Instruction pipelining
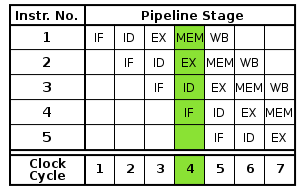
Instruction pipelining is a technique that implements a form of parallelism called instruction-level parallelism within a single processor. It therefore allows faster CPU throughput (the number of instructions that can be executed in a unit of time) than would otherwise be possible at a given clock rate. The basic instruction cycle is broken up into a series called a pipeline. Rather than processing each instruction sequentially (finishing one instruction before starting the next), each instruction is split up into a sequence of steps so different steps can be executed in parallel and instructions can be processed concurrently (starting one instruction before finishing the previous one).
Pipelining increases instruction throughput by performing multiple operations at the same time, but does not reduce instruction latency, which is the time to complete a single instruction from start to finish, as it still must go through all steps. Indeed, it may increase latency due to additional overhead from breaking the computation into separate steps and worse, the pipeline may stall (or even need to be flushed), further increasing the latency. Thus, pipelining increases throughput at the cost of latency, and is frequently used in CPUs but avoided in real-time systems, in which latency is a hard constraint.
Each instruction is split into a sequence of dependent steps. The first step is always to fetch the instruction from memory; the final step is usually writing the results of the instruction to processor registers or to memory. Pipelining seeks to let the processor work on as many instructions as there are dependent steps, just as an assembly line builds many vehicles at once, rather than waiting until one vehicle has passed through the line before admitting the next one. Just as the goal of the assembly line is to keep each assembler productive at all times, pipelining seeks to keep every portion of the processor busy with some instruction. Pipelining lets the computer's cycle time be the time of the slowest step, and ideally lets one instruction complete in every cycle.
The term pipeline is an analogy to the fact that there is fluid in each link of a pipeline, as each part of the processor is occupied with work.
Introduction
Central processing units (CPUs) are driven by a clock. Each clock pulse need not do the same thing; rather, logic in the CPU directs successive pulses to different places to perform a useful sequence. There are many reasons that the entire execution of a machine instruction cannot happen at once; in pipelining, effects that cannot happen at the same time are made into dependent steps of the instruction.
For example, if one clock pulse latches a value into a register or begins a calculation, it will take some time for the value to be stable at the outputs of the register or for the calculation to complete. As another example, reading an instruction out of a memory unit cannot be done at the same time that an instruction writes a result to the same memory unit.
Number of steps
The number of dependent steps varies with the machine architecture. For example:
- The IBM Stretch project proposed the terms Fetch, Decode, and Execute that have become common.
- The classic RISC pipeline comprises:
- Instruction fetch
- Instruction decode and register fetch
- Execute
- Memory access
- Register write back
- The Atmel AVR and the PIC microcontroller each have a two-stage pipeline.
- Many designs include pipelines as long as 7, 10 and even 20 stages (as in the Intel Pentium 4).
- The later "Prescott" and "Cedar Mill" Netburst cores from Intel, used in the latest Pentium 4 models and their Pentium D and Xeon derivatives, have a long 31-stage pipeline.
- The Xelerated X10q Network Processor has a pipeline more than a thousand stages long.[1]
As the pipeline is made "deeper" (with a greater number of dependent steps), a given step can be implemented with simpler circuitry, which may let the processor clock run faster.[2] Such pipelines may be called superpipelines.[3]
A processor is said to be fully pipelined if it can fetch an instruction on every cycle. Thus, if some instructions or conditions require delays that inhibit fetching new instructions, the processor is not fully pipelined.
Hazards
The model of sequential execution assumes that each instruction completes before the next one begins; this assumption is not true on a pipelined processor. A situation where the expected result is problematic is known as a hazard. Imagine the following two register instructions to a hypothetical RISC processor:
1: add 1 to R5 2: copy R5 to R6
If the processor has the 5 steps listed in the initial illustration, instruction 1 would be fetched at time t1 and its execution would be complete at t5. Instruction 2 would be fetched at t2 and would be complete at t6. The first instruction might deposit the incremented number into R5 as its fifth step (register write back) at t5. But the second instruction might get the number from R5 (to copy to R6) in its second step (instruction decode and register fetch) at time t3. It seems that the first instruction would not have incremented the value by then. The above code invokes a hazard.
