Complement component 4
| complement component 4A (Rodgers blood group) | |
|---|---|
| Identifiers | |
| Symbol | C4A |
| Entrez | 720 |
| HUGO | 1323 |
| OMIM | 120810 |
| RefSeq | NM_007293 |
| UniProt | P0C0L4 |
| Other data | |
| Locus | Chr. 6 p21.3 |
| complement component 4B (Chido blood group) | |
|---|---|
| Identifiers | |
| Symbol | C4B |
| Entrez | 721 |
| HUGO | 1324 |
| OMIM | 120820 |
| RefSeq | NM_000592 |
| UniProt | P0C0L5 |
| Other data | |
| Locus | Chr. 6 p21.3 |
Complement component 4 (C4), in humans, is a protein involved in the intricate complement system, originating from the human leukocyte antigen (HLA) system. It serves a number of critical functions in immunity, tolerance, and autoimmunity with the other numerous components. Furthermore, it is a crucial factor in connecting the recognition pathways of the overall system instigated by antibody-antigen (Ab-Ag) complexes to the other effector proteins of the innate immune response. For example, the severity of a dysfunctional complement system can lead to fatal diseases and infections. Complex variations of it can also lead to schizophrenia.[1] Yet, the C4 protein derives from a simple two-locus allelic model, the C4A-C4B genes, that allows for an abundant variation in the levels of their respective proteins within a population.[1] Originally defined in the context of the Chido/Rodgers blood group system, the C4A-C4B genetic model is under investigation for its possible role in schizophrenia risk and development.
History
One of the earlier genetic studies on the C4 protein identified two different groups, found within a human serum, called the Chido/Rogers (Ch/Rg) blood groups. O’Neill et al. have demonstrated that two different C4 loci express the different Ch/Rg antigens on the membranes of erythrocytes.[2] More specifically, the two proteins, Ch and Rg, function together as a medium for interaction between the Ab-Ag complex and other complement components.[3] Moreover, the two loci are linked to the HLA, or the human analog of the major histocompatibility complex (MHC) on the short arm of chromosome 6, whereas previously they were believed to have been expressed by two codominant alleles at a single locus.[2][4] In gel electrophoresis studies, O’Neill et al. have identified two genetic variants: F, signifying the presence (F+) or absence (f0/ f0) of four fast moving bands, and S, signifying the presence (S+) or absence (s0/ s0) of four slow moving bands.[2] The homogeneity or heterogeneity of the two loci, with the addition of these null (f0, s0) genes, allow for duplication/non-duplication of the C4 loci.[5] Therefore, having separate loci for C4, C4F and C4S (later identified as C4A or C4B, respectively), possibly account for producing multiple allelic forms, leading to the great size and copy number variation.
Two important contributors, Carroll and Porter, in their study of cloning the human C4 gene, which consists of 3 subparts (α, β, and γ subunits), showed that all six of their clones contained the same C4 gene.[6] Regarding the subunits, the α-, β-, and γ-chains were before found to have molecular weights (MWs) of ~95,000, 78,000, and 31,000, respectively, all joined by interchain disulfide bridges.[6][7][8][9] In a study by Roos et al., the α-chains between the C4A and C4B were found to be slightly different (MW of ~96,000 and 94,000, respectively), proving that there is actually a structural difference between the two variants.[8] Moreover, they implicated that a lack of C4 activity could be attributed to the structural differences between the α-chains.[8] Nevertheless, Carroll and Porter demonstrated that there is a 1,500-bp region that acts as an intron in the genomic sequence, which they believed to be the known C4d region, a byproduct of C4 activity.[6] Carroll et al. later published work that characterized the structure and organization of the C4 genes, which are situated in the HLA class III region and linked with C2 and factor B on the chromosome.[10] Through experiments involving restriction mapping, nucleotide sequence analysis, and hybridization with C4A and C4B, they found that the genes are actually fairly similar though they have their differences.[10] For example, single nucleotide polymorphisms were detected, which allowed them to be class differences between C4A and C4B.[10] Furthermore, class and allelic differences would affect the performance of the C4 proteins with the immune complex.[10] Finally, by overlapping cDNA cloned fragments, they were able to determine that the C4 loci, an estimated 16 kilobase (kb) long, are spaced by 10 kb and aligned 30 kb from the factor B locus.[9][10]
In the same year, studies relatedly identified a 98 kb region of the chromosome the four class III genes (that express C4A, C4B, C2, and factor B) are closely linked, which does not allow for cross-overs to occur.[9] Using protein variants visualized by electrophoresis, the four structural genes were located between HLA-B and HLA-D.[9] More specifically, they verified the proposed molecular map in which the gene order went from factor B, C4B, C4A, and C2 with C2 nearest to HLA-B.[9] In another study, Law et al. then continued to delve deeper, this time comparing the properties of both the C4A and C4B, both of which are substantial players in the human immunity system.[11] Through methods that include incubation, different pH levels, and treatment with methylamine, they had biochemically illustrated the different reactivities of the C4 genes.[11] More specifically, the C4B has shown to react much more efficiently and effectively despite the 7 kb difference between C4A and C4B. In whole serum, C4B alleles performed at a rate several fold greater during hemolytic activity, in direct comparison with C4A alleles.[11] Biochemically, they also found that C4A reacted more steadily with an antibody’s amino acid side chains and antigens that are amino groups, while C4B reacted better with carbohydrate hydroxyl groups.[11] Thus, upon analysis of the varying reactivities, they proposed that the exceptional polymorphism of C4 genes may bring about some biological advantages (i.e. complement activation with a more extensive range of Ab-Ag complexes formed upon infections).[11] Though interestingly, at this point in time, the genomic and derived amino acid sequence of either C4A or C4B had yet to be determined.
