Eurasiatic languages
| Eurasiatic | |
|---|---|
| (controversial) | |
| Geographic distribution: | Before the 16th century, most of Eurasia; today worldwide |
| Linguistic classification: |
Nostratic (?)
|
| Subdivisions: |
|
| Glottolog: | None |
|
The worldwide distribution of the Eurasiatic macrofamily of languages according to Pagel et al. | |
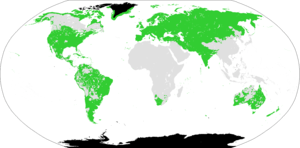
Eurasiatic is a proposed language macrofamily that would include many language families historically spoken in northern, western, and southern Eurasia.
The idea of a Eurasiatic superfamily dates back more than 100 years. Joseph Greenberg's proposal, dating to the 1990s, is the most widely discussed version. In 2013, Mark Pagel and three colleagues published what they believe to be statistical evidence for a Eurasiatic language family.
The branches of Eurasiatic vary between proposals, but typically include Altaic (in the form of Mongolic, Tungusic and Turkic), Chukchi-Kamchatkan, Eskimo–Aleut, Indo-European, and Uralic—although Greenberg uses the controversial Uralic-Yukaghir classification instead. Other branches sometimes included are the Kartvelian and Dravidian families, as proposed by Pagel et al., in addition to the language isolates Nivkh, Etruscan and Greenberg's "Korean-Japanese-Ainu." Some proposals group Eurasiatic with even larger macrofamilies, such as Nostratic; again, many other professional linguists regard the methods used as invalid.
History of the concept
In 1905, Alfredo Trombetti proposed the group in L'unità d'origine del linguaggio, a work arguing all human language derives from a single source.[1]
In 1994 Merritt Ruhlen claimed Eurasiatic is supported by the existence of a grammatical pattern "whereby plurals of nouns are formed by suffixing -t to the noun root...whereas duals of nouns are formed by suffixing -k." Rasmus Rask noted this grammatical pattern in the groups now called Uralic and Eskimo–Aleut as early as 1818, but it can also be found in Altaic, Nivkh (also called Gilyak) and Chukchi–Kamchatkan—all of which Greenberg placed in Eurasiatic. According to Ruhlen, this pattern is not found in language families or languages outside Eurasiatic.[2]
In 1998, Joseph Greenberg extended his work in mass comparison, a methodology he first proposed in the 1950s to categorize the languages of Africa, to suggest a Eurasiatic language.[1] In 2000, he expanded his argument for Eurasiatic into a full-length book, Indo-European and Its Closest Relatives: The Eurasiatic Language Family, in which he outlines both phonetic and grammatical evidence that he feels demonstrate the validity of language family. The heart of his argument is 72 morphological features that he judges as common across the various language families he examines.[3] Of the many variant proposals, Greenberg's has attracted the most academic attention.[1]
Greenberg's Eurasiatic hypothesis has been dismissed by many linguists, often on the ground that his research on mass comparison is unreliable. The primary criticism of comparative methods is that cognates are assumed to have a common origin on the basis of similar sounds and word meanings. It is generally assumed that semantic and phonetic corruption destroys any trace of original sound and meaning within 5,000 to 9,000 years making the application of comparative methods to ancient superfamilies highly questionable. Additionally, apparent cognates can arise by chance or from loan words. Without the existence of statistical estimates of chance collisions, conclusions based on comparison alone are thus viewed as doubtful.[4]
Stefan Georg and Alexander Vovin, who, unlike many of their colleagues, do not stipulate a priori that attempts to find ancient relationships are bound to fail, examined Greenberg's claims in detail.[5] They state that Greenberg's morphological arguments are the correct approach to determining families, but doubt his conclusions. They write "[Greenberg's] 72 morphemes look like massive evidence in favour of Eurasiatic at first glance. If valid, few linguists would have the right to doubt that a point has been made ... However, closer inspection ... shows too many misinterpretations, errors and wrong analyses ... these allow no other judgement than that [Greenberg's] attempt to demonstrate the validity of his Eurasiatic has failed."[6]
Pagel et al.