Writing computer programs in a compiled language might not raise these concerns, as the compiler could be designed to generate machine code that avoids hazards.
Workarounds
In some early DSP and RISC processors, the documentation advises programmers to avoid such dependencies in adjacent and nearly adjacent instructions (called delay slots), or declares that the second instruction uses an old value rather than the desired value (in the example above, the processor might counter-intuitively copy the unincremented value), or declares that the value it uses is undefined. The programmer may have unrelated work that the processor can do in the meantime; or, to ensure correct results, the programmer may insert NOPs into the code, partly negating the advantages of pipelining.
Solutions
Pipelined processors commonly use three techniques to work as expected when the programmer assumes that each instruction completes before the next one begins:
- Processors that can compute the presence of a hazard may stall, delaying processing of the second instruction (and subsequent instructions) until the values it requires as input are ready. This creates a bubble in the pipeline (see below), also partly negating the advantages of pipelining.
- Some processors can not only compute the presence of a hazard but can compensate by having additional data paths that provide needed inputs to a computation step before a subsequent instruction would otherwise compute them, an attribute called operand forwarding.[4][5]
- Some processors can determine that instructions other than the next sequential one are not dependent on the current ones and can be executed without hazards. Such processors may perform out-of-order execution.
Branches
A branch out of the normal instruction sequence often involves a hazard. Unless the processor can give effect to the branch in a single time cycle, the pipeline will continue fetching instructions sequentially. Such instructions cannot be allowed to take effect because the programmer has diverted control to another part of the program.
A conditional branch is even more problematic. The processor may or may not branch, depending on a calculation that has not yet occurred. Various processors may stall, may attempt branch prediction, and may be able to begin to execute two different program sequences (eager execution), both assuming the branch is and is not taken, discarding all work that pertains to the incorrect guess.[lower-alpha 1]
A processor with an implementation of branch prediction that usually makes correct predictions can minimize the performance penalty from branching. However, if branches are predicted poorly, it may create more work for the processor, such as flushing from the pipeline the incorrect code path that has begun execution before resuming execution at the correct location.
Programs written for a pipelined processor deliberately avoid branching to minimize possible loss of speed. For example, the programmer can handle the usual case with sequential execution and branch only on detecting unusual cases. Using programs such as gcov to analyze code coverage lets the programmer measure how often particular branches are actually executed and gain insight with which to optimize the code.
Special situations
- Self-modifying programs
- The technique of self-modifying code can be problematic on a pipelined processor. In this technique, one of the effects of a program is to modify its own upcoming instructions. If the processor has an instruction cache, the original instruction may already have been copied into a prefetch input queue and the modification will not take effect.
- Uninterruptible instructions
- An instruction may be uninterruptible to ensure its atomicity, such as when it swaps two items. A sequential processor permits interrupts between instructions, but a pipelining processor overlaps instructions, so executing an uninterruptible instruction renders portions of ordinary instructions uninterruptible too. The Cyrix coma bug would hang a single-core system using an infinite loop in which an uninterruptible instruction was always in the pipeline.
Design considerations
- Speed
- Pipelining keeps all portions of the processor occupied and increases the amount of useful work the processor can do in a given time. Pipelining typically reduces the processor's cycle time and increases the throughput of instructions. The speed advantage is diminished to the extent that execution encounters hazards that require execution to slow below its ideal rate. A non-pipelined processor executes only a single instruction at a time. The start of the next instruction is delayed not based on hazards but unconditionally.
- A pipelined processor's need to organize all its work into modular steps may require the duplication of registers that increases the latency of some instructions.
- Economy
- By making each dependent step simpler, pipelining can enable complex operations more economically than adding complex circuitry, such as for numerical calculations. However, a processor that declines to pursue increased speed with pipelining may be simpler and cheaper to manufacture.
