Rank-dependent expected utility
The rank-dependent expected utility model (originally called anticipated utility) is a generalized expected utility model of choice under uncertainty, designed to explain the behaviour observed in the Allais paradox, as well as for the observation that many people both purchase lottery tickets (implying risk-loving preferences) and insure against losses (implying risk aversion).
A natural explanation of these observations is that individuals overweight low-probability events such as winning the lottery, or suffering a disastrous insurable loss. In the Allais paradox, individuals appear to forgo the chance of a very large gain to avoid a one per cent chance of missing out on an otherwise certain large gain, but are less risk averse when offered the chance of reducing an 11 per cent chance of loss to 10 per cent.
A number of attempts were made to model preferences incorporating probability theory, most notably the original version of prospect theory, presented by Daniel Kahneman and Amos Tversky (1979). However, all such models involved violations of first-order stochastic dominance. In prospect theory, violations of dominance were avoided by the introduction of an 'editing' operation, but this gave rise to violations of transitivity.
The crucial idea of rank-dependent expected utility was to overweight only unlikely extreme outcomes, rather than all unlikely events. Formalising this insight required transformations to be applied to the cumulative probability distribution function, rather than to individual probabilities (Quiggin, 1982, 1993).
The central idea of rank-dependent weightings was then incorporated by Daniel Kahneman and Amos Tversky into prospect theory, and the resulting model was referred to as cumulative prospect theory (Tversky & Kahneman, 1992).
Formal representation
As the name implies, the rank-dependent model is applied to the increasing rearrangement ![\mathbf{y}_{[ \; ]}](../I/m/06329ae4cdc345e1f5c5d8b0d7954872.png) of
of 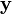 which satisfies
which satisfies ![y_{[1]}\leq y_{[2]}\leq ...\leq
y_{[S]}](../I/m/7be8185680dc6d5daf98fa61b2fcc083.png) .
.
![W(\mathbf{y})=\sum_{s\in \Omega }h_{[s]}(\mathbf{\pi })u(y_{[s]})](../I/m/e0d1ac323f37a862b0790e6bf6ed0c55.png) where
where 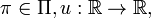 and
and ![h_{[s]}(
\mathbf{\pi })](../I/m/6322b1817f56a79d6926887a50e5a5ce.png) is a probability weight such that
is a probability weight such that
![h_{[s]}(\mathbf{\pi })=q\left( \sum\limits_{t=1}^{s}\pi _{[t]}\right)
-q\left( \sum\limits_{t=1}^{s-1}\pi _{[t]}\right)](../I/m/05452e9c7ed4ba2f6b5cfd7bb946b54d.png)
for a transformation function ![q:[0,1]\rightarrow [0,1]](../I/m/80c984b611a81e414167086754eacc46.png) with
with 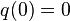 ,
, 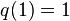 .
.
Note that
![\sum_{s\in \Omega }h_{[s]}(\mathbf{\pi })=q\left( \sum\limits_{t=1}^{S}\pi
_{[t]}\right) =q(1)=1](../I/m/0b1d8b41c2fa665b46e00c2b6f4a84be.png) so that the decision weights sum to 1.
so that the decision weights sum to 1.
References
- Kahneman, Daniel and Amos Tversky. Prospect Theory: An Analysis of Decision under Risk, Econometrica, XVLII (1979), 263-291.
- Tversky, Amos and Daniel Kahneman. Advances in prospect theory: Cumulative representation of uncertainty. Journal of Risk and Uncertainty, 5:297–323, 1992.
- Quiggin, J. (1982), ‘A theory of anticipated utility’, Journal of Economic Behavior and Organization 3(4), 323–43.
- Quiggin, J. Generalized Expected Utility Theory. The Rank-Dependent Model. Boston: Kluwer Academic Publishers, 1993.