In 2013, Mark Pagel, Quentin D. Atkinson, Andreea S. Calude, and Andrew Meadea published statistical evidence that attempts to overcome these objections. According to their earlier work, most words exhibit a "half-life" of between 2,000 and 4,000 years, consistent with existing theories of linguistic replacement. However, they also identified some words – numerals, pronouns, and certain adverbs – that exhibit a much slower rate of replacement with half-lives of 10,000 to 20,000 or more years. Drawing from research in a diverse group of modern languages, the authors were able to show the same slow replacement rates for key words regardless of current pronunciation. They conclude that a stable core of largely unchanging words is a common feature of all human discourse, and model replacement as inversely proportional to usage frequency.[4]
Pagel et al. used hypothesized reconstructions of proto-words from seven language families listed in the Languages of the World Etymological Database (LWED).[4] They limited their search to the 200 most common words as described by the Swadesh fundamental vocabulary list. Twelve words were excluded because proto-words had been proposed for two or fewer language families. The remaining 188 words yielded 3804 different reconstructions (sometimes with multiple constructions for a given family). In contrast to traditional comparative linguistics, the researchers did not attempt to "prove" any given pairing as cognates (based on similar sounds), but rather treat each pairing as treated as a binary random variable subject to error. The set of possible cognate pairings was then analyzed as a whole for predictable regularities.[7]
Words were separated by into groupings based on how many language families appeared to be cognate for the word. Among the 188 words, cognate groups ranged from 1 (no cognates) to 7 (all languages cognate) with a mean of 2.3 ± 1.1. The distribution of cognate class size was positively skewed − many more small groups than large ones − as predicted by their hypothesis of variant decay rates.[7] Words were then grouped by their generalized worldwide frequency of use, part of speech, and previously estimated rate of replacement. Cognate class size was positively correlated with estimated replacement rate (r=0.43, P<0.001). Generalized frequency combined with part of speech was also a strong predictor of class size (r=0.48, P<0.001). Pagel et al. conclude "This result suggests that, consistent with their short estimated half-lives, infrequently used words typically do not exist long enough to be deeply ancestral, but that above the threshold frequency words gain greater stability, which then translates into larger cognate class sizes."[8]
Twenty-three word meanings[A] had cognate class sizes of four or more.[8] Words used more than once per 1,000 spoken words (χ2=24.29, P<0.001), pronouns (χ2=26.1, P<0.0001), and adverbs (χ2=14.5, P=0.003) were over-representing among those 23 words. Frequently used words, controlled for part of speech, were 7.5 times more likely (P<0.001) than infrequently used words to be judged as cognate. These findings matched their a priori predictions about word classes more likes to retain sound and meaning over long periods of time.[9] The authors write "Our ability to predict these words independently of their sound correspondences dilutes the usual criticisms leveled at such long-range linguistic reconstructions, that proto-words are unreliable or inaccurate, or that apparent phonetic similarities among them reflect chance sound resemblances." On the first point, they argue that inaccurate reconstructions should weaken, not enhance, the signals. On the second, they argue that chance resemblances should be equally common across all word usage frequencies, in contrast to what the data shows.[10]
The team then created a Markov chain Monte Carlo simulation to estimate and date the phylogenetic trees of the seven language families under examination. Five separate runs produced the same (unrooted) tree, with three sets of language families: an eastern grouping of Altaic, Inuit-Yupik, and Chukchi-Kamchatkan; a central and southern Asia grouping of Kartvelian and Dravidian; and a northern and western European grouping of Indo-European and Uralic.[9] Two rootings were considered, using established age estimates for Proto-Indo-European and Proto-Chukchi-Kamchatkan as calibration.[11] The first roots the tree to the midpoint of the branch leading to proto-Dravidian and yields an estimated origin for Eurasiatic of 14450 ± 1750 years ago. The second roots to tree to the proto-Kartvelian branch and yields 15610 ± 2290 years ago. Internal nodes have less certainty, but exceed chance expectations, and do not affect the top-level age estimate. The authors conclude "All inferred ages must be treated with caution but our estimates are consistent with proposals linking the near concomitant spread of the language families that comprise this group to the retreat of glaciers in Eurasia at the end of the last ice age ∼15,000 years ago.[9]
