p-value
In statistics, the p-value is the probability that, using a given statistical model, the statistical summary (such as the sample mean difference between two compared groups) would be the same as or more extreme than the actual observed results.[1] Statistical hypothesis testing making use of p-values is commonly used in many fields of research[2] such as economics, political science, psychology,[3] biology, criminal justice, criminology, and sociology.[4] Their misuse has been a matter of considerable controversy.
Overview and controversy
The p-value is defined as the probability of obtaining a result equal to or "more extreme" than what was actually observed, when the null hypothesis is true.[5][6]
In frequentist inference, the p-value is widely used in statistical hypothesis testing, specifically in null hypothesis significance testing. In this method, as part of experimental design, before performing the experiment, one first chooses a model (the null hypothesis) and a threshold value for p, called the significance level of the test, traditionally 5% or 1% [7] and denoted as α. If the p-value is less than or equal to the chosen significance level (α), the test suggests that the observed data is inconsistent with the null hypothesis, so the null hypothesis must be rejected. However, that does not prove that the tested hypothesis is true. When the p-value is calculated correctly, this test guarantees that the Type I error rate is at most α. For typical analysis, using the standard α = 0.05 cutoff, the null hypothesis is rejected when p < .05 and not rejected when p > .05. The p-value does not, in itself, support reasoning about the probabilities of hypotheses but is only a tool for deciding whether to reject the null hypothesis.
The American Statistical Association, in a statement on the use of p-values,[8] affirmed the usefulness of properly interpreted p-values, but cautioned that p-values are "commonly misused and misinterpreted." The use of bright-line rules as cutoffs, such as p ≤ 0.05, without other supporting statistical evidence, was particularly criticized:[8]
The widespread use of “statistical significance” (generally interpreted as “p ≤ 0.05”) as a license for making a claim of a scientific finding (or implied truth) leads to considerable distortion of the scientific process.
While there is widespread agreement that p-values are often misused,[9][10] there is no consensus on alternatives.[11]
Basic concepts
The p-value is used in the context of null hypothesis testing in order to quantify the idea of statistical significance of evidence.[lower-alpha 1] Null hypothesis testing is a reductio ad absurdum argument adapted to statistics. In essence, a claim is shown to be valid by demonstrating the improbability of the consequence that results from assuming the counter-claim to be true.
As such, the only hypothesis that needs to be specified in this test and which embodies the counter-claim is referred to as the null hypothesis. A result is said to be statistically significant if it allows us to reject the null hypothesis. That is, as per the reductio ad absurdum reasoning, the statistically significant result should be highly improbable if the null hypothesis is assumed to be true. The rejection of the null hypothesis implies that the correct hypothesis lies in the logical complement of the null hypothesis. However, unless there is a single alternative to the null hypothesis, the rejection of null hypothesis does not tell us which of the alternatives might be the correct one.
For instance, if the null hypothesis is assumed to be a standard normal distribution N(0,1), the rejection of this null hypothesis can either mean (i) the mean is not zero, or (ii) the variance is not unity, or (iii) the distribution is not normal, depending on the type of test performed. However, supposing we manage to reject the zero mean hypothesis, even if we know the distribution is normal and variance is unity, the null hypothesis test does not tell us which non-zero value we should adopt as the new mean.
In statistics, a statistical hypothesis refers to a probability distribution that is assumed to govern the observed data.[lower-alpha 2] If is a random variable representing the observed data and is the statistical hypothesis under consideration, then the notion of statistical significance can be naively quantified by the conditional probability , which gives the likelihood of the observation if the hypothesis is assumed to be correct. However, if is a continuous random variable and an instance is observed, Thus, this naive definition is inadequate and needs to be changed so as to accommodate the continuous random variables.





Nonetheless, it helps to clarify that p-values should not be confused with probability on hypothesis (as is done in Bayesian Hypothesis Testing) such as the probability of the hypothesis given the data, or the probability of the hypothesis being true, or the probability of observing the given data.



Definition and interpretation
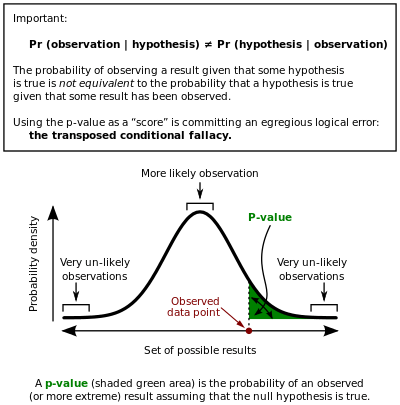
The p-value is defined as the probability, under the assumption of hypothesis , of obtaining a result equal to or more extreme than what was actually observed. Depending on how it is looked at, the "more extreme than what was actually observed" can mean (right-tail event) or (left-tail event) or the "smaller" of and (double-tailed event). Thus, the p-value is given by


- for right tail event,
- for left tail event,
- for double tail event.



