Basis (linear algebra)
In mathematics, a set of elements (vectors) in a vector space V is called a basis, or a set of basis vectors, if the vectors are linearly independent and every vector in the vector space is a linear combination of this set.[1] In more general terms, a basis is a linearly independent spanning set.
Given a basis of a vector space V, every element of V can be expressed uniquely as a linear combination of basis vectors, whose coefficients are referred to as vector coordinates or components. A vector space can have several distinct sets of basis vectors; however each such set has the same number of elements, with this number being the dimension of the vector space.
Definition
.svg.png)
A basis B of a vector space V over a field F is a linearly independent subset of V that spans V.
In more detail, suppose that B = { v1, …, vn } is a finite subset of a vector space V over a field F (such as the real or complex numbers R or C). Then B is a basis if it satisfies the following conditions:
- the linear independence property,
- for all a1, …, an ∈ F, if a1v1 + … + anvn = 0, then necessarily a1 = … = an = 0; and
- the spanning property,
- for every x in V it is possible to choose a1, …, an ∈ F such that x = a1v1 + … + anvn.
The numbers ai are called the coordinates of the vector x with respect to the basis B, and by the first property they are uniquely determined.
A vector space that has a finite basis is called finite-dimensional. To deal with infinite-dimensional spaces, we must generalize the above definition to include infinite basis sets. We therefore say that a set (finite or infinite) B ⊂ V is a basis, if
- every finite subset B0 ⊆ B obeys the independence property shown above; and
- for every x in V it is possible to choose a1, …, an ∈ F and v1, …, vn ∈ B such that x = a1v1 + … + anvn.
The sums in the above definition are all finite because without additional structure the axioms of a vector space do not permit us to meaningfully speak about an infinite sum of vectors. Settings that permit infinite linear combinations allow alternative definitions of the basis concept: see Related notions below.
It is often convenient to list the basis vectors in a specific order, for example, when considering the transformation matrix of a linear map with respect to a basis. We then speak of an ordered basis, which we define to be a sequence (rather than a set) of linearly independent vectors that span V: see Ordered bases and coordinates below.
Properties
Again, B denotes a subset of a vector space V. Then, B is a basis if and only if any of the following equivalent conditions are met:
- B is a minimal generating set of V, i.e., it is a generating set and no proper subset of B is also a generating set.
- B is a maximal set of linearly independent vectors, i.e., it is a linearly independent set but no other linearly independent set contains it as a proper subset.
- Every vector in V can be expressed as a linear combination of vectors in B in a unique way. If the basis is ordered (see Ordered bases and coordinates below) then the coefficients in this linear combination provide coordinates of the vector relative to the basis.
Every vector space has a basis. The proof of this requires the axiom of choice. All bases of a vector space have the same cardinality (number of elements), called the dimension of the vector space. This result is known as the dimension theorem, and requires the ultrafilter lemma, a strictly weaker form of the axiom of choice.
Also many vector sets can be attributed a standard basis which comprises both spanning and linearly independent vectors.
Standard bases for example:
In Rn, {e1, ..., en}, where ei is the ith column of the identity matrix.
In P2, where P2 is the set of all polynomials of degree at most 2, {1, x, x2} is the standard basis.
In M22, {M1,1, M1,2, M2,1, M2,2}, where M22 is the set of all 2×2 matrices. and Mm,n is the 2×2 matrix with a 1 in the m,n position and zeros everywhere else.
Change of basis
Given a vector space V over a field F and suppose that {v1, ..., vn} and {α1, ..., αn} are two bases for V. By definition, if ξ is a vector in V then ξ = x1α1 + ... + xnαn for a unique choice of scalars x1, ..., xn in F called the coordinates of ξ relative to the ordered basis {α1, ..., αn}. The vector x = (x1, ..., xn) in Fn is called the coordinate tuple of ξ (relative to this basis). The unique linear map φ : Fn → V with φ(vj) = αj for j = 1, ..., n is called the coordinate isomorphism for V and the basis {α1, ..., αn}. Thus φ(x) = ξ if and only if ξ = x1α1 + ... + xnαn.
A set of vectors can be represented by a matrix of which each column consists of the components of the corresponding vector of the set. As a basis is a set of vectors, a basis can be given by a matrix of this kind. The change of basis of any object of the space is related to this matrix. For example, coordinate tuples change with its inverse.
Examples
- Consider R2, the vector space of all coordinates (a, b) where both a and b are real numbers. Then a very natural and simple basis is simply the vectors e1 = (1,0) and e2 = (0,1): suppose that v = (a, b) is a vector in R2, then v = a(1,0) + b(0,1). But any two linearly independent vectors, like (1,1) and (−1,2), will also form a basis of R2.
- More generally, the vectors e1, e2, ..., en are linearly independent and generate Rn. Therefore, they form a basis for Rn and the dimension of Rn is n. This basis is called the standard basis.
- Let V be the real vector space generated by the functions et and e2t. These two functions are linearly independent, so they form a basis for V.
- Let R[x] denote the vector space of real polynomials; then (1, x, x2, ...) is a basis of R[x]. The dimension of R[x] is therefore equal to aleph-0.
Extending to a basis
Let S be a subset of a vector space V. To extend S to a basis means to find a basis B that contains S as a subset. This can be done if and only if S is linearly independent. Almost always, there is more than one such B, except in rather special circumstances (i.e. S is already a basis, or S is empty and V has two elements).
A similar question is when does a subset S contain a basis. This occurs if and only if S spans V. In this case, S will usually contain several different bases.
Example of alternative proofs
Often, a mathematical result can be proven in more than one way. Here, using three different proofs, we show that the vectors (1,1) and (−1,2) form a basis for R2.
From the definition of basis
We have to prove that these two vectors are linearly independent and that they generate R2.
Part I: If two vectors v,w are linearly independent, then (a and b scalars) implies