Many academics specializing in historical linguistics via the comparative method are skeptical of the conclusions of the paper, and critical of its assumptions and methodology.[12] Writing on University of Pennsylvania blog Language Log, Sarah Thomason questions the accuracy of the LWED data on which the paper was based. She notes that LWED lists multiple possible proto-word reconstructions for most words, increasing the possibility of chance matches.[13] Pagel et al.. anticipated this criticism and state that since infrequently used words generally have more proposed reconstructions, such errors should "produce a bias in the opposite direction" of what the statistics actual shows (i.e. that infrequently used words should have larger cognate groups if chance alone was the source).[14] Thomason also argues that since the LWED is contributed to primarily by believers in Nostratic, a proposed superfamily even broader than Eurasiatic, the data is likely to be biased towards proto-words that can be judged cognate.[13] Pagel et al.. admit they "cannot rule out this bias" but say they think it is unlikely bias has systematically impacted their results. They argue certain word types generally believed to be long lived (e.g. numbers) do not appear on their 23 word list, while other words of relatively low importance in modern society, but important to ancient people do appear on the list (e.g. bark and ashes), thus casting doubt on bias being the cause of the apparent cognates.[10] Thomason says she is "unqualified" to comment on the statistics themselves, but says any model that uses bad data as input cannot provide reliable results.[13]
Asya Pereltsvaig takes a different approach to her critique of the paper. Outlining the history (in English) of several of the words on the Pagel list, she concludes it is impossible that such words could have retained any sound and meaning pairings from 15,000 years ago given how much they have changed in the 1,500 or so year attested history of English. She also states that the authors are "looking in the wrong place" to begin with since "grammatical properties are more reliable than words as indicators of familial relationships".[15]
Pagel et al. also examined two other possible objections to their conclusions. They rule out linguistic borrowing as a significant factor in the results on the basis that for a word to appear cognate in many language families solely because of borrowing would require frequent swapping back and forth. This is deemed unlikely because of the large geographical area covered by the language groups and because frequently used words are the least likely to be borrowed in modern times.[10] Finally, they state that leaving aside closed class words with simple phonologies (e.g. I and we) does not affect their conclusions.[16]
Classification
According to Greenberg, the language family that Eurasiatic is most closely connected to is Amerind. He states that "the Eurasiatic-Amerind family represents a relatively recent expansion (circa 15,000 years ago) into territory opened up by the melting of the Arctic ice cap".[17] In contrast, "Eurasiatic-Amerind stands apart from the other families of the Old World, among which the differences are much greater and represent deeper chronological groupings". Like Eurasiatic, Amerind is not a generally accepted proposal.[18]
Eurasiatic and another proposed macrofamily Nostratic often include many of the same language families. Vladislav Illich-Svitych's Nostratic dictionary did not include the smaller Siberian language families listed in Eurasiatic, but this was only because protolanguages had not been reconstructed for them; Nostraticists have not attempted to exclude these languages from Nostratic. Many Nostratic theorists have accepted Eurasiatic as a subgroup within Nostratic alongside Afroasiatic, Kartvelian, and Dravidian.[19] LWED likewise views Eurasiatic as a subfamily of Nostratic.[1] The Nostratic family is not endorsed by the mainstream of comparative linguistics.
Harold C. Fleming includes Eurasiatic as a subgroup of the hypothetical Borean family.[20]
Subdivisions
The subdivisioning of Eurasiatic varies by proposal, but usually includes Micro-Altaic, Chukchi-Kamchatkan, Eskimo–Aleut, Indo-European, and Uralic. The status of Altaic is unclear — some accept it as a valid grouping of Turkic, Mongolic, Tungusic (i.e. Micro-Altaic); others accept it with these three groups plus Koreanic and/or Japonic languages (i.e. Macro-Altaic); others reject the classification entirely.[1] The other four families are widely accepted.
Greenberg enumerates eight branches of Eurasiatic, as follows: Altaic, Chukchi-Kamchatkan, Eskimo–Aleut, Etruscan, Indo-European, "Korean-Japanese-Ainu", Nivkh, and Uralic–Yukaghir.[21] He then breaks these families into smaller sub-groups, some of which are themselves not widely accepted as widely phylogenetic groupings.