Structure
The early studies vastly expanded the knowledge of the C4 complex, laying down the foundations that paved the way to discovering the gene and protein structures. C. Yu successfully determined the complete sequence of the human complement component C4A gene.[3] In the findings, the whole genome was found to have of 41 exons, with a total of 1744 residues (despite avoiding the sequence of a large Intron 9).[3] The C4 protein is synthesized into a single chain precursor, which then undergoes proteolytic cleavage into three chains (in order of how they are chained, β-α-γ).[3]
The β-chain consists of 656 residues, coded by exons 1-16.[3] The most prominent aspect of the β-chain is the presence of a large intron, ranging from six to seven kilobases in size.[3] It is present in the first locus (coding for C4A) for all C4 genes and in the second locus (coding for C4B) only in a few C4 genes.[3] The α-chain consists of residues 661-1428, encoding exons 16-33.[3] Within this chain, two cleavage sites marked by exons 23 and 30 produces the C4d fragment (where the thioester, Ch/Rg antigens, and isotypic residues are located); moreover, most of the polymorphic sites cluster in this region.[3] The γ-chain consists of 291 residues, encoding exons 33-41.[3] Unfortunately, no specific function has been attributed to the γ-chain.[3]
The study completed by Vaishnaw et al. sought to identify the key region and factors related to the efforts of gene expression of the C4 gene.[12] Their research concluded with the fact that the Sp1 binding site (positioned at -59 to -49) plays an important role in accurately starting basal transcription of C4.[12] Utilization of electromobility shift assays and DNase I footprint analyses demonstrated specific DNA-protein correlations of the C4 promoter at the nuclear factor 1, two E box (-98 to -93 and -78 to -73), and Sp1 binding domains.[12] These findings were later added to in another extensive study, that found a third E box site.[13] In addition, the same findings postulated that two physical entities within the gene sequence could have a role in the expression levels of human C4A and C4B, which include the both presence of the endogenous retrovirus that can have positive or negative regulatory influences affecting C4 transcription and the varying genetic environment (dependent on which genetic modular component is present) past position -1524.[13]
To provide more context, in the latter study, the previously noted bimodular structure (C4A-C4B) has been updated to a quadrimodular structure of one to four discrete segments, containing one or more RP-C4-CYP21-TNX (RCCX) modules.[1] The size of either C4A or C4B gene can be 21 kb (long, L) or 14.6 kb (short, S). Also, the long C4 gene uniquely contains a retrovirus HERV-K(C4) in its intron 9 that imposes transcription of an extra 6.36 kb, hence the “longer” string of gene.[1][13] Thus, C4 genes have a complex pattern of variation in gene size, copy number, and polymorphisms.[1][13] Examples of these mono-, bi-, tri-, and quadri-modular structures include: L or S (monomodular with one long or short C4 gene), LL or LS or SS (bimodular with a combination of homozygous or heterozygous L or S genes), LLL or LLS or LSS (trimodular RCCX with three L or S C4 genes), LLLL (quadrimodular structure with four L or S C4 genes).[13] Interestingly, not all the structural groups have the same percentage of appearance, possibly even further differences within separate ethnic groups. For example, the Caucasian population studied showed 69% bimodular configuration (C4A-C4B, C4A-C4A, or C4B-C4B) and 31% trimodular configuration (equally split between LLL as C4A-C4A-C4B or LSS as C4A-C4B-C4B).[13] Regarding C4 protein sequence polymorphism, a total of 24 polymorphic residues were found. Among them, the β-chain expressed of five, as the α-chain and γ-chain produced 18 and one, respectively. These polymorphisms can be further categorized into groups: 1) four isotypic residues at specific positions, 2) Ch/Rg antigenic determinants at specific positions, 3) C5 binding sites, 4) private allelic residues.[13]
Additionally, the same study identified the expression of human complement C4 transcripts in multiple tissues. The results of a Northern blot analysis, using a C4d probe and RD probe as positive control, showed that the liver contains the majority of transcripts throughout the body.[13] Even so, moderate quantities were expressed in adrenal cortices/medulla, thyroid, and kidney.[13]