The smaller the p-value, the larger the significance because it tells the investigator that the hypothesis under consideration may not adequately explain the observation. The hypothesis is rejected if any of these probabilities is less than or equal to a small, fixed but arbitrarily pre-defined threshold value , which is referred to as the level of significance. Unlike the p-value, the level is not derived from any observational data and does not depend on the underlying hypothesis; the value of is instead determined by the consensus of the research community that the investigator is working in.

Since the value of that defines the left tail or right tail event is a random variable, this makes the p-value a function of and a random variable in itself defined uniformly over interval, assuming is continuous. Thus, the p-value is not fixed. This implies that p-value cannot be given a frequency counting interpretation since the probability has to be fixed for the frequency counting interpretation to hold. In other words, if the same test is repeated independently bearing upon the same overall null hypothesis, it will yield different p-values at every repetition. Nevertheless, these different p-values can be combined using Fisher's combined probability test. It should further be noted that an instantiation of this random p-value can still be given a frequency counting interpretation with respect to the number of observations taken during a given test, as per the definition, as the percentage of observations more extreme than the one observed under the assumption that the null hypothesis is true.
![[0,1]](../I/m/738f7d23bb2d9642bab520020873cccbef49768d.svg)
The fixed pre-defined level can be interpreted as the rate of falsely rejecting the null hypothesis (or type I error), since
- .

This also means that if we fix an instantiation of p-value and allow to vary over , we can obtain an equivalent interpretation of p-value in terms of level as the lowest value of that can be assumed for which the null hypothesis can be rejected for a given set of observations. Obviously, assuming an smaller than the instantiated p-value will end up not rejecting the null hypothesis.
Calculation
Usually, instead of the actual observations, is instead a test statistic. A test statistic is a scalar function of all the observations, such as the average or the correlation coefficient, which summarizes the characteristics of the data by a single number, relevant to a particular inquiry. As such, the test statistic follows a distribution determined by the function used to define that test statistic and the distribution of the input observational data.
For the important case in which the data are hypothesized to follow the normal distribution, depending on the nature of the test statistic and thus the underlying hypothesis of the test statistic, different null hypothesis tests have been developed. Some such tests are z-test for normal distribution, t-test for Student's t-distribution, f-test for f-distribution. When the data do not follow a normal distribution, it can still be possible to approximate the distribution of these test statistics by a normal distribution by invoking the central limit theorem for large samples, as in the case of Pearson's chi-squared test.
Thus computing a p-value requires a null hypothesis, a test statistic (together with deciding whether the researcher is performing a one-tailed test or a two-tailed test), and data. Even though computing the test statistic on given data may be easy, computing the sampling distribution under the null hypothesis, and then computing its cumulative distribution function (CDF) is often a difficult computation. Today, this computation is done using statistical software, often via numeric methods (rather than exact formulae), but in the early and mid 20th century, this was instead done via tables of values, and one interpolated or extrapolated p-values from these discrete values. Rather than using a table of p-values, Fisher instead inverted the CDF, publishing a list of values of the test statistic for given fixed p-values; this corresponds to computing the quantile function (inverse CDF).
Examples
Here a few simple examples follow, each illustrating a potential pitfall.
One roll of a pair of dice
Suppose a researcher rolls a pair of dice once and assumes a null hypothesis that the dice are fair, not loaded or weighted toward any specific number/roll/result; uniform. The test statistic is "the sum of the rolled numbers" and is one-tailed. The researcher rolls the dice and observes that both dice show 6, yielding a test statistic of 12. The p-value of this outcome is 1/36 (because under the assumption of the null hypothesis, the test statistic is uniformly distributed) or about 0.028 (the highest test statistic out of 6×6 = 36 possible outcomes). If the researcher assumed a significance level of 0.05, this result would be deemed significant and the hypothesis that the dice are fair would be rejected.
In this case, a single roll provides a very weak basis (that is, insufficient data) to draw a meaningful conclusion about the dice. This illustrates the danger with blindly applying p-value without considering the experiment design.
Five heads in a row
Suppose a researcher flips a coin five times in a row and assumes a null hypothesis that the coin is fair. The test statistic of "total number of heads" can be one-tailed or two-tailed: a one-tailed test corresponds to seeing if the coin is biased towards heads, but a two-tailed test corresponds to seeing if the coin is biased either way. The researcher flips the coin five times and observes heads each time (HHHHH), yielding a test statistic of 5. In a one-tailed test, this is the most extreme value out of all possible outcomes, and yields a p-value of (1/2)5 = 1/32 ≈ 0.03. If the researcher assumed a significance level of 0.05, this result would be deemed significant and the hypothesis that the coin is fair would be rejected. In a two-tailed test, a test statistic of zero heads (TTTTT) is just as extreme and thus the data of HHHHH would yield a p-value of 2×(1/2)5 = 1/16 ≈ 0.06, which is not significant at the 0.05 level.
This demonstrates that specifying a direction (on a symmetric test statistic) halves the p-value (increases the significance) and can mean the difference between data being considered significant or not.
Sample size dependence
Suppose a researcher flips a coin some arbitrary number of times (n) and assumes a null hypothesis that the coin is fair. The test statistic is the total number of heads and is a two-tailed test. Suppose the researcher observes heads for each flip, yielding a test statistic of n and a p-value of 2/2n. If the coin was flipped only 5 times, the p-value would be 2/32 = 0.0625, which is not significant at the 0.05 level. But if the coin was flipped 10 times, the p-value would be 2/1024 ≈ 0.002, which is significant at the 0.05 level.
In both cases the data suggest that the null hypothesis is false (that is, the coin is not fair somehow), but changing the sample size changes the p-value. In the first case, the sample size is not large enough to allow the null hypothesis to be rejected at the 0.05 level (in fact, the p-value can never be below 0.05 for the coin example).
This demonstrates that in interpreting p-values, one must also know the sample size, which complicates the analysis.
Alternating coin flips
Suppose a researcher flips a coin ten times and assumes a null hypothesis that the coin is fair. The test statistic is the total number of heads and is two-tailed. Suppose the researcher observes alternating heads and tails with every flip (HTHTHTHTHT). This yields a test statistic of 5 and a p-value of 1 (completely unexceptional), as that is the expected number of heads.
Suppose instead that the test statistic for this experiment was the "number of alternations" (that is, the number of times when H followed T or T followed H), which is again two-tailed. That would yield a test statistic of 9, which is extreme and has a p-value of . That would be considered extremely significant, well beyond the 0.05 level. These data indicate that, in terms of one test statistic, the data set is extremely unlikely to have occurred by chance, but it does not suggest that the coin is biased towards heads or tails.