Pagel et al. use a slightly different branching, listing seven language families: Altaic (Mongolic, Tungusic, Turkic), Chukchi-Kamchatkan, Dravidian, "Inuit-Yupik"—which is a name giving to LWED grouping of Inuit (Eskimo) languages that does not include Aleut—Indo-European, Kartvelian, and Uralic.[4]
Murray Gell-Mann, Ilia Peiros, and Georgiy Starostin group Chukotko-Kamchatkan and Nivkh with Almosan instead of Eurasiatic.[22]
Regardless of version, these lists cover the languages spoken in most of Europe, Central and Northern Asia and (in the case of Eskimo-Aleut) on either side of the Bering strait.
The branching of Eurasiatic is roughly (following Greenberg):
- Indo-European (unity undisputed)
- Uralic (unity undisputed)
- Yukaghir (sometimes grouped under Paleosiberian, linked to Uralic by Greenberg)
- Paleosiberian (sub-grouping almost universally considered a term of convenience; members are considered Eurasiatic regardless of subgroup's validity)
- Nivkh (a language isolate; placed under Palaeo-Siberian by Starostin, not always included even within Nostratic)
- Eskimo–Aleut (unity disputed)
- Chukotko-Kamchatkan (Chukotian) (unity disputed)
- Macro-Altaic (controversial; Roy Andrew Miller 1971, Gustaf John Ramstedt 1952, Matthias Castrén 1844); "Macro-Altaic" has less scholarly acceptance than "Micro-Altaic" or Altaic proper, uniting only Turkic, Mongolic and Tungusic
- Micro-Altaic (unity disputed)
- "Korean-Japanese-(Ainu)" (see classification of Japonic); most Altaicists consider Japanese and Korean Altaic.
- Tyrsenian (grouping of three closely related extinct languages; their affiliation with Eurasiatic, based primarily on "mi" first person singular, is highly speculative given lack of attestation)
Geographical distribution
Merritt Ruhlen suggests that the geographical distribution of Eurasiatic shows that it and the Dené–Caucasian family are the result of separate migrations. Dené–Caucasian is the older of the two groups, with the emergence of Eurasiatic being more recent. The Eurasiatic expansion overwhelmed Dené–Caucasian, leaving speakers of the latter restricted mainly to isolated pockets (the Basques in the Pyrenees mountains, Caucasian peoples in the Caucasus mountains, and the Burushaski in the Hindu Kush mountains) surrounded by Eurasiatic speakers. Dené–Caucasian survived in these areas because they were difficult to access and therefore easy to defend; the reasons for its survival elsewhere are unclear. Ruhlen argues that Eurasiatic is supported by stronger and clearer evidence than Dené–Caucasian, and that this also indicates that the spread of Dené–Caucasian occurred before that of Eurasiatic.[2]
The existence of a Dené–Caucasian family is disputed or rejected by some linguists, including Lyle Campbell,[23] Ives Goddard,[24] and Larry Trask.[25]
The last common ancestor of the family was estimated by phylogenetic analysis of ultraconserved words at roughly 15,000 years old, suggesting that these languages spread from a "refuge" area at the Last Glacial Maximum.[9]
See also
- Indo-Semitic languages
- Indo-Uralic languages
- Proto-Human language
- Ural–Altaic languages
- Uralo-Siberian languages
Notes
^A The 23 words are (listed in order of cognate class size): Thou (7 cognates), I (6), Not, That, To give, We, Who (5), Ashes, Bark, Black, Fire, Hand, Male/man, Mother, Old, This, To flow, To hear, To pull, To spit, What, Worm, Ye (4)[9]
- 1 2 3 4 5 Pagel et al.. (SI), p. 1
- 1 2 Ruhlen
- ↑ Georg and Vovin, p. 335
