Stack machine
In computer science, computer engineering and programming language implementations, a stack machine is a type of computer. In some cases, the term refers to a software scheme that simulates a stack machine. The main difference from other computers is that most of its instructions operate on a pushdown stack of numbers rather than numbers in registers. A stack computer is programmed with a reverse Polish notation instruction set. A stack machine must be a computer, and therefore must be Turing complete, unlike a pushdown automaton. Most computer systems implement a stack in some form to pass parameters and link to subroutines. This does not make these computers "stack machines."
The common alternatives to stack machines are register machines, in which each instruction explicitly names specific registers for its operands and result.
Practical expression-stack machines
A "Stack machine" is a computer that uses a Last-in, First-out stack to hold short-lived temporary values. Most of its instructions assume that operands will be from the stack, and results placed in the stack.
For a typical instruction like "Add," the computer takes both operands from the topmost (most recent) values of the stack. The computer replaces those two values by the sum, calculated by the computer when it performs the "Add" instruction. The instruction's operands are 'popped' off the stack, and its result(s) are then 'pushed' back onto the stack, ready for the next instruction. Most stack instructions have only an opcode commanding an operation, with no additional fields to identify a constant, register or memory cell. The stack easily holds more than two inputs or more than one result, so a richer set of operations can be computed. Integer constant operands are often pushed by separate Load Immediate instructions. Memory is often accessed by separate Load or Store instructions containing a memory address or calculating the address from values in the stack.
For speed, a stack machine often implements some part of its stack with registers. To execute quickly, operands of the arithmetic logic unit (ALU) may be the top two registers of the stack and the result from the ALU is stored in the top register of the stack. Some stack machines have a stack of limited size, implemented as a register file. The ALU will access this with an index. Some machines have a stack of unlimited size, implemented as an array in RAM accessed by a 'top of stack' address register. This is slower, but the number of flip-flops is less, making a less-expensive, more compact CPU. Its topmost N values may be cached for speed.[1][2] A few machines have both an expression stack in memory and a separate register stack. In this case, software, or an interrupt may move data between them.
The instruction set carries out most ALU actions with postfix (Reverse Polish notation) operations that work only on the expression stack, not on data registers or main memory cells. This can be very convenient for executing high-level languages, because most arithmetic expressions can be easily translated into postfix notation.
In contrast, register machines hold temporary values in a small, fast array of registers. Accumulator machines have only one general-purpose register. Belt machines use a FIFO queue to hold temporary values. Memory-to-memory machines that have no temporary registers usable by a programmer.
Stack machines may have their expression stack and their call-return stack separated or as one integrated structure. If they are separated, the instructions of the stack machine can be pipelined with fewer interactions and less design complexity. Usually it can run faster.
Some technical handheld calculators use reverse Polish notation in their keyboard interface, instead of having parenthesis keys. This is a form of stack machine. The Plus key relies on its two operands already being at the correct topmost positions of the user-visible stack.
Advantages of stack machine instruction sets
Very compact object code
Stack machines have much smaller instructions than the other styles of machines. Loads and stores to memory are separate and so stack code requires roughly twice as many instructions as the equivalent code for register machines. The total code size (in bytes) is still less for stack machines.
In stack machine code, the most frequent instructions consist of just an opcode selecting the operation. This can easily fit in 6 bits or less. Branches, load immediates, and load/store instructions require an argument field, but stack machines often arrange that the frequent cases of these still fit together with the opcode into a compact group of bits. The selection of operands from prior results is done implicitly by ordering the instructions. In contrast, register machines require two or three register-number fields per ALU instruction to select operands; the densest register machines average about 16 bits per instruction.
The instructions for accumulator or memory-to-memory machines are not padded out with multiple register fields. Instead, they use compiler-managed anonymous variables for subexpression values. These temporary locations require extra memory reference instructions which take more code space than for the stack machine, or even compact register machines.
All practical stack machines have variants of the load/store opcodes for accessing local variables and formal parameters without explicit address calculations. This can be by offsets from the current top-of-stack address, or by offsets from a stable frame-base register. Register machines handle this with a register+offset address mode, but use a wider offset field.
Dense machine code was very valuable in the 1960s, when main memory was very expensive and very limited even on mainframes. It became important again on the initially-tiny memories of minicomputers and then microprocessors. Density remains important today, for smartphone applications, applications downloaded into browsers over slow Internet connections, and in ROMs for embedded applications. A more general advantage of increased density is improved effectiveness of caches and instruction prefetch.
