Holland's schema theorem
Holland's schema theorem, also called the fundamental theorem of genetic algorithms,[1] is widely taken to be the foundation for explanations of the power of genetic algorithms. It says that short, low-order schemata with above-average fitness increase exponentially in successive generations. The theorem was proposed by John Holland in the 1970s.
A schema is a template that identifies a subset of strings with similarities at certain string positions. Schemata are a special case of cylinder sets, and hence form a topological space.
Description
For example, consider binary strings of length 6. The schema 1*10*1 describes the set of all strings of length 6 with 1's at positions 1, 3 and 6 and a 0 at position 4. The * is a wildcard symbol, which means that positions 2 and 5 can have a value of either 1 or 0. The order of a schema is defined as the number of fixed positions in the template, while the defining length is the distance between the first and last specific positions. The order of 1*10*1 is 4 and its defining length is 5. The fitness of a schema is the average fitness of all strings matching the schema. The fitness of a string is a measure of the value of the encoded problem solution, as computed by a problem-specific evaluation function. Using the established methods and genetic operators of genetic algorithms, the schema theorem states that short, low-order schemata with above-average fitness increase exponentially in successive generations. Expressed as an equation:


![\operatorname {E}(m(H,t+1))\geq {m(H,t)f(H) \over a_{t}}[1-p].](../I/m/37ac2d707cc2a474ad365dd53141be94ecad43de.svg)
Here is the number of strings belonging to schema at generation , is the observed average fitness of schema and is the observed average fitness at generation . The probability of disruption is the probability that crossover or mutation will destroy the schema . It can be expressed as:







where is the order of the schema, is the length of the code, is the probability of mutation and is the probability of crossover. So a schema with a shorter defining length is less likely to be disrupted.
An often misunderstood point is why the Schema Theorem is an inequality rather than an equality. The answer is in fact simple: the Theorem neglects the small, yet non-zero, probability that a string belonging to the schema will be created "from scratch" by mutation of a single string (or recombination of two strings) that did not belong to in the previous generation.



Limitation
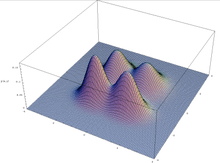
The schema theorem holds under the assumption of a genetic algorithm that maintains an infinitely large population, but does not always carry over to (finite) practice: due to sampling error in the initial population, genetic algorithms may converge on schemata that have no selective advantage. This happens in particular in multimodal optimization, where a function can have multiple peaks: the population may drift to prefer one of the peaks, ignoring the others.[2]
References
- ↑ Bridges, Clayton L.; Goldberg, David E. (1987). An analysis of reproduction and crossover in a binary-coded genetic algorithm. 2nd Int'l Conf. on Genetic Algorithms and their applications.
- ↑ David E., Goldberg; Richardson, Jon (1987). Genetic algorithms with sharing for multimodal function optimization. 2nd Int'l Conf. on Genetic Algorithms and their applications.
- J. Holland, Adaptation in Natural and Artificial Systems, The MIT Press; Reprint edition 1992 (originally published in 1975).
- J. Holland, Hidden Order: How Adaptation Builds Complexity, Helix Books; 1996.