By the first test statistic, the data yield a high p-value, suggesting that the number of heads observed is not unlikely. By the second test statistic, the data yield a low p-value, suggesting that the pattern of flips observed is very, very unlikely. There is no "alternative hypothesis" (so only rejection of the null hypothesis is possible) and such data could have many causes. The data may instead be forged, or the coin may be flipped by a magician who intentionally alternated outcomes.
This example demonstrates that the p-value depends completely on the test statistic used and illustrates that p-values can only help researchers to reject a null hypothesis, not consider other hypotheses.
Coin flipping
As an example of a statistical test, an experiment is performed to determine whether a coin flip is fair (equal chance of landing heads or tails) or unfairly biased (one outcome being more likely than the other).
Suppose that the experimental results show the coin turning up heads 14 times out of 20 total flips. The null hypothesis is that the coin is fair, and the test statistic is the number of heads. If a right-tailed test is considered, the p-value of this result is the chance of a fair coin landing on heads at least 14 times out of 20 flips. That probability can be computed from binomial coefficients as
![{\begin{aligned}&\operatorname {Prob} (14{\text{ heads}})+\operatorname {Prob} (15{\text{ heads}})+\cdots +\operatorname {Prob} (20{\text{ heads}})\\&={\frac {1}{2^{20}}}\left[{\binom {20}{14}}+{\binom {20}{15}}+\cdots +{\binom {20}{20}}\right]={\frac {60,\!460}{1,\!048,\!576}}\approx 0.058\end{aligned}}](../I/m/881773374a766f7580f8defe2246c00be0723ea0.svg)
This probability is the p-value, considering only extreme results that favor heads. This is called a one-tailed test. However, the deviation can be in either direction, favoring either heads or tails. The two-tailed p-value, which considers deviations favoring either heads or tails, may instead be calculated. As the binomial distribution is symmetrical for a fair coin, the two-sided p-value is simply twice the above calculated single-sided p-value: the two-sided p-value is 0.115.
In the above example:
- Null hypothesis (H0): The coin is fair, with Prob(heads) = 0.5
- Test statistic: Number of heads
- Level of significance: 0.05
- Observation O: 14 heads out of 20 flips; and
- Two-tailed p-value of observation O given H0 = 2*min(Prob(no. of heads ≥ 14 heads), Prob(no. of heads ≤ 14 heads))= 2*min(0.058, 0.978) = 2*0.058 = 0.115.
Note that the Prob(no. of heads ≤ 14 heads) = 1 - Prob(no. of heads ≥ 14 heads) + Prob(no. of head = 14) = 1 - 0.058 + 0.036 = 0.978; however, symmetry of the binomial distribution makes that an unnecessary computation to find the smaller of the two probabilities. Here, the calculated p-value exceeds 0.05, so the observation is consistent with the null hypothesis, as it falls within the range of what would happen 95% of the time were the coin is in fact fair. Hence, the null hypothesis at the 5% level is not rejected. Although the coin did not fall evenly, the deviation from expected outcome is small enough to be consistent with chance.
However, had one more head been obtained, the resulting p-value (two-tailed) would have been 0.0414 (4.14%). The null hypothesis is rejected when a 5% cut-off is used.
Distribution
When the null hypothesis is true, the probability distribution of the p-value is uniform on the interval [0,1]. By contrast, if the alternative hypothesis is true, the distribution is dependent on sample size and the true value of the parameter being studied.[2][12]
The distribution of p-values for a group of studies is called a p-curve.[13] The curve is affected by four factors: the probability that a study is examining a true hypothesis rather than a false hypothesis, the power of the studies investigating true hypotheses, the Type 1 error rates, and publication bias.[14] A p-curve can be used to assess the reliability of scientific literature, such as by detecting publication bias or p-hacking.[13][15]
History
.jpg)