Some of the density of Burroughs B6700 code was due to moving vital operand information elsewhere, to 'tags' on every data word or into tables of pointers. The Add instruction itself was generic or polymorphic. It had to fetch the operand to discover whether this was an integer add or floating point add. The Load instruction could find itself tripping on an indirect address, or worse, a disguised call to a call-by-name thunk routine. The generic opcodes required fewer opcode bits but made the hardware more like an interpreter, with less opportunity to pipeline the common cases.
Simple compilers
Compilers for stack machines are simpler and quicker to build than compilers for other machines. Code generation is trivial and independent of prior or subsequent code. For example, given an expression x+y*z+u, the corresponding syntax tree would be:
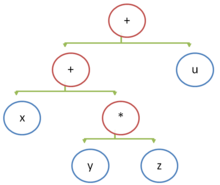
The compiled code for a simple stack machine would take the form:
push x push y push z multiply add push u add
Note that the arithmetic operations 'multiply' and 'add' act on the two topmost operands of the stack.
Such simple compilation can be done by the parsing pass. No register management is needed. Most stack machines can copy stack entries to avoid memory access (which is much slower), but these are usually trivial. The same opcode that handles the frequent common case of an add, an indexed load, or a function call will also handle the general case involving complex subexpressions and nested calls. The compiler and the CPU do not need special cases for instructions that have separate calculation paths for addresses.
This simplicity has allowed compilers to fit onto very small machines. The simple compilers allowed new product lines to get to market quickly, and allowed new operating systems to be written entirely in a high level language rather than in assembly.[1][2] For example, the UCSD p-System supported a complete student programming environment on early 8-bit microprocessors with poor instruction sets and little RAM, by compiling to a virtual stack machine rather than to the actual hardware.
The downside to the simplicity of compilers for stack machines, is that pure stack machines have fewer optimisations (see subsections in § performance disadvantages of stack machines). However optimisation of compiled stack code is quite possible. Back-end optimisation of compiler output has been demonstrated to significantly improve code,[3][4] and potentially performance, whilst global optimisation within the compiler itself achieves further gains.[5]
Simple interpreters
Some stack machine instruction sets are intended for interpretive execution of a virtual machine, rather than driving hardware directly. Interpreters for virtual stack machines are easier to build than interpreters for register or memory-to-memory machines; the logic for handling memory address modes is in just one place rather than repeated in many instructions. Stack machines also tend to have fewer variations of an opcode; one generalized opcode will handle both frequent cases and obscure corner cases of memory references or function call setup. (But code density is often improved by adding short and long forms for the same operation.)
Fast operand access
Since there are no operand fields to decode, stack machines fetch each instruction and its operands at same time. Stack machines can omit the operand fetching stage of a register machine.[6] In addition, except explicit load from memory instructions, the order of operand usage is identical with the order of the operands in the data stack. So excellent prefetching is accomplished easily by keeping operands on the top of stack in fast storage. For example, in the JOP microprocessor the top 2 operands of stack directly enter a data forwarding circuit that is faster than the register file.[7]
Avoids data passing through memory, faster interpreters
Fast access is also useful for interpreters. Most register interpreters specify their registers by number. But a host machine's registers can't be accessed in an indexed array, so a memory array is allotted for virtual registers. Therefore, the instructions of a register interpreter must use memory for passing generated data to the next instruction. This forces register interpreters to be much slower on microprocessors made with a fine process rule (i.e. faster transistors without improving circuit speeds, such as the Haswell x86). These require several clocks for memory access, but only one clock for register access. In the case of a stack machine with a data forwarding circuit instead of a register file, stack interpreters can allot the host machine's registers for the top several operands of the stack instead of the host machine's memory.
Minimal processor state
A machine with an expression stack can get by with just two registers that are visible to a programmer: The top-of-stack address and the next-instruction address. The minimal hardware implementation has far fewer bits of flipflops or registers. Faster designs can simply buffer the topmost N stack cells into registers to reduce memory stack cycles.
Responding to an interrupt involves saving the registers to a stack, and then branching to the interrupt handler code. In a stack machine, most parameters are already on a stack. Therefore, there is no need to push them there. Often stack machines respond more quickly to interrupts.[8] Some register machines deal with this by having multiple register files that can be instantly swapped[9] but this increases costs and slows down the register file.
