Systems for the Lustre file system between 2003 and 2006, meant to extend storage limits and add other performance improvements.[3] However, other Linux kernel developers opposed accepting extensions to ext3 for stability reasons,[4] and proposed to fork the source code of ext3, rename it as ext4, and perform all the development there, without affecting the current ext3 users. This proposal was accepted, and on 28 June 2006, Theodore Ts'o, the ext3 maintainer, announced the new plan of development for ext4.[5]
A preliminary development version of ext4 was included in version 2.6.19[6] of the Linux kernel. On 11 October 2008, the patches that mark ext4 as stable code were merged in the Linux 2.6.28 source code repositories,[7] denoting the end of the development phase and recommending ext4 adoption. Kernel 2.6.28, containing the ext4 filesystem, was finally released on 25 December 2008.[8] On 15 January 2010, Google announced that it would upgrade its storage infrastructure from ext2 to ext4.[9] On 14 December 2010, they also announced they would use ext4, instead of YAFFS, on Android 2.3.[10]
Features
- Large file system
- The ext4 filesystem can support volumes with sizes up to 1 exbibyte (EiB) and files with sizes up to 16 tebibytes (TiB).[11] However, Red Hat recommends using XFS instead of ext4 for volumes larger than 100 TB.[12][13]
- Extents
- Extents replace the traditional block mapping scheme used by ext2 and ext3. An extent is a range of contiguous physical blocks, improving large file performance and reducing fragmentation. A single extent in ext4 can map up to 128 MiB of contiguous space with a 4 KiB block size.[3] There can be four extents stored in the inode. When there are more than four extents to a file, the rest of the extents are indexed in a tree.[14]
- Backward compatibility
- ext4 is backward compatible with ext3 and ext2, making it possible to mount ext3 and ext2 as ext4. This will slightly improve performance, because certain new features of ext4 can also be used with ext3 and ext2, such as the new block allocation algorithm.
- ext3 is partially forward compatible with ext4. Practically, ext4 won't mount as an ext3 filesystem out of the box, unless certain new features are disabled when creating it, and those would be: ^extent,^flex_bg,^huge_file,^uninit_bg,^dir_nlink,^extra_isize as -O options of the mke2fs tool.[15]
- Persistent pre-allocation
- ext4 can pre-allocate on-disk space for a file. To do this on most file systems, zeros would be written to the file when created. In ext4 (and some other files systems such as XFS)
fallocate(), a new system call in the Linux kernel, can be used. The allocated space would be guaranteed and likely contiguous. This situation has applications for media streaming and databases. - Delayed allocation
- ext4 uses a performance technique called allocate-on-flush also known as delayed allocation. That is, ext4 delays block allocation until data is flushed to disk. (In contrast, some file systems allocate blocks immediately, even when the data goes into a write cache.) Delayed allocation improves performance and reduces fragmentation by effectively allocating larger amounts of data at a time.
- Unlimited number of subdirectories
- Ext4 allows an unlimited number of subdirectories. (In ext3 a directory can have at most 32,000 subdirectories.)[16] To allow for larger directories and continued performance, ext4 turns on HTree indexes (a specialized version of a B-tree) by default. This feature is implemented in Linux 2.6.23. In ext3 HTrees can be used by enabling the dir_index feature.
- Journal checksumming
- ext4 uses checksums in the journal to improve reliability, since the journal is one of the most used files of the disk. This feature has a side benefit: it can safely avoid a disk I/O wait during journaling, improving performance slightly. Journal checksumming was inspired by a research paper from the University of Wisconsin, titled IRON File Systems[17] (specifically, section 6, called "transaction checksums"), with modifications within the implementation of compound transactions performed by the IRON file system (originally proposed by Sam Naghshineh in the RedHat summit).
- Faster file system checking
- In ext4 unallocated block groups and sections of the inode table are marked as such. This enables e2fsck to skip them entirely and greatly reduces the time it takes to check the file system. Linux 2.6.24 implements this feature.