- Predictability
- Compared to environments where the programmer needs to avoid or work around hazards, use of a non-pipelined processor may make it easier to program and to train programmers. The non-pipelined processor also makes it easier to predict the exact timing of a given sequence of instructions.
Illustrated example

To the right is a generic pipeline with four stages: fetch, decode, execute and write-back. The top gray box is the list of instructions waiting to be executed, the bottom gray box is the list of instructions that have had their execution completed, and the middle white box is the pipeline.
The execution is as follows:
| Time | Execution |
|---|---|
| 0 | Four instructions are waiting to be executed |
| 1 |
|
| 2 |
|
| 3 |
|
| 4 |
|
| 5 |
|
| 6 |
|
| 7 |
|
| 8 |
|
| 9 | The execution of all four instructions is completed |
Pipeline bubble

A pipelined processor may deal with hazards by stalling and creating a bubble in the pipeline, resulting in one or more cycles in which nothing useful happens.
In the illustration at right, in cycle 3, the processor cannot decode the purple instruction, perhaps because the processor determines that decoding depends on results produced by the execution of the green instruction. The green instruction can proceed to the Execute stage and then to the Write-back stage as scheduled, but the purple instruction is stalled for one cycle at the Fetch stage. The blue instruction, which was due to be fetched during cycle 3, is stalled for one cycle, as is the red instruction after it.
Because of the bubble (the blue ovals in the illustration), the processor's Decode circuitry is idle during cycle 3. Its Execute circuitry is idle during cycle 4 and its Write-back circuitry is idle during cycle 5.
When the bubble moves out of the pipeline (at cycle 6), normal execution resumes. But everything now is one cycle late. It will take 8 cycles (cycle 1 through 8) rather than 7 to completely execute the four instructions shown in colors.
History
Seminal uses of pipelining were in the ILLIAC II project and the IBM Stretch project, though a simple version was used earlier in the Z1 in 1939 and the Z3 in 1941.[6]
Pipelining began in earnest in the late 1970s in supercomputers such as vector processors and array processors. One of the early supercomputers was the Cyber series built by Control Data Corporation. Its main architect, Seymour Cray, later headed Cray Research. Cray developed the XMP line of supercomputers, using pipelining for both multiply and add/subtract functions. Later, Star Technologies added parallelism (several pipelined functions working in parallel), developed by Roger Chen. In 1984, Star Technologies added the pipelined divide circuit developed by James Bradley. By the mid 1980s, supercomputing was used by many different companies around the world.
Today, pipelining and most of the above innovations are implemented by the instruction unit of most microprocessors.
See also
Notes
- ↑ Early pipelined processors without any of these heuristics, such as the PA-RISC processor of Hewlett-Packard, dealt with hazards by simply warning the programmer; in this case, that one or more instructions following the branch would be executed whether or not the branch was taken. This could be useful; for instance, after computing a number in a register, a conditional branch could be followed by loading into the register a value more useful to subsequent computations in both the branch and the non-branch case.
References
- ↑ "Best Extreme Processor: Xelerated X10q". The Linley Group. Retrieved 2014-02-08.
- ↑ John Paul Shen, Mikko H. Lipasti (2004). Modern Processor Design. McGraw-Hill Professional.
- ↑ Sunggu Lee (2000). Design of Computers and Other Complex Digital Devices. Prentice Hall.
- ↑ "CMSC 411 Lecture 19, Pipelining Data Forwarding". Csee.umbc.edu. Retrieved 2014-02-08.
- ↑ "High performance computing, Notes of class 11". hpc.serc.iisc.ernet.in. September 2000. Retrieved 2014-02-08.
- ↑ Raul Rojas (1997). "Konrad Zuse's Legacy: The Architecture of the Z1 and Z3". IEEE Annals of the History of Computing. 19 (2).
External links
| Wikimedia Commons has media related to Pipeline (computer hardware). |
| Wikibooks has a book on the topic of: Microprocessor Design/Pipelined Processors |
- Branch Prediction in the Pentium Family (Archive.org copy)
- ArsTechnica article on pipelining
- Counterflow Pipeline Processor Architecture