Performance disadvantages of stack machines
More memory references
Some in the industry believe that stack machines execute more data cache cycles for temporary values and local variables than do register machines.[10]
On stack machines, temporary values often get spilled into memory, whereas on machines with many registers these temps usually remain in registers. (However, these values often need to be spilled into "activation frames" at the end of a procedure's definition, basic block, or at the very least, into a memory buffer during interrupt processing). Values spilled to memory add more cache cycles. This spilling effect depends on the number of hidden registers used to buffer top-of-stack values, upon the frequency of nested procedure calls, and upon host computer interrupt processing rates.
Some simple stack machines or stack interpreters use no top-of-stack hardware registers. Those minimal implementations are always slower than standard register machines. A typical expression like X+1 compiles to 'Load X; Load 1; Add'. This does implicit writes and reads of the memory stack which weren't needed:
- Load X, push to memory
- Load 1, push to memory
- Pop 2 values from memory, add, and push result to memory
for a total of 5 data cache references.
The next step up from this is a stack machine or interpreter with a single top-of-stack register. The above code then does:
- Load X into empty TOS register (if hardware machine), or
- Push TOS register to memory, Load X into TOS register (if interpreter)
- Push TOS register to memory, Load 1 into TOS register
- Pop left operand from memory, add to TOS register and leave it there
for a total of 5 data cache references, worst-case. Generally, interpreters don't track emptiness, because they don't have to—anything below the stack pointer is a non-empty value, and the TOS cache register is always kept hot. Typical Java interpreters do not buffer the top-of-stack this way, however, because the program and stack have a mix of short and wide data values.
If the hardwired stack machine has N registers to cache the topmost memory stack words, then all spills and refills are avoided in this example and there is only 1 data cache cycle, the same as for a register or accumulator machine.
On register machines using optimizing compilers, it is very common for the most-used local variables to remain in registers rather than in stack frame memory cells. This eliminates most data cache cycles for reading and writing those values. The development of 'stack scheduling' for performing live-variable analysis, and thus retaining key variables on the stack for extended periods, helps this concern.
On the other hand, register machines must spill many of their registers to memory across nested procedure calls. The decision of which registers to spill, and when, is made statically at compile time rather than on the dynamic depth of the calls. This can lead to more data cache traffic than in an advanced stack machine implementation.
Factoring out common subexpressions has high cost
In register machines, a subexpression which is used multiple times with the same result value can be evaluated just once and its result saved in a fast register. The subsequent reuses have no time or code cost, just a register reference. This optimization speeds simple expressions (for example, loading variable X or pointer P) as well as less-common complex expressions.
With stack machines, in contrast, results can be stored in one of two ways: A temporary variable in memory. Storing and subsequent retrievals cost additional instructions and additional data cache cycles. Doing this is only a win if the subexpression computation costs more in time than fetching from memory, which in most stack CPUs, almost always is the case. It is never worthwhile for simple variables and pointer fetches, because those already have the same cost of one data cache cycle per access. It is only marginally worthwhile for expressions like X+1. These simpler expressions make up the majority of redundant, optimizable expressions in programs written in non-concatenative languages. An optimizing compiler can only win on redundancies that the programmer could have avoided in the source code.
The second way leaves a computed value on the data stack, duplicating it as needed. This uses operations to copy stack entries. The stack must be depth shallow enough for the CPU's available copy instructions. Hand-written stack code often uses this approach, and achieves speeds like general-purpose register machines.[6][11] Unfortunately, algorithms for optimal "stack scheduling" are not in wide use by programming languages.
Rigid code order
In modern machines, the time to fetch a variable from the data cache is often several times longer than the time needed for basic ALU operations. A program runs faster without stalls if its memory loads can be started several cycles before the instruction that needs that variable. Complex machines can do this with a deep pipeline and "out-of-order execution" that examines and runs many instructions at once. Register machines can even do this with much simpler "in-order" hardware, a shallow pipeline, and slightly smarter compilers.[12] The load step becomes a separate instruction, and that instruction is statically scheduled much earlier in the code sequence. The compiler puts independent steps in between.
