S-comma
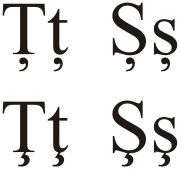
S-comma (majuscule: Ș, minuscule: ș) is a letter which is part of the Romanian alphabet, used to represent the sound /ʃ/, the voiceless postalveolar fricative (like sh in shoe).
History


The letter was proposed in the Buda Lexicon, a book published in 1825, which included two texts by Petru Maior, Orthographia romana sive latino-valachica una cum clavi and Dialogu pentru inceputul linbei române, introducing ș for /ʃ/ and ț for /ts/.[1]
Unicode support
This letter however was not part of the early Unicode versions, and not in the predecessors like ISO/IEC 8859-2 and Windows-1250, which is why Ş (S-cedilla) is often used in digital texts in Romanian. S-cedilla was introduced in ISO/IEC 8859-2 for computers for the sake of the Romanian language. It was less of a problem then, since the screens and printouts had less resolution and newspapers and books would use a suitable font anyway.
S-comma was introduced only in Unicode 3.0 at the request of the Romanian national standardization body. Computers with Microsoft operating systems older than Windows XP do not have compatible fonts. Windows XP does not support this letter out of the box, but it is possible to install European Union Expansion Font Update which add support for this letter. For this reason, almost all Romanian texts still use S-cedilla (or even S), despite the recommendation to migrate from cedilla to comma.
The letter is placed in Unicode in the Latin Extended-B range, under "Additions for Romanian", as the "Latin capital letter S with comma below" (U+0218) and "Latin small letter s with comma below" (U+0219).[2] In HTML these can be encoded by Ș and ș, respectively.
Use of the comma with the letter S
| Ș ș | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S-comma | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||
- Romanian
- The Romanian letter Ș/ș (S with comma) represents the voiceless postalveolar fricative /ʃ/ (as in "show"). On outdated systems which do not support the glyph, the symbol Ş/ş (S with cedilla) is used. Example word: Timișoara.
See also
References
- ↑ Marinella Lörinczi Angioni, "Coscienza nazionale romanza e ortografia: il romeno tra alfabeto cirillico e alfabeto latino ", La Ricerca Folklorica, No. 5, La scrittura: funzioni e ideologie. (Apr., 1982), pp. 75–85.
- ↑ Unicode code charts. Latin Extended-B: Range 0180–024F