Function and mechanism
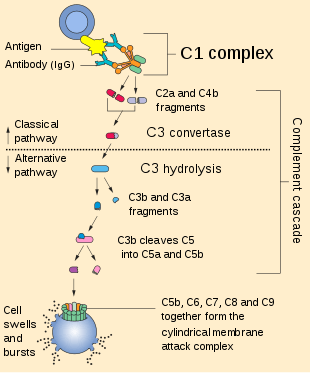
As noted, C4 (mixture of C4A and C4B) participates in all three of the complement pathways (classical, alternative, and lectin); the alternative pathway is "triggered spontaneously," while the classical and alternative pathways are elicited in response to the recognition of particular microbes.[15] All three pathways converge at a step in which compliment protein C3 is cleaved into proteins C3a and C3b, which results in a lytic pathway and formation of a macromolecular assembly of multiple proteins, termed the membrane-attack complex (MAC), which serves as a pore in the membrane of the targeted pathogen, leading to invading cell disruption and eventual lysis.[15]
In the classical pathway, the complement component—hereafter abbreviated by the "C" preceding the protein number— termed C1s, a serine protease, is activated by upstream steps of the pathway, resulting in its cleavage of the native, parent ~200 kilodalton (kDa) C4 protein—composed of three chains.[15]:288 The C4 is cleaved by the protease into two parts, a peptide C4a (small at ~9 kDa, and anaphylotoxic), and the higher molecular weight protein C4b, at about 190 kDa.[16] The cleavage of the C4 results in C4b bearing a thioester functional group [-S-C(O)-]: work in the 1980s on C3, and then on C4, indicated the presence, within the parent C3 and C4 structures, of a unique protein modification, a 15-atom (15-membered) thionolactone ring serving to connect the thiol side chain of the amino acid cysteine (Cys) in a -Cys-Gly-Glu-Glx- sequence with a side chain acyl group of what began as a glutamine side chain (Glx, here) that resided three amino acid residues downstream (where the remaining atoms of the 15 were backbone and side chain atoms);[16][17] upon cleavage, this unique thionolactone ring structure becomes exposed at the surface of the new C4b protein.[15][16][17] Because of proximity to the microbial surface, some portion of the released C4b proteins, with this reactive thionolactone, react with nucelophilic amino acid side chains and other groups on the foreign microbe's cell surface, resulting in covalent attachment of the slightly modified C4b protein to the cell surface, via the original Glx residue of C4.[15][16][17]
C4b has further functions. It interacts with protein C2; the same protease invoked earlier, C1s, then cleaves C2 into two parts, termed C2a and C2b, with C2b being released, and C2a remaining in association with C4b; the C4b-C2a complex of the two proteins then exhibits a further system-associated protease activity toward protein C3 (cleaving it), with subsequent release of both proteins, C4b and C2a, from their complex (whereupon C4b can bind another protein C2, and conduct these steps again).[15] Because C4b is regenerated, and a cycle is created, the C4b-C2a complex with protease activity has been termed the C3 convertase.[15] Protein 4b can be further cleaved into 4c and 4d.[18]
Clinical significance
Although other diseases (i.e. systemic lupus erythematosus) have been implicated, the C4 gene is also being investigated for the role it may play in schizophrenia risk and development. In the Wu et al. study, they utilized the real-time polymerase chain reaction (rt-PCR) as an assay to determine the copy number variance (CNV) or genetic diversity of C4.[19] Accordingly, with these results, future prognoses, flares, and remissions will become more feasible to determine. The results basically show copy number variants as a mechanism to effect genetic diversity. As discussed before, the different phenotypes allowed for by the varying genetic variety of complement C4 include a wide range of plasma or serum C4 proteins among two isotypes—C4A and C4B—with multiple protein allotypes that can have unique physiological functions.[19] CNVs are sources of inherent genetic diversity and are engaged in gene-environment interaction.[19] CNVs (and associated polymorphisms) play a role in filling in the gap towards understanding the genetic basis of quantitative traits and the different susceptibilities to autoimmune and neurobiological diseases.