Scheduling memory accesses requires explicit, spare registers. It is not possible on stack machines without exposing some aspect of the micro-architecture to the programmer. For the expression A-B, the right operand must be evaluated and pushed immediately prior to the Minus step. Without stack permutation or hardware multithreading, relatively little useful code can be put in between while waiting for the Load B to finish. Stack machines can work around the memory delay by either having a deep out-of-order execution pipeline covering many instructions at once, or more likely, they can permute the stack such that they can work on other workloads while the load completes, or they can interlace the execution of different program threads, as in the Unisys A9 system.[13] Today's increasingly parallel computational loads suggests, however, this might not be the disadvantage it's been made out to be in the past.
Able to use Out-of-Order Execution
The Tomasulo algorithm finds instruction-level parallelism by issuing instructions as their data becomes available. Conceptually, the addresses of positions in a stack are no different than the register indexes of a register file. This view permits the out-of-order execution of the Tomasulo algorithm to be used with stack machines.
Out-of-order execution in stack machines seems to reduce or avoid many theoretical and practical difficulties.[14] The cited research shows that such a stack machine can exploit instruction-level parallelism, and the resulting hardware must cache data for the instructions. Such machines effectively bypass most memory accesses to the stack. The result achieves throughput (instructions per clock) comparable to RISC register machines, with much higher code densities (because operand addresses are implicit).
A stack machine's compact code naturally fits more instructions in cache, and therefore could achieve better cache efficiency, reducing memory costs or permitting faster memory systems for a given cost. In addition, most stack-machine instruction is very simple, made from only one opcode field or one operand field. Thus, stack-machines require very little electronic resources to decode each instruction.
One issue brought up in the research was that it takes about 1.88 stack-machine instructions to do the work of a register machine's RISC instruction. Competitive out-of-order stack machines therefore require about twice as many electronic resources to track instructions ("issue stations"). This might be compensated by savings in instruction cache and memory and instruction decoding circuit.
Hides a faster register machine inside
Some simple stack machines have a chip design which is fully customized all the way down to the level of individual registers. The top of stack address register and the N top of stack data buffers are built from separate individual register circuits, with separate adders and ad hoc connections.
However, most stack machines are built from larger circuit components where the N data buffers are stored together within a register file and share read/write buses. The decoded stack instructions are mapped into one or more sequential actions on that hidden register file. Loads and ALU ops act on a few topmost registers, and implicit spills and fills act on the bottommost registers. The decoder allows the instruction stream to be compact. But if the code stream instead had explicit register-select fields which directly manipulated the underlying register file, the compiler could make better use of all registers and the program would run faster.
Microprogrammed stack machines are an example of this. The inner microcode engine is some kind of RISC-like register machine or a VLIW-like machine using multiple register files. When controlled directly by task-specific microcode, that engine gets much more work completed per cycle than when controlled indirectly by equivalent stack code for that same task.
The object code translators for the HP 3000 and Tandem T/16 are another example.[15][16] They translated stack code sequences into equivalent sequences of RISC code. Minor 'local' optimizations removed much of the overhead of a stack architecture. Spare registers were used to factor out repeated address calculations. The translated code still retained plenty of emulation overhead from the mismatch between original and target machines. Despite that burden, the cycle efficiency of the translated code matched the cycle efficiency of the original stack code. And when the source code was recompiled directly to the register machine via optimizing compilers, the efficiency doubled. This shows that the stack architecture and its non-optimizing compilers were wasting over half of the power of the underlying hardware.
Register files are good tools for computing because they have high bandwidth and very low latency, compared to memory references via data caches. In a simple machine, the register file allows reading two independent registers and writing of a third, all in one ALU cycle with one-cycle or less latency. Whereas the corresponding data cache can start only one read or one write (not both) per cycle, and the read typically has a latency of two ALU cycles. That's one third of the throughput at twice the pipeline delay. In a complex machine like Athlon that completes two or more instructions per cycle, the register file allows reading of four or more independent registers and writing of two others, all in one ALU cycle with one-cycle latency. Whereas the corresponding dual-ported data cache can start only two reads or writes per cycle, with multiple cycles of latency. Again, that's one third of the throughput of registers. It is very expensive to build a cache with additional ports.
More instructions, slower interpreters
Interpreters for virtual stack machines are often slower than interpreters for other styles of virtual machine.[17] This slowdown is worst when running on host machines with deep execution pipelines, such as current x86 chips.
