Thread pool
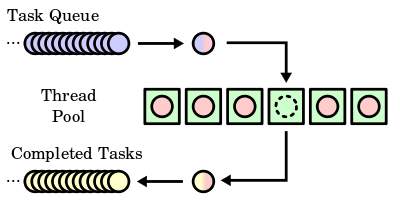
In computer programming, a thread pool pattern (also replicated workers or worker-crew model)[1] consists of a number m of threads, created to perform a number n of tasks concurrently. Typically m is not equal to n; instead, the number of threads is tuned to the computing resources available to handle tasks in parallel (processors, cores, memory) while the number of tasks depends on the problem and may not be known upfront.
Reasons for using a thread pool, rather than the obvious alternative of spawning one thread per task, are to prevent the time and memory overhead inherent in thread creation,[2] and to avoid running out of resources such as open files or network connections (of which operating systems allocate a limited number to running programs).[3] A common way of distributing the tasks to threads (scheduling the tasks for execution) is by means of a synchronized queue known as a task queue. The threads in the pool take tasks off the queue, perform them, then return to the queue for their next task.
Overview
Pool size
The number of threads used is a parameter that can be tuned to provide the best performance.[4]
A major advantage of using a thread pool over creating a new thread for each task is that thread creation and destruction overhead is negated, which may result in better performance and better system stability. Creating and destroying a thread and its associated resources is an expensive process in terms of time. An excessive number of threads will also waste memory, and context-switching between the runnable threads also damages performance. For example, a socket connection to another machine—which might take thousands (or even millions) of cycles to drop and re-establish—can be avoided by associating it with a thread which lives over the course of more than one transaction.
Typically, a thread pool executes on a single computer. However, thread pools are conceptually related to server farms in which a master process, which might be a thread pool itself, distributes tasks to worker processes on different computers, in order to increase the overall throughput. Embarrassingly parallel problems are highly amenable to this approach.
Dynamically changing the pool size
Additionally, the number of threads can be dynamic based on the number of waiting tasks. For example, a web server can add threads if numerous web page requests come in and can remove threads when those requests taper down. The cost of having a larger thread pool is increased resource usage. The algorithm used to determine when to create or destroy threads will affect the overall performance:
- create too many threads, and resources are wasted and time also wasted creating any unused threads
- destroy too many threads and more time will be spent later creating them again
- creating threads too slowly might result in poor client performance (long wait times)
- destroying threads too slowly may starve other processes of resources
The algorithm chosen will depend on the problem and the expected usage patterns.
See also
- Object pool pattern
- Concurrency pattern
- Grand Central Dispatch
- Parallel Extensions for the .NET Framework
- Parallelization
- Server farm
- Staged event-driven architecture
References
- ↑ Garg, Rajat P. & Sharapov, Ilya Techniques for Optimizing Applications - High Performance Computing Prentice-Hall 2002, p. 394
- ↑ Holub, Allen (2000). Taming Java Threads. Apress. p. 209.
- ↑ Makofske, David B.; Donahoo, Michael J.; Calvert, Kenneth L. (2004). TCP/IP Sockets in C#: Practical Guide for Programmers. Academic Press. p. 112.
- ↑ Yibei Ling; Tracy Mullen; Xiaola Lin (April 2000). "Analysis of optimal thread pool size". ACM SIGOPS Operating Systems Review. 34 (2): 42–55.
External links
- "Query by Slice, Parallel Execute, and Join: A Thread Pool Pattern in Java" by Binildas C. A.
- "Thread pools and work queues" by Brian Goetz
- "A Method of Worker Thread Pooling" by Pradeep Kumar Sahu
- "Work Queue" by Uri Twig: C++ code demonstration of pooled threads executing a work queue.
- "Windows Thread Pooling and Execution Chaining"
- "Smart Thread Pool" by Ami Bar
- "Programming the Thread Pool in the .NET Framework" by David Carmona
- "The Thread Pool and Asynchronous Methods" by Jon Skeet
- "Creating a Notifying Blocking Thread Pool in Java" by Amir Kirsh
- "Practical Threaded Programming with Python: Thread Pools and Queues" by Noah Gift
- "Optimizing Thread-Pool Strategies for Real-Time CORBA" by Irfan Pyarali, Marina Spivak, Douglas C. Schmidt and Ron Cytron
- Conference Paper "Deferred cancellation. A behavioral pattern" by Philipp Bachmann