Substantial data from all over the world has been collected and analyzed to determine that schizophrenia, indeed, has a strong genetic relationship with a region in the MHC locus on chromosome arm 6.[20][21]
Data and information collected internationally can shed light onto the mysteries of schizophrenia. Sekar et al. analyzed single nucleotide polymorphisms (SNP) of 40 cohorts in 22 countries, in total adding up to nearly 29,000 cases.[21] They found out two features: 1) A great number of SNPs reaching only 2Mb across the end, 2) peak of association centered at C4, predicting that C4A expression levels is most strongly correlated with schizophrenia.[21] In addition, they have discovered a mechanism by which schizophrenia could arise from the genetic predisposition of the human complement C4.[21] As shown in Figure 1, four common structural variations discovered in genome-wide association studies (GWAS) studies have pointed to the high turnout of schizophrenia.[21] Possibly, the higher levels of expression of C4 protein due to pattern of variants of the C4 gene, allows for the unwanted increase in synaptic pruning (an effect produced by the effector proteins of the complement system in which the C4 partakes).
See also
References
- 1 2 3 4 5 Yang, Y; Chung, EK; Zhou, B; Blanchong, CA; Yu, CY; Füst, G; Kovács, M; Vatay, A; Szalai, C; Karádi, I; Varga, L (1 September 2003). "Diversity in intrinsic strengths of the human complement system: serum C4 protein concentrations correlate with C4 gene size and polygenic variations, hemolytic activities, and body mass index.". Journal of immunology (Baltimore, Md. : 1950). 171 (5): 2734–45. doi:10.4049/jimmunol.171.5.2734. PMID 12928427.
- 1 2 3 O'Neill, Geoffrey J.; Yang, Soo Young; Tegoli, John; Dupont, Bo; Berger, Rachel (22 June 1978). "Chido and Rodgers blood groups are distinct antigenic components of human complement C4". Nature. 273 (5664): 668–670. doi:10.1038/273668a0.
- 1 2 3 4 5 6 7 8 9 10 11 Yu, CY (1 February 1991). "The complete exon-intron structure of a human complement component C4A gene. DNA sequences, polymorphism, and linkage to the 21-hydroxylase gene.". Journal of immunology (Baltimore, Md. : 1950). 146 (3): 1057–66. PMID 1988494.
- ↑ Francke, U.; Pellegrino, M.A. (March 1977). "Assignment of the major histocompatibility complex to a region of the short arm of human chromosome 6.". Proceedings of the National Academy of Sciences of the United States of America. 74 (3): 1147–51. doi:10.1073/pnas.74.3.1147. PMC 430627
 . PMID 265561.
. PMID 265561. - ↑ Olaisen, B; Teisberg, P; Nordhagen, R; Michaelsen, T; Gedde-Dahl T, Jr (21 June 1979). "Human complement C4 locus is duplicated on some chromosomes.". Nature. 279 (5715): 736–7. doi:10.1038/279736a0. PMID 450123.
- 1 2 3 Carroll, M.C.; Porter, R.R. (1983). "Cloning of a human complement component C4 gene.". Proceedings of the National Academy of Sciences of the United States of America. 80 (1): 264–267. doi:10.1073/pnas.80.1.264. ISSN 0027-8424. PMC 393353. PMID 6572000.
- ↑ Hall, RE; Colten, HR (April 1977). "Cell-free synthesis of the fourth component of guinea pig complement (C4): identification of a precursor of serum C4 (pro-C4).". Proceedings of the National Academy of Sciences of the United States of America. 74 (4): 1707–10. doi:10.1073/pnas.74.4.1707. PMC 430862. PMID 266210.
- 1 2 3 Roos, MH; Mollenhauer, E; Démant, P; Rittner, C (26 August 1982). "A molecular basis for the two locus model of human complement component C4.". Nature. 298 (5877): 854–6. doi:10.1038/298854a0. PMID 6180321.