A program has to execute more instructions when compiled to a stack machine than when compiled to a register machine or memory-to-memory machine. Every variable load or constant requires its own separate Load instruction, instead of being bundled within the instruction which uses that value. The separated instructions may be simple and faster running, but the total instruction count is still higher.
In some interpreters, the interpreter must execute a N-way switch jump to decode the next opcode and branch to its steps for that particular opcode. Another method for selecting opcodes is threaded code. The host machine's prefetch mechanisms are unable to predict and fetch the target of that indexed or indirect jump. So the host machine's execution pipeline must restart each time the hosted interpreter decodes another virtual instruction. This happens more often for virtual stack machines than for other styles of virtual machine.[18]
Android's Dalvik virtual machine for Java uses a virtual-register 16-bit instruction set instead of Java's usual 8-bit stack code, to minimize instruction count and opcode dispatch stalls. Arithmetic instructions directly fetch or store local variables via 4-bit (or larger) instruction fields. Version 5.0 of Lua replaced its virtual stack machine with a faster virtual register machine.[19][20]
Since Java virtual machine becomes popular, current microprocessors employ advanced branch predictor for indirect jumps.[21] This advance avoids most of pipeline restarts from N-way jumps, thus almost eliminates instruction count costs which affects rather stack interpreters than register interpreters.
Hybrid machines
(These should not be confused with hybrid computers that combine both digital and analogue features, e.g. an otherwise digital computer that accesses analogue multiplication or differential equation solving by memory mapping and conversion to and from an analogue device's inputs and outputs.)
Pure stack machines are quite inefficient for procedures which access multiple fields from the same object. The stack machine code must reload the object pointer for each pointer+offset calculation. A common fix for this is to add some register-machine features to the stack machine: a visible register file dedicated to holding addresses, and register-style instructions for doing loads and simple address calculations. It is uncommon to have the registers be fully general purpose, because then there is no strong reason to have an expression stack and postfix instructions.
Another common hybrid is to start with a register machine architecture, and add another memory address mode which emulates the push or pop operations of stack machines: 'memaddress = reg; reg += instr.displ'. This was first used in DEC's PDP-11 minicomputer. This feature was carried forward in VAX computers and in Motorola 6800 and M68000 microprocessors. This allowed the use of simpler stack methods in early compilers. It also efficiently supported virtual machines using stack interpreters or threaded code. However, this feature did not help the register machine's own code to become as compact as pure stack machine code. Also, the execution speed was less than when compiling well to the register architecture. It is faster to change the top-of-stack pointer only occasionally (once per call or return) rather than constantly stepping it up and down throughout each program statement, and it is even faster to avoid memory references entirely.
More recently, so-called second-generation stack machines have adopted a dedicated collection of registers to serve as address registers, off-loading the task of memory addressing from the data stack. For example, MuP21 relies on a register called "A", while the more recent GreenArrays processors relies on two registers: A and B.[11]
The Intel x86 family of microprocessors have a register-style (accumulator) instruction set for most operations, but use stack instructions for its x87, Intel 8087 floating point arithmetic, dating back to the iAPX87 (8087) coprocessor for the 8086 and 8088. That is, there are no programmer-accessible floating point registers, but only an 80-bit wide, 8 deep stack. The x87 relies heavily on the x86 CPU for assistance in performing its operations.
Commercial stack machines
Examples of stack instruction sets directly executed in hardware include
- The F18A architecture of the 144-processor GA144 chip from GreenArrays, Inc.[22][23][24]
- the Burroughs large systems architecture (since 1961)
- the English Electric KDF9 machine. First delivered in 1964, the KDF9 had a 19-deep pushdown stack of arithmetic registers, and a 17-deep stack for subroutine return addresses
- the Collins Radio Collins Adaptive Processing System minicomputer (CAPS, since 1969) and Rockwell Collins Advanced Architecture Microprocessor (AAMP, since 1981).[25]
- the UCSD Pascal p-machine (as the Pascal MicroEngine and many others)
- MU5 and ICL 2900 Series. Hybrid stack and accumulator machines. The accumulator register buffered the memory stack's top data value. Variants of load and store opcodes controlled when that register was spilled to the memory stack or reloaded from there.
- HP 3000 (Classic, not PA-RISC)
- Tandem Computers T/16. Like HP 3000, except that compilers, not microcode, controlled when the register stack spilled to the memory stack or was refilled from the memory stack.