To prove that they are linearly independent, suppose that there are numbers a,b such that:

(i.e., they are linearly dependent). Then:
- andand



Subtracting the first equation from the second, we obtain:
- so


Adding this equation to the first equation then:

Hence we have linear independence.
Part II: To prove that these two vectors generate R2, we have to let (a,b) be an arbitrary element of R2, and show that there exist numbers r,s ∈ R such that:

Then we have to solve the equations:


Subtracting the first equation from the second, we get:
- and then
- and finally



By the dimension theorem
Since (−1,2) is clearly not a multiple of (1,1) and since (1,1) is not the zero vector, these two vectors are linearly independent. Since the dimension of R2 is 2, the two vectors already form a basis of R2 without needing any extension.
By the invertible matrix theorem
Simply compute the determinant

Since the above matrix has a nonzero determinant, its columns form a basis of R2. See: invertible matrix.
Ordered bases and coordinates
A basis is just a linearly independent set of vectors with or without a given ordering. For many purposes it is convenient to work with an ordered basis. For example, when working with a coordinate representation of a vector it is customary to speak of the "first" or "second" coordinate, which makes sense only if an ordering is specified for the basis. For finite-dimensional vector spaces one typically indexes a basis {vi} by the first n integers. An ordered basis is also called a frame.
Suppose V is an n-dimensional vector space over a field F. A choice of an ordered basis for V is equivalent to a choice of a linear isomorphism φ from the coordinate space Fn to V.
Proof. The proof makes use of the fact that the standard basis of Fn is an ordered basis.
Suppose first that
- φ : Fn → V
is a linear isomorphism. Define an ordered basis {vi} for V by
- vi = φ(ei) for 1 ≤ i ≤ n
where {ei} is the standard basis for Fn.
Conversely, given an ordered basis, consider the map defined by
- φ(x) = x1v1 + x2v2 + ... + xnvn,
where x = x1e1 + x2e2 + ... + xnen is an element of Fn. It is not hard to check that φ is a linear isomorphism.
These two constructions are clearly inverse to each other. Thus ordered bases for V are in 1-1 correspondence with linear isomorphisms Fn → V.
The inverse of the linear isomorphism φ determined by an ordered basis {vi} equips V with coordinates: if, for a vector v ∈ V, φ−1(v) = (a1, a2,...,an) ∈ Fn, then the components aj = aj(v) are the coordinates of v in the sense that v = a1(v) v1 + a2(v) v2 + ... + an(v) vn.
The maps sending a vector v to the components aj(v) are linear maps from V to F, because of φ−1 is linear. Hence they are linear functionals. They form a basis for the dual space of V, called the dual basis.
Related notions
Analysis
In the context of infinite-dimensional vector spaces over the real or complex numbers, the term Hamel basis (named after Georg Hamel) or algebraic basis can be used to refer to a basis as defined in this article. This is to make a distinction with other notions of "basis" that exist when infinite-dimensional vector spaces are endowed with extra structure. The most important alternatives are orthogonal bases on Hilbert spaces, Schauder bases and Markushevich bases on normed linear spaces. The term Hamel basis is also commonly used to mean a basis for the real numbers R as a vector space over the field Q of rational numbers. (In this case, the dimension of R over Q is uncountable, specifically the continuum, the cardinal number 2ℵ0.)