- Multiblock allocator
- When ext3 appends to a file, it calls the block allocator, once for each block. Consequently, if there are multiple concurrent writers, files can easily become fragmented on disk. However, ext4 uses delayed allocation which allows it to buffer data and allocate groups of blocks. Consequently the multiblock allocator can make better choices about allocating files contiguously on disk. The multiblock allocator can also be used when files are opened in O_DIRECT mode. This feature does not affect the disk format.
- Improved timestamps
- As computers become faster in general and as Linux becomes used more for mission-critical applications, the granularity of second-based timestamps becomes insufficient. To solve this, ext4 provides timestamps measured in nanoseconds. In addition, 2 bits of the expanded timestamp field are added to the most significant bits of the seconds field of the timestamps to defer the year 2038 problem for an additional 204 years.
- ext4 also adds support for date-created timestamps. But, as Theodore Ts'o points out, while it is easy to add an extra creation-date field in the inode (thus technically enabling support for date-created timestamps in ext4), it is more difficult to modify or add the necessary system calls, like stat() (which would probably require a new version) and the various libraries that depend on them (like glibc). These changes would require coordination of many projects. So even if ext4 developers implement initial support for creation-date timestamps, this feature will not be available to user programs for now.[18]
- Transparent encryption
- Support for transparent encryption was added in Linux kernel 4.1 on June 2015.[19]
Limitations
In 2008, the principal developer of the ext3 and ext4 file systems, Theodore Ts'o, stated that although ext4 has improved features, it is not a major advance, it uses old technology, and is a stop-gap. Ts'o believes that Btrfs is the better direction because "it offers improvements in scalability, reliability, and ease of management".[20] Btrfs also has "a number of the same design ideas that reiser3/4 had".[21]
The ext4 file system does not honor the "secure deletion" file attribute, which is supposed to cause overwriting of files upon deletion. A patch to implement secure deletion was proposed in 2011, but did not solve the problem of sensitive data ending up in the file system journal.[22]
Delayed allocation and potential data loss
Because delayed allocation changes the behavior that programmers have been relying on with ext3, the feature poses some additional risk of data loss in cases where the system crashes or loses power before all of the data has been written to disk. Due to this, ext4 in kernel versions 2.6.30 and later automatically handles these cases as ext3 does.
The typical scenario in which this might occur is a program replacing the contents of a file without forcing a write to the disk with fsync. There are two common ways of replacing the contents of a file on Unix systems:[23]
-
fd=open("file", O_TRUNC); write(fd, data); close(fd);
- In this case, an existing file is truncated at the time of open (due to O_TRUNC flag), then new data is written out. Since the write can take some time, there is an opportunity of losing contents even with ext3, but usually very small. However, because ext4 can delay writing file data for a long time, this opportunity is much greater.
- There are several problems that can arise:
- If the write does not succeed (which may be due to error conditions in the writing program, or due to external conditions such as a full disk), then both the original version and the new version of the file will be lost, and the file may be corrupted because only a part of it has been written.
- If other processes access the file while it is being written, they see a corrupted version.
- If other processes have the file open and do not expect its contents to change, those processes may crash. One notable example is a shared library file which is mapped into running programs.
- Because of these issues, often the following idiom is preferred over the one above:
-
fd=open("file.new"); write(fd, data); close(fd); rename("file.new", "file");
- A new temporary file ("file.new") is created, which initially contains the new contents. Then the new file is renamed over the old one. Replacing files by the "rename" call is guaranteed to be atomic by POSIX standards – i.e. either the old file remains, or it's overwritten with the new one. Because the ext3 default "ordered" journaling mode guarantees file data is written out on disk before metadata, this technique guarantees that either the old or the new file contents will persist on disk. ext4's delayed allocation breaks this expectation, because the file write can be delayed for a long time, and the rename is usually carried out before new file contents reach the disk.