- the Atmel MARC4 microcontroller[26]
- Several "Forth chips"[27] such as the RTX2000, the RTX2010, the F21[28] and the PSC1000[29][30]
- The Setun Ternary computer performed Balanced ternary using a stack.
- The 4stack processor by Bernd Paysan has four stacks.[31]
- Patriot Scientific's Ignite stack machine designed by Charles H. Moore holds a leading functional density benchmark.
- Saab Ericsson Space Thor radiation hardened microprocessor[32]
- Inmos transputers.
- ZPU A physically-small CPU designed to supervise FPGA systems.[33]
Virtual stack machines
Examples of virtual stack machines interpreted in software:
- the Whetstone ALGOL 60 interpretive code,[34] on which some features of the Burroughs B6500 were based
- the UCSD Pascal p-machine (which closely resembled Burroughs)
- the Java virtual machine instruction set
- the VES (Virtual Execution System) for the CIL (Common Intermediate Language) instruction set of the ECMA 335 (Microsoft .NET environment)
- the Forth programming language, in particular the Forth virtual machine
- Adobe's PostScript
- Parakeet programming language
- Sun Microsystems' SwapDrop programming language for Sun Ray smartcard identification
- Adobe's AVM2
- Ethereum's EVM
- the CPython bytecode interpreter
- the Ruby YARV bytecode interpreter
- the Rubinius Virtual Machine
Computers using call stacks and stack frames
Most current computers (of any instruction set style) and most compilers use a large call-return stack in memory to organize the short-lived local variables and return links for all currently active procedures or functions. Each nested call creates a new stack frame in memory, which persists until that call completes. This call-return stack may be entirely managed by the hardware via specialized address registers and special address modes in the instructions. Or it may be merely a set of conventions followed by the compilers, using generic registers and register+offset address modes. Or it may be something in between.
Since this technique is now nearly universal, even on register machines, it is not helpful to refer to all these machines as stack machines. That term is commonly reserved for machines which also use an expression stack and stack-only arithmetic instructions to evaluate the pieces of a single statement.
Computers commonly provide direct, efficient access to the program's global variables and to the local variables of only the current innermost procedure or function, the topmost stack frame. 'Up level' addressing of the contents of callers' stack frames is usually not needed and not supported as directly by the hardware. If needed, compilers support this by passing in frame pointers as additional, hidden parameters.
Some Burroughs stack machines do support up-level refs directly in the hardware, with specialized address modes and a special 'display' register file holding the frame addresses of all outer scopes. No subsequent computer lines have done this in hardware. When Niklaus Wirth developed the first Pascal compiler for the CDC 6000, he found that it was faster overall to pass in the frame pointers as a chain, rather than constantly updating complete arrays of frame pointers. This software method also adds no overhead for common languages like C which lack up-level refs.
The same Burroughs machines also supported nesting of tasks or threads. The task and its creator share the stack frames that existed at the time of task creation, but not the creator's subsequent frames nor the task's own frames. This was supported by a cactus stack, whose layout diagram resembled the trunk and arms of a Saguaro cactus. Each task had its own memory segment holding its stack and the frames that it owns. The base of this stack is linked to the middle of its creator's stack. In machines with a conventional flat address space, the creator stack and task stacks would be separate heap objects in one heap.
In some programming languages, the outer-scope data environments are not always nested in time. These languages organize their procedure 'activation records' as separate heap objects rather than as stack frames appended to a linear stack.
In simple languages like Forth that lack local variables and naming of parameters, stack frames would contain nothing more than return branch addresses and frame management overhead. So their return stack holds bare return addresses rather than frames. The return stack is separate from the data value stack, to improve the flow of call setup and returns.
See also
- Belt machine
- Stack-oriented programming language
- Concatenative programming language
- Comparison of application virtual machines
References
- 1 2 Burroughs large systems
- 1 2 HP 3000
- ↑ Koopman, Philip (1994). "A Preliminary Exploration of Optimized Stack Code Generation" (PDF). Journal of Forth applications and Research. 6 (3).
- ↑ Bailey, Chris (2000). "Inter-Boundary Scheduling of Stack Operands: A preliminary Study" (PDF). Proceedings of Euroforth 2000 Conference.
- ↑ Shannon, Mark; Bailey C (2006). "Global Stack Allocation : Register Allocation for Stack Machines" (PDF). Proceedings of Euroforth Conference 2006.