The common feature of the other notions is that they permit the taking of infinite linear combinations of the basis vectors in order to generate the space. This, of course, requires that infinite sums are meaningfully defined on these spaces, as is the case for topological vector spaces – a large class of vector spaces including e.g. Hilbert spaces, Banach spaces or Fréchet spaces.
The preference of other types of bases for infinite-dimensional spaces is justified by the fact that the Hamel basis becomes "too big" in Banach spaces: If X is an infinite-dimensional normed vector space which is complete (i.e. X is a Banach space), then any Hamel basis of X is necessarily uncountable. This is a consequence of the Baire category theorem. The completeness as well as infinite dimension are crucial assumptions in the previous claim. Indeed, finite-dimensional spaces have by definition finite bases and there are infinite-dimensional (non-complete) normed spaces which have countable Hamel bases. Consider , the space of the sequences of real numbers which have only finitely many non-zero elements, with the norm Its standard basis, consisting of the sequences having only one non-zero element, which is equal to 1, is a countable Hamel basis.



Example
In the study of Fourier series, one learns that the functions {1} ∪ { sin(nx), cos(nx) : n = 1, 2, 3, ... } are an "orthogonal basis" of the (real or complex) vector space of all (real or complex valued) functions on the interval [0, 2π] that are square-integrable on this interval, i.e., functions f satisfying

The functions {1} ∪ { sin(nx), cos(nx) : n = 1, 2, 3, ... } are linearly independent, and every function f that is square-integrable on [0, 2π] is an "infinite linear combination" of them, in the sense that

for suitable (real or complex) coefficients ak, bk. But many[2] square-integrable functions cannot be represented as finite linear combinations of these basis functions, which therefore do not comprise a Hamel basis. Every Hamel basis of this space is much bigger than this merely countably infinite set of functions. Hamel bases of spaces of this kind are typically not useful, whereas orthonormal bases of these spaces are essential in Fourier analysis.
Geometry
The geometric notions of an affine space, projective space, convex set, and cone have related notions of basis.[3] An affine basis for an n-dimensional affine space is points in general linear position. A projective basis is points in general position, in a projective space of dimension n. A convex basis of a polytope is the set of the vertices of its convex hull. A cone basis[4] consists of one point by edge of a polygonal cone. See also a Hilbert basis (linear programming).


Random basis
Consider a probability distribution in Rn, which admits probability density function (for example, the equidistribution in a n-dimensional ball with respect to Lebesgue measure). Randomly and independently chosen n vectors form a basis with probability one because n linearly dependent vectors x1,..., xn in Rn should satisfy the equation det[x1,..., xn]=0 (zero determinant of the matrix with columns xi), and the set of zeros of a non-trivial polynomial has zero measure. This simple observation gave rise to various techniques of approximation in random bases.[5][6]
It is difficult to check numerically the linear dependence or exact orthogonality. Therefore, the notion of ε-orthogonality is used. For spaces with inner product, x is ε-orthogonal to y if (that is, cosine of the angle between x and y is less than ε).