Using fsync more often to reduce the risk for ext4 could lead to performance penalties on ext3 filesystems mounted with the data=ordered flag (the default on most Linux distributions). Given that both file systems will be in use for some time, this complicates matters for end-user application developers. In response, ext4 in Linux kernels 2.6.30 and newer detect the occurrence of these common cases and force the files to be allocated immediately. For a small cost in performance, this provides semantics similar to ext3 ordered mode and increases the chance that either version of the file will survive the crash. This new behavior is enabled by default, but can be disabled with the "noauto_da_alloc" mount option.[23]
The new patches have become part of the mainline kernel 2.6.30, but various distributions chose to backport them to 2.6.28 or 2.6.29. For instance, Ubuntu made them part of the 2.6.28 kernel in version 9.04 ("Jaunty Jackalope").[24]
These patches don't completely prevent potential data loss or help at all with new files. The only way to be safe is to write and use software that does fsync when it needs to. Performance problems can be minimized by limiting crucial disk writes that need fsync to occur less frequently.[25]
Implementation
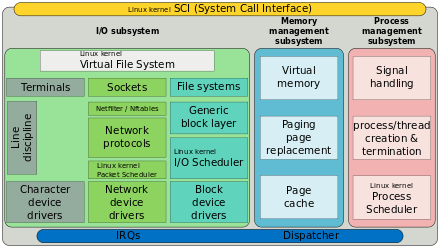
Linux kernel Virtual File System is a subsystem or layer inside of the Linux kernel. It is the result of the very serious attempt to integrate multiple file systems into an orderly single structure. The key idea - it dates back to the pioneering work done by Sun Microsystems employees in 1986.[26] - is to abstract out that part of the file system that is common to all file systems and put that code in a separate layer that calls the underlying concrete file systems to actually manage the data.
» All system calls related to files (or pseudo files!) are directed to the Linux kernel Virtual File System for initial processing. These calls, coming from user processes, are the standard POSIX calls, such as open, read, write, lseek, … .«
Compatibility with Windows and Macintosh
ext4 does not yet have as much support as ext2 and ext3 on non-Linux operating systems. ext2 and ext3 have stable drivers such as Ext2IFS, which are not yet available for ext4. It is possible to create compatible ext4 filesystems by disabling the extents feature, and sometimes specifying an inode size.[27] Another option for using ext4 in Windows is to use Ext2Fsd,[28] an open-source driver that supports writing in ext4 partitions with limited journaling. Viewing and copying files from ext4 to Windows, even with extents enabled, is also possible with the Ext2Read software.[29] More recently Paragon released its ExtFS for Windows which allows read/write capabilities for ext2/3/4.
Mac OS X has full ext2/3/4 read/write capability through the Paragon ExtFS[30] software, which is a commercial product. Free software such as ext4fuse has only read-only support with limited functionality.
See also
References
- 1 2 Previously, Linux used the same GUID for the data partitions as Windows (Basic data partition: EBD0A0A2-B9E5-4433-87C0-68B6B72699C7). Linux never had a separate unique partition type GUID defined for its data partitions. This created problems when dual-booting Linux and Windows in UEFI-GPT setup. The new GUID (Linux filesystem data: 0FC63DAF-8483-4772-8E79-3D69D8477DE4) was defined jointly by GPT fdisk and GNU Parted developers. It is identified as type code 0x8300 in GPT fdisk. (See definitions in gdisk's parttypes.cc)
- ↑ The Discoverable Partitions Specification
- 1 2 Mathur, Avantika; Cao, MingMing; Bhattacharya, Suparna; Dilger, Andreas; Tomas, Alex; Vivier, Laurent (2007). "The new ext4 filesystem: current status and future plans" (PDF). Proceedings of the Linux Symposium. Ottawa, ON, CA: Red Hat. Retrieved 2008-01-15.
- ↑ Torvalds, Linus (2006-06-09). "extents and 48bit ext3". Linux kernel mailing list.
- ↑ Ts'o, Theodore (2006-06-28). "Proposal and plan for ext2/3 future development work". Linux kernel mailing list.
- ↑ Leemhuis, Thorsten (2008-12-23). "Higher and further: The innovations of Linux 2.6.28 (page 2)". Heise Online. Retrieved 2010-01-09.