- 1 2 http://www.ece.cmu.edu/~koopman/stack_computers/ Stack Computers: the new wave book by Philip J. Koopman, Jr. 1989
- ↑ http://www.jopdesign.com/doc/stack.pdf
- ↑ RTX2010
- ↑ 8051 CPU Manual, Intel, 1980
- ↑ "Computer Architecture: A Quantitative Approach", John L Hennessy, David A Patterson; See the discussion of stack machines.
- 1 2 http://www.eecg.utoronto.ca/~laforest/Second-Generation_Stack_Computer_Architecture.pdf Second-Generation Stack Computer Architecture
- ↑ Hennessy, ibid.
- ↑ 'Introduction to A Series Systems', Burroughs Corporation, page 41, http://www.bitsavers.org/pdf/burroughs/A-Series/1170057_aSeries_Intro_apr86.pdf
- ↑ Chatterji, Satrajit; Ravindran, Kaushik. "BOOST: Berkeley's Out of Order Stack Thingie". Research Gate. Kaushik Ravindran. Retrieved 16 February 2016.
- ↑ HP3000 Emulation on HP Precision Architecture Computers, Arndt Bergh, Keith Keilman, Daniel Magenheimer, and James Miller, Hewlett-Packard Journal, Dec 1987, p87-89, http://www.hpl.hp.com/hpjournal/pdfs/IssuePDFs/1987-12.pdf
- ↑ Migrating a CISC Computer Family onto RISC via Object Code Translation, K. Andrews and D. Sand, Proceedings of ASPLOS-V, October, 1992
- ↑ "Virtual Machine Showdown: Stack vs. Register Machine", Yunhe Shi, David Gregg, Andrew Beatty, M. Anton Ertle, http://usenix.org/events/vee05/full_papers/p153-yunhe.pdf
- ↑ 'The Case for Virtual Register Machines', Brian Davis, Andrew Beatty, Kevin Casey, David Gregg and John Waldron, http://www.scss.tcd.ie/David.Gregg/papers/Gregg-SoCP-2005.pdf
- ↑ 'The Implementation of Lua 5.0', Ierusalimschy, de Figueiredo, and Celes, http://www.lua.org/doc/jucs05.pdf
- ↑ 'The Virtual Machine of Lua 5.0', Roberto Ierusalimschy, http://www.inf.puc-rio.br/~roberto/talks/lua-ll3.pdf
- ↑ "Branch Prediction and the Performance of Interpreters - Don't Trust Folklore" Erven Rohou, Bharath Narasimha Swamy, Andr ́e Seznec
- ↑ "GreenArrays, Inc. Documentation: sections on Architecture, F18A Technology and Chips using F18A Technology"
- ↑ "Instruction set of the F18A cores (named colorForth for historical reasons)."
- ↑ "GreenArrays, Inc."
- ↑ "The World's First Java Processor", by David A. Greve and Matthew M. Wilding, Electronic Engineering Times, Jan. 12, 1998,
- ↑ 'MARC4 4-bit Microcontrollers Programmers Guide', Atmel, http://www.atmel.com/dyn/resources/prod_documents/doc4747.pdf
- ↑ Forth chips
- ↑ F21 Microprocessor Overview
- ↑ PSC1000 Microprocessor Reference Manual, Patriot Scientific Corporation, http://www.forthfreak.net/misc/psc1000.pdf
- ↑ A Java chip available — now!, by Rick Brian Slack
- ↑ 4stack Processor
- ↑ 'Porting the GNU C Compiler to the Thor Microprocessor', Harry Gunnarsson and Thomas Lundqvist, http://lundqvist.dyndns.org/Publications/thesis95/ThorGCC.pdf
- ↑ "ZPU - the world's smallest 32-bit CPU with a GCC tool-chain: Overview". opencores.org. Retrieved 7 February 2015.
- ↑ Randell, Brian and Russell, Lawford John "Algol 60 Implementation" London: Academic Press, 1964. ISBN 0-12-578150-4.
External links
- Stack Computers: the new wave book by Philip J. Koopman, Jr. 1989
- Homebrew CPU in an FPGA — homebrew stack machine using FPGA
- Mark 1 FORTH Computer — homebrew stack machine using discrete logical circuits
- Mark 2 FORTH Computer — homebrew stack machine using bitslice/PLD
- Second-Generation Stack Computer Architecture — Thesis about the history and design of stack machines.