- 1 2 3 4 Pagel et al., p. 1
- ↑ Georg and Vovin, p. 334
- ↑ Georg and Vovin, p. 336
- 1 2 Pagel et al., p. 2
- 1 2 Pagel et al., p. 3
- 1 2 3 4 5 Pagel et al., p. 4
- 1 2 3 Pagel et al., p. 5
- ↑ Pagel et al.. (SI), pp. 2-3
- ↑ "This is a case of correlation in, correlation out - proving nothing." Ultraconserved words and Eurasiatic? The "faces in the fire" of language prehistory. Paul Heggarty. Proceedings of the National Academy of Sciences of the United States of America August 5, 2013, doi: 10.1073/pnas.1309114110 http://www.pnas.org/content/early/2013/08/01/1309114110.extract accessed 5th November 2013
- 1 2 3 Thomason
- ↑ Pagel et al.. (SI), pp. 3-4
- ↑ Pereltsvaig
- ↑ Pagel et al., p. 6
- ↑ Greenberg (2002), p. 2
- ↑ Campbell; Goddard; Mithun
- ↑ Greenberg (2005), p. 331
- ↑ Fleming
- ↑ Greenberg (2000), p. 279-81
- ↑ Gell-Mann et al., pp. 13–30
- ↑ Campbell, pp. 286-288
- ↑ Goddard, p. 318
- ↑ Trask, p. 85
References
- Campbell, Lyle (1997). American Indian Languages: The Historical Linguistics of Native America. Oxford: Oxford University Press.
- Gell-Mann, Murray; Ilia Peiros; George Starostin (2009). "Distant Language Relationship: The Current Perspective" (PDF). Journal of Language Relationship (01).
- Harold Fleming. "Afrasian and Its Closest Relatives: the Borean Hypothesis".
- Georg, Stefan; Alexander Vovin (2003). "From mass comparison to mess comparison: Greenberg's 'Eurasiatic' theory". Diachronica. 20 (2).
- Goddard, Ives (1996). ""The Classification of the Native Languages of North America"". In William Sturtevant. Languages (Handbook of North American Indians Vol. 17). Washington, D.C.: Smithsonian Institution.
- Greenberg, Joseph H. 1957. Essays in Linguistics. Chicago: University of Chicago Press.
- Greenberg, Joseph H. 2000. Indo-European and Its Closest Relatives: The Eurasiatic Language Family. Volume 1, Grammar. Stanford: Stanford University Press.
- Greenberg, Joseph H. 2002. Indo-European and Its Closest Relatives: The Eurasiatic Language Family. Volume 2, Lexicon. Stanford: Stanford University Press.
- Greenberg, Joseph H. 2005. Genetic Linguistics: Essays on Theory and Method, edited by William Croft. Oxford: Oxford University Press.
- Mithun, Marianne. 1999. The Languages of Native North America. Cambridge: Cambridge University Press.
- Nichols, Johanna. 1992. Linguistic Diversity in Space and Time. Chicago: University of Chicago Press.
- Pagel, Mark; Quentin D. Atkinson; Andreea S. Calude; Andrew Meadea (May 6, 2013). "Ultraconserved words point to deep language ancestry across Eurasia" (PDF). PNAS. 110: 8471–8476. doi:10.1073/pnas.1218726110. Retrieved May 8, 2013.
- Pagel, Mark; Quentin D. Atkinson; Andreea S. Calude; Andrew Meadea (May 6, 2013). "Supporting Information (for Ultraconserved words point to deep language ancestry across Eurasia)" (PDF). PNAS. 110: 8471–8476. doi:10.1073/pnas.1218726110. Retrieved May 8, 2013.
- Ruhlen, Merritt (1994). The Origin of Language: Tracing the Evolution of the Mother Tongue. New York: John Wiley & Sons, Inc.
- Pereltsvaig, Asya (May 10, 2013). "Do 'Ultraconserved Words' Reveal Linguistic Macro-Families?". GeoCurrents. Retrieved May 11, 2013.
- Thomason, Sally (May 8, 2013). "Ultraconserved words? Really??". Language Log. Retrieved May 8, 2013.
- Trask, Larry (2000). The Dictionary of Historical and Comparative Linguistics. Edinburgh: Edinburgh University Press.
External links
- "Indo-Uralic and Altaic" by Frederik Kortlandt (2006)
- Regions Based on Social Structure: A Reconsideration