- ↑ "ext4: Rename ext4dev to ext4". Linus' kernel tree. Retrieved 2008-10-20.
- ↑ Leemhuis, Thorsten (2008-12-23). "Higher and further: The innovations of Linux 2.6.28". Heise Online.
- ↑ Paul, Ryan (2010-01-15). "Google upgrading to Ext4, hires former Linux Foundation CTO". Ars Technica.
- ↑ "Android 2.3 Gingerbread to use Ext4 file system". The H Open. 14 December 2010.
- ↑ "Migrating to Ext4". DeveloperWorks. IBM. Retrieved 2008-12-14.
- ↑ "The Ext4 File System". RedHat Enterprise Linux Performance Tuning Guide. RedHat. Archived from the original on February 22, 2014. Retrieved 2014-02-04.
- ↑ "EXT4 HowTo". Ext4 (and Ext2/Ext3) Wiki. EXT4 Team. Retrieved 2013-09-03.
- ↑ Hal Pomeranz (28 March 2011). "Understanding EXT4 (Part 3): Extent Trees". SANS Digital Forensics and Incident Response Blog.
- ↑ http://www.linuxquestions.org/questions/red-hat-31/mount-of-ext4-created-without-extents-as-ext3-fails-on-rh6-2-a-936813/
- ↑ http://kernelnewbies.org/Ext4
- ↑ Prabhakaran, Vijayan; et al. "IRON File Systems" (PDF). CS Dept, University of Wisconsin.
- ↑ Ts'o, Theodore (5 October 2006). "Re: creation time stamps for ext4 ?".
- ↑ Ts'o, Theodore (8 April 2015). "Ext4 encryption".
- ↑ Paul, Ryan (2009-04-14). "Panelists ponder the kernel at Linux Collaboration Summit". Ars Technica. Retrieved 2009-08-22
- ↑ Theodore Ts'o (2008-08-01). "Re: reiser4 for 2.6.27-rc1". linux-kernel (Mailing list). Retrieved 2010-12-31.
- ↑ Corbet, Jonathan (11 October 2011). "Securely deleting files from ext4 filesystems".
- 1 2 "ext4 documentation in Linux kernel source". 2009-03-28.
- ↑ Ubuntu bug #317781 Long discussion between Ubuntu developers and Theodore Ts'o on potential data loss
- ↑ Thoughts by Ted blog entry, March 12th, 2009 A blog posting of Theodore Ts'o on the subject
- ↑ Kleiman
- ↑ Description of Ext2Read and information on disabling extents for compatibility with Ext2Fsd
- ↑ "Ext2Fsd Project". Ext2fsd.com. Retrieved 2012-01-15.
- ↑ Description of Ext4 compatibility with Windows 7, November 1, 2009 Archived October 23, 2011, at the Wayback Machine.
- ↑
External links
- Theodore Ts'o's discussion on ext4, 29 June 2006
- First benchmarks of ext4, 21 Oct 2006
- "ext4 online defragmentation" (materials from Ottawa Linux Symposium 2007)
- "The new ext4 filesystem: current status and future plans" (materials from Ottawa Linux Symposium 2007)
- Kernel Log: Ext4 completes development phase as interim step to btrfs, 17 October 2008
- "Ext4 block and inode allocator improvements" (materials from Ottawa Linux Symposium 2008)
- “Ext4: The Next Generation of Ext2/3 Filesystem”
- Ext4 (and Ext2/Ext3) Wiki
- Ext4 wiki at kernelnewbies.org
- Native Windows port of Ext4 and other FS in CROSSMETA
- Ext2read A windows application to read/copy ext2/ext3/ext4 files with extent and LVM2 support.
- Ext2Fsd Open source ext2/ext3/ext4 read/write file system driver for Windows. ext4 is supported from version 0.50 onwards
- Ext4fuse Open source read-only ext4 driver for FUSE. (Supports Mac OS X 10.5 and later, using MacFuse)