Computations of p-values date back to the 1770s, where they were calculated by Pierre-Simon Laplace:[16]
In the 1770s Laplace considered the statistics of almost half a million births. The statistics showed an excess of boys compared to girls. He concluded by calculation of a p-value that the excess was a real, but unexplained, effect.
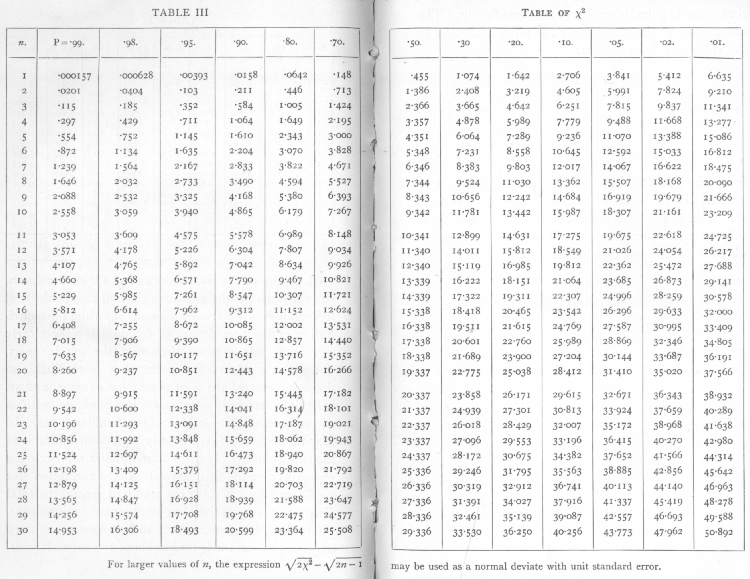
The p-value was first formally introduced by Karl Pearson, in his Pearson's chi-squared test,[17] using the chi-squared distribution and notated as capital P.[17] The p-values for the chi-squared distribution (for various values of χ2 and degrees of freedom), now notated as P, was calculated in (Elderton 1902), collected in (Pearson 1914, pp. xxxi–xxxiii, 26–28, Table XII).
The use of the p-value in statistics was popularized by Ronald Fisher,[18] and it plays a central role in his approach to the subject.[19] In his influential book Statistical Methods for Research Workers (1925), Fisher proposes the level p = 0.05, or a 1 in 20 chance of being exceeded by chance, as a limit for statistical significance, and applies this to a normal distribution (as a two-tailed test), thus yielding the rule of two standard deviations (on a normal distribution) for statistical significance (see 68–95–99.7 rule).[20][lower-alpha 3][21]
He then computes a table of values, similar to Elderton but, importantly, reverses the roles of χ2 and p. That is, rather than computing p for different values of χ2 (and degrees of freedom n), he computes values of χ2 that yield specified p-values, specifically 0.99, 0.98, 0.95, 0,90, 0.80, 0.70, 0.50, 0.30, 0.20, 0.10, 0.05, 0.02, and 0.01.[22] That allowed computed values of χ2 to be compared against cutoffs and encouraged the use of p-values (especially 0.05, 0.02, and 0.01) as cutoffs, instead of computing and reporting p-values themselves. The same type of tables were then compiled in (Fisher & Yates 1938), which cemented the approach.[21]
As an illustration of the application of p-values to the design and interpretation of experiments, in his following book The Design of Experiments (1935), Fisher presented the lady tasting tea experiment,[23] which is the archetypal example of the p-value.
To evaluate a lady's claim that she (Muriel Bristol) could distinguish by taste how tea is prepared (first adding the milk to the cup, then the tea, or first tea, then milk), she was sequentially presented with 8 cups: 4 prepared one way, 4 prepared the other, and asked to determine the preparation of each cup (knowing that there were 4 of each). In that case, the null hypothesis was that she had no special ability, the test was Fisher's exact test, and the p-value was so Fisher was willing to reject the null hypothesis (consider the outcome highly unlikely to be due to chance) if all were classified correctly. (In the actual experiment, Bristol correctly classified all 8 cups.)