- 1 2 3 4 5 Carroll, M.C.; Campbell, R.D.; Bentley, D.R.; Porter, R.R. (1984). "A molecular map of the human major histocompatibility complex class III region linking complement genes C4, C2 and factor B". Nature. 307: 237–241. doi:10.1038/307237a0. PMID 6559257.
- 1 2 3 4 5 Carroll, M.C.; Belt, T.; Palsdottir, A.; Porter, R.R. (1984). "Structure and organization of the C4 genes". Philosophical Transactions of the Royal Society B: Biological Sciences. 306 (1129): 379–388. doi:10.1098/rstb.1984.0098. PMID 6149580.
- 1 2 3 4 5 Law, S K; Dodds, A W; Porter, R R (1 August 1984). "A comparison of the properties of two classes, C4A and C4B, of the human complement component C4.". The EMBO Journal. 3 (8): 1819–1823. ISSN 0261-4189. PMC 557602. PMID 6332733.
- 1 2 3 Vaishnaw, AK; Mitchell, TJ; Rose, SJ; Walport, MJ; Morley, BJ (1 May 1998). "Regulation of transcription of the TATA-less human complement component C4 gene.". Journal of immunology (Baltimore, Md. : 1950). 160 (9): 4353–60. PMID 9574539.
- 1 2 3 4 5 6 7 8 9 Blanchong, C.A.; Chung, E.K.; Rupert, K.L.; Yang, Y.; Yang, Z.; Zhou, B.; Moulds, J.M.; Yu, C.Y. (2001). "Genetic, structural, and functional diversities of human complement components C4A and C4B and their mouse homologues, Slp and C4". International Immunopharmacology. 1 (3): 365–392. doi:10.1016/s1567-5769(01)00019-4. PMID 11367523.
- ↑ "Understanding the Immune System: How It Works" (PDF). NIH Publication No. 03–5423. U.S. Department Of Health And Human Services National Institutes of Health, National Institute of Allergy and Infectious Diseases, National Cancer Institute. September 2003. pp. 17–18.
- 1 2 3 4 5 6 7 8 Biedzka-Sarek M, Skurnik M (2012). "Chapter 13: Bacterial Escape from the Complement System". In Locht C, Simonet M. Bacterial Pathogenesis: Molecular and Cellular Mechanisms. Norfolk, UK: Caister Academic Press. pp. 287–304. ISBN 978-1-904455-91-2.
- 1 2 3 4 Law SK, Dodds AW (Feb 1997). "The internal thioester and the covalent binding properties of the complement proteins C3 and C4". Protein Science. 6 (2): 263–74. doi:10.1002/pro.5560060201. PMC 2143658. PMID 9041627.
- 1 2 3 Sepp A, Dodds AW, Anderson MJ, Campbell RD, Willis AC, Law SK (May 1993). "Covalent binding properties of the human complement protein C4 and hydrolysis rate of the internal thioester upon activation". Protein Science. 2 (5): 706–16. doi:10.1002/pro.5560020502. PMC 2142499. PMID 8495193.
- ↑ MacConmara MP (2013). "Recognition and Management of Antibody-Mediated Rejection" (PDF). The Immunology Report. 10 (1): 6–10.
- 1 2 3 Wu, YL; Savelli, SL; Yang, Y; Zhou, B; Rovin, BH; Birmingham, DJ; Nagaraja, HN; Hebert, LA; Yu, CY (1 September 2007). "Sensitive and specific real-time polymerase chain reaction assays to accurately determine copy number variations (CNVs) of human complement C4A, C4B, C4-long, C4-short, and RCCX modules: elucidation of C4 CNVs in 50 consanguineous subjects with defined HLA genotypes.". Journal of immunology (Baltimore, Md. : 1950). 179 (5): 3012–25. doi:10.4049/jimmunol.179.5.3012. PMID 17709516.
- ↑ Stefansson, H; Ophoff, RA; Steinberg, S; Andreassen, OA; Cichon, S; Rujescu, D; Werge, T; Pietiläinen, OP; Mors, O; Mortensen, PB; et al. (6 August 2009). "Common variants conferring risk of schizophrenia.". Nature. 460 (7256): 744–7. doi:10.1038/nature08186. PMC 3077530. PMID 19571808.
- 1 2 3 4 5 Sekar, A; Bialas, AR; de Rivera, H; Davis, A; Hammond, TR; Kamitaki, N; Tooley, K; Presumey, J; Baum, M; Van Doren, V; Genovese, G; Rose, SA; Handsaker, RE; Schizophrenia Working Group of the Psychiatric Genomics, Consortium; Daly, MJ; Carroll, MC; Stevens, B; McCarroll, SA (11 February 2016). "Schizophrenia risk from complex variation of complement component 4.". Nature. 530 (7589): 177–83. doi:10.1038/nature16549. PMID 26814963.
