Single point of failure
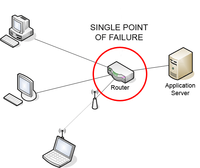
A single point of failure (SPOF) is a part of a system that, if it fails, will stop the entire system from working.[1] SPOFs are undesirable in any system with a goal of high availability or reliability, be it a business practice, software application, or other industrial system.
Overview
Systems can be made robust by adding redundancy in all potential SPOFs. For instance, the owner of a small tree care company may only own one wood chipper. If the chipper breaks, he may be unable to complete his current job and may have to cancel future jobs until he can obtain a replacement.
Redundancy can be achieved at various levels. For instance, the owner of the tree care company may have spare parts ready for the repair of the wood chipper, in case it fails. At a higher level, he may have a second wood chipper that he can bring to the job site. Finally, at the highest level, he may have enough equipment available to completely replace everything at the work site in the case of multiple failures.
The assessment of a potential SPOF involves identifying the critical components of a complex system that would provoke a total systems failure in case of malfunction. Highly reliable systems should not rely on any such individual component.
-
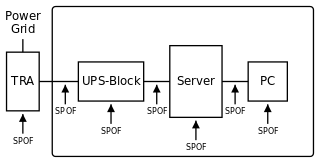
Possible SPOFs in a simple setup.
-
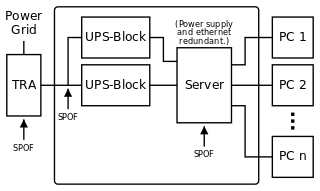
Using redundancy to avoid some SPOFs.
-
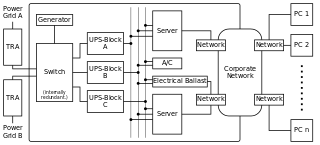
Completely redundant system without SPOFs.(Note: Assumes Generator and Grid sources are each rated at N, Each UPS is rated at N and "A/C" and "Electrical" are in themselves completely fault tolerant systems.
Computing
In computing, redundancy can be achieved at the internal component level, at the system level (multiple machines), or site level (replication).
One would normally deploy a load balancer to ensure high availability for a server cluster at the system level.
In a high-availability server cluster, each individual server may attain internal component redundancy by having multiple power supplies, hard drives, and other components. System level redundancy could be obtained by having spare servers waiting to take on the work of another server if it fails.
Since a data center is often a support center for other operations such as business logic, it represents a potential SPOF in itself. Thus, at the site level, the entire cluster may be replicated at another location, where it can be accessed in case the primary location becomes unavailable. This is typically addressed as part of an IT disaster recovery (resiliency) program.
Paul Baran and Donald Davies developed packet switching, a key part of "survivable communications networks". Such networks – including ARPANET and the Internet – are designed to have no single point of failure. Multiple paths between any two points on the network allow those points to continue communicating with each other, the packets "routing around" damage, even after any single failure of any one particular path or any one intermediate node.
Network protocols used to prevent SPOF:
in Software engineering
In software engineering, a bottleneck occurs when the capacity of an application or a computer system is severely limited by a single component. The bottleneck has lowest throughput of all parts of the transaction path.
in Performance engineering
Tracking down bottlenecks (sometimes known as "hot spots" - sections of the code that execute most frequently - i.e. have the highest execution count) is called performance analysis. Reduction is usually achieved with the help of specialized tools, known as performance analyzers or profilers. The objective being to make those particular sections of code perform as fast as possible to improve overall algorithmic efficiency.
In Computer security
A mistake in just one component can compromise the entire system.
Other fields
The concept of a single point of failure has also been applied to fields outside of engineering, computers, and networking, such as corporate supply chain management.[2]
Design structures that create single points of failure include bottlenecks and series circuits (in contrast to parallel circuits).
The concept of a single point of failure has also been applied to the fields of Intelligence. Edward Snowden talked of the dangers of being what he described as "the single point of failure" – the sole repository of information. [3]
See also
Concepts |
Applications |
In literature |
References
- ↑ 1: Designing Large-scale LANs – Page 31, K. Dooley, O'Reilly, 2002
- ↑ Gary S. Lynch (Oct 7, 2009). Single Point of Failure: The 10 Essential Laws of Supply Chain Risk Management. Wiley. ISBN 978-0-470-42496-4.
- ↑ http://www.telegraph.co.uk/culture/film/11185627/Edward-Snowden-the-true-story-behind-his-NSA-leaks.html