In high dimensions, two independent random vectors are with high probability almost orthogonal, and the number of independent random vectors, which all are with given high probability pairwise almost orthogonal, grows exponentially with dimension. More precisely, consider equidistribution in n-dimensional ball. Choose N independent random vectors from a ball (they are independent and identically distributed). Let θ be a small positive number. Then for
-
(Eq. 1)
![{\displaystyle N\leq e^{\frac {\epsilon ^{2}n}{4}}[-\ln(1-\theta )]^{\frac {1}{2}}}](../I/m/cfd697c7e7ddeb2ad4bdc6e5617752f07c76676c.svg)
N random vectors are all pairwise ε-orthogonal with probability 1-θ.[6] This N growth exponentially with dimension n and for sufficiently big n. This property of random bases is a manifestation of the so-called measure concentration phenomenon.[7]

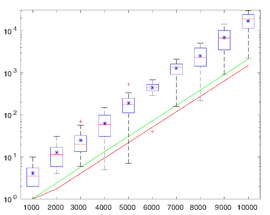
The figure (right) illustrates distribution of lengths N of pairwise almost orthogonal chains of vectors that are independently randomly sampled from the n-dimensional cube [−1,1]n as a function of dimension, n. A point is first randomly selected in the cube. The second point is randomly chosen in the same cube. If the angle between the vectors was within π/2 ±0.037π/2 then the vector was retained. At the next step a new vector is generated in the same hypercube, and its angles with the previously generated vectors are evaluated. If these angles are within π/2 ±0.037π/2 then the vector is retained. The process is repeated until the chain of almost orthogonality breaks, and the number of such pairwise almost orthogonal vectors (length of the chain) is recorded. For each n, 20 pairwise almost orthogonal chains where constructed numerically for each dimension. Distribution of the length of these chains is presented.
Proof that every vector space has a basis
Let V be any vector space over some field F. Every vector space must contain at least one element: the zero vector 0.
If V = {0}, then the empty set is a basis for V (the empty set indeed spans V, due to the empty sum convention, and is linearly independent). Thus, it remains only to consider the case where V contains at least one nonzero element, say v.
Let X be the set of all linear independent subsets of V. It contains the singleton L = {v}, which is necessarily linearly independent. Hence X is nonempty.
The set X is partially ordered by inclusion, which is denoted, as usual by ⊆.
Let Y be a subset of X that is totally ordered by ⊆, then the union LY of all the elements of Y (which are themselves certain subsets of V) is an upper bound for Y. This means that LY is linearly independent and thus belongs to X, and that every element L of Y satisfies L ⊆ LY. Both assertions are easy to check.
As X is nonempty, and every totally ordered subset of (X, ⊆) has an upper bound, Zorn's lemma asserts that X has a maximal element. In other words, there exists some element Lmax of X satisfying the condition that whenever Lmax ⊆ L for some element L of X, then L = Lmax.
It remains to prove that Lmax is a basis of V. Since Lmax belong to X, we already know that Lmax is a linearly independent subset of V.
If Lmax would not span V, there would exist some vector w of V that cannot be expressed as a linearly combination of elements of Lmax (with coefficients in the field F). In particular, w cannot be an element of Lmax. Let Lw = Lmax ∪ {w}. This set is an element of X, that is, it is a linearly independent subset of V (because w is not in the span of Lmax). As Lmax ⊆ Lw, and Lmax ≠ Lw (because Lw contains the vector w that is not contained in Lmax), this contradicts the maximality of Lmax. Thus this shows that Lmax spans V.