Further reading
- Lewis RE, Cruse JM (2009). Illustrated dictionary of immunology (3rd ed.). Boca Raton, FL: CRC Press. p. 125ff. ISBN 978-0-8493-7988-8.
- Janeway CA, Travers P, Waldport M, Shlomchik MJ (2001). "The Complement System and Innate Immunity". Immunobiology: The Immune System in Health and Disease. New York, NY, USA: Garland Science.
- Truedsson L (Nov 2015). "Classical pathway deficiencies – A short analytical review". review. Molecular Immunology. 68 (1): 14–9. doi:10.1016/j.molimm.2015.05.007. PMID 26038300.
- Abbas, A.K.; Lichtman, A.H.; Pillai, S. (2010). Cellular and Molecular Immunology (6th ed.). Amsterdam, NLD: Elsevier. pp. 272–288. ISBN 978-1-4160-3123-9.
- Klos A, Wende E, Wareham KJ, Monk PN (2013). "International Union of Basic and Clinical Pharmacology. [corrected]. LXXXVII. Complement peptide C5a, C4a, and C3a receptors". Pharmacological Reviews. 65 (1): 500–43. doi:10.1124/pr.111.005223. PMID 23383423.
- Goldman AS, Prabhakar BS (1996). "The Complement System". In Baron S. Baron's Medical Microbiology (4th ed.). Galveston, TX, USA: The University of Texas Medical Branch at Galveston. ISBN 978-0-9631172-1-2.
- Grumach AS, Kirschfink M (Oct 2014). "Are complement deficiencies really rare? Overview on prevalence, clinical importance and modern diagnostic approach". review. Molecular Immunology. 61 (2): 110–7. doi:10.1016/j.molimm.2014.06.030. PMID 25037634.
- Carroll MC, Campbell RD, Bentley DR, Porter RR (1984). "A molecular map of the human major histocompatibility complex class III region linking complement genes C4, C2 and factor B". Nature. 307 (5948): 237–41. doi:10.1038/307237a0. PMID 6559257.
- Carroll MC, Belt T, Palsdottir A, Porter RR (1984). "Structure and organization of the C4 genes". Philosophical Transactions of the Royal Society of London. Series B, Biological Sciences. 306 (1129): 379–88. doi:10.1098/rstb.1984.0098. PMID 6149580.
- Horton R, Gibson R, Coggill P, Miretti M, Allcock RJ, Almeida J, et al. (2008). "Variation analysis and gene annotation of eight MHC haplotypes: the MHC Haplotype Project". Immunogenetics. 60 (1): 1–18. doi:10.1007/s00251-007-0262-2. PMC 2206249. PMID 18193213.
- Law SK, Dodds AW, Porter RR (1984). "A comparison of the properties of two classes, C4A and C4B, of the human complement component C4". The EMBO Journal. 3 (8): 1819–23. PMC 557602. PMID 6332733.
- Isenman DE, Young JR (1984). "The molecular basis for the difference in immune hemolysis activity of the Chido and Rodgers isotypes of human complement component C4". Journal of Immunology (Baltimore, Md. : 1950). 132 (6): 3019–27. PMID 6609966.
- Hakobyan S, Boyajyan A, Sim RB (2005). "Classical pathway complement activity in schizophrenia". Neuroscience Letters. 374 (1): 35–7. doi:10.1016/j.neulet.2004.10.024. PMID 15631892.
- Stevens B, Allen NJ, Vazquez LE, Howell GR, Christopherson KS, Nouri N, et al. (2007). "The classical complement cascade mediates CNS synapse elimination". Cell. 131 (6): 1164–78. doi:10.1016/j.cell.2007.10.036. PMID 18083105.
- Feinberg I (1982). "Schizophrenia: caused by a fault in programmed synaptic elimination during adolescence?". Journal of Psychiatric Research. 17 (4): 319–34. doi:10.1016/0022-3956(82)90038-3. PMID 7187776.
- Mayilyan KR, Dodds AW, Boyajyan AS, Soghoyan AF, Sim RB (2008). "Complement C4B protein in schizophrenia". The World Journal of Biological Psychiatry. 9 (3): 225–30. doi:10.1080/15622970701227803. PMID 17853297.