Fisher reiterated the p = 0.05 threshold and explained its rationale, stating:[24]
It is usual and convenient for experimenters to take 5 per cent as a standard level of significance, in the sense that they are prepared to ignore all results which fail to reach this standard, and, by this means, to eliminate from further discussion the greater part of the fluctuations which chance causes have introduced into their experimental results.
He also applies this threshold to the design of experiments, noting that had only 6 cups been presented (3 of each), a perfect classification would have only yielded a p-value of which would not have met this level of significance.[24] Fisher also underlined the frequentist interpretation of p, as the long-run proportion of values at least as extreme as the data, assuming the null hypothesis is true.

In later editions, Fisher explicitly contrasted the use of the p-value for statistical inference in science with the Neyman–Pearson method, which he terms "Acceptance Procedures".[25] Fisher emphasizes that while fixed levels such as 5%, 2%, and 1% are convenient, the exact p-value can be used, and the strength of evidence can and will be revised with further experimentation. In contrast, decision procedures require a clear-cut decision, yielding an irreversible action, and the procedure is based on costs of error, which, he argues, are inapplicable to scientific research.
Misunderstandings
Despite the ubiquity of p-value tests, this particular test for statistical significance has been criticized for its inherent shortcomings and the potential for misinterpretation.
The data obtained by comparing the p-value to a significance level will yield one of two results: either the null hypothesis is rejected, or the null hypothesis cannot be rejected at that significance level (which however does not imply that the null hypothesis is true). In Fisher's formulation, there is a disjunction: a low p-value means either that the null hypothesis is true and a highly improbable event has occurred or that the null hypothesis is false. However, people interpret the p-value in many incorrect ways.
The p-value does not in itself allow reasoning about the probabilities of hypotheses, which requires multiple hypotheses or a range of hypotheses, with a prior distribution of likelihoods between them, in which case Bayesian statistics could be used. There, one uses a likelihood function for all possible values of the prior instead of the p-value for a single null hypothesis.
The p-value refers only to a single hypothesis, called the null hypothesis and does not make reference to or allow conclusions about any other hypotheses, such as the alternative hypothesis in Neyman–Pearson statistical hypothesis testing. In that approach, one instead has a decision function between two alternatives, often based on a test statistic, and computes the rate of type I and type II errors as α and β. However, the p-value of a test statistic cannot be directly compared to these error rates α and β. Instead, it is fed into a decision function.
Criticisms
Critics of p-values point out that the criterion used to decide "statistical significance" is based on an arbitrary choice of alpha level (often set at 0.05), and that this criterion leads to an alarming number of false positive tests. The fraction of all “statistically significant” tests in which the null hypothesis is true may be considerably higher than the alpha level, depending on how many of the null hypotheses were false and how much statistical power was used to test them.[26][27][28]
Dividing results into significant and non-significant effects can be highly misleading.[10][10][29] For instance, analysis of nearly identical datasets can result in p-values that differ greatly in significance.[29] In medical research, p-values were a considerable improvement over previous approaches, but misunderstandings of p-values have become more important for reasons such as the increased statistical complexity of published research.[10] It has been suggested that in fields such as psychology, where studies typically have low statistical power, using significance testing can lead to increased error rates.[29][30]
The use of significance testing as the basis for decisions has also been criticized because of the widespread misunderstandings about the process.[10][31][32] For example, p-values do not address the probability of the null hypothesis being true or false, and the choice of significance threshold should not be arbitrary but instead informed by the consequences of a false positive.[29] It is possible to use Bayes factors for calibration, which allows the use