Hence Lmax is linearly independent and spans V. It is thus a basis of V, and this proves that every vector space has a basis.
This proof relies on Zorn's lemma, which is equivalent to the axiom of choice. Conversely, it may be proved that if every vector space has a basis, then the axiom of choice is true; thus the two assertions are equivalent.
See also
Notes
- ↑ Halmos, Paul Richard (1987) Finite-dimensional vector spaces (4th edition) Springer-Verlag, New York, page 10, ISBN 0-387-90093-4
- ↑ Note that one cannot say "most" because the cardinalities of the two sets (functions that can and cannot be represented with a finite number of basis functions) are the same.
- ↑ Notes on geometry, by Elmer G. Rees, p. 7
- ↑ Some remarks about additive functions on cones, Marek Kuczma
- ↑ B. Igelnik , Y.-H. Pao , Stochastic choice of basis functions in adaptive function approximation and the functional-link net, IEEE Trans. Neural Netw. 6 (6) (1995) 1320–1329.
- 1 2 3 A.N. Gorban, I.Yu. Tyukin, D.V. Prokhorov, K.I. Sofeikov, Approximation with Random Bases: Pro et Contra, Information Sciences, 364–365 (2016), 129-145.
- ↑ S. Artstein, Proportional concentration phenomena of the sphere, Israel J. Math. 132 (2002) 337–358.
References
General references
- Blass, Andreas (1984), "Existence of bases implies the axiom of choice", Axiomatic set theory, Contemporary Mathematics volume 31, Providence, R.I.: American Mathematical Society, pp. 31–33, ISBN 0-8218-5026-1, MR 763890
- Brown, William A. (1991), Matrices and vector spaces, New York: M. Dekker, ISBN 978-0-8247-8419-5
- Lang, Serge (1987), Linear algebra, Berlin, New York: Springer-Verlag, ISBN 978-0-387-96412-6
Historical references
- Banach, Stefan (1922), "Sur les opérations dans les ensembles abstraits et leur application aux équations intégrales (On operations in abstract sets and their application to integral equations)" (PDF), Fundamenta Mathematicae (in French), 3, ISSN 0016-2736
- Bolzano, Bernard (1804), Betrachtungen über einige Gegenstände der Elementargeometrie (Considerations of some aspects of elementary geometry) (in German)
- Bourbaki, Nicolas (1969), Éléments d'histoire des mathématiques (Elements of history of mathematics) (in French), Paris: Hermann
- Dorier, Jean-Luc (1995), "A general outline of the genesis of vector space theory", Historia Mathematica, 22 (3): 227–261, doi:10.1006/hmat.1995.1024, MR 1347828
- Fourier, Jean Baptiste Joseph (1822), Théorie analytique de la chaleur (in French), Chez Firmin Didot, père et fils
- Grassmann, Hermann (1844), Die Lineale Ausdehnungslehre - Ein neuer Zweig der Mathematik (in German), reprint: Hermann Grassmann. Translated by Lloyd C. Kannenberg. (2000), Extension Theory, Kannenberg, L.C., Providence, R.I.: American Mathematical Society, ISBN 978-0-8218-2031-5
- Hamilton, William Rowan (1853), Lectures on Quaternions, Royal Irish Academy
- Möbius, August Ferdinand (1827), Der Barycentrische Calcul : ein neues Hülfsmittel zur analytischen Behandlung der Geometrie (Barycentric calculus: a new utility for an analytic treatment of geometry) (in German), archived from the original on 2009-04-12
- Moore, Gregory H. (1995), "The axiomatization of linear algebra: 1875–1940", Historia Mathematica, 22 (3): 262–303, doi:10.1006/hmat.1995.1025
- Peano, Giuseppe (1888), Calcolo Geometrico secondo l'Ausdehnungslehre di H. Grassmann preceduto dalle Operazioni della Logica Deduttiva (in Italian), Turin
External links
- Instructional videos from Khan Academy
- "Linear combinations, span, and basis vectors". Essence of linear algebra. August 6, 2016 – via YouTube.
- Hazewinkel, Michiel, ed. (2001), "Basis", Encyclopedia of Mathematics, Springer, ISBN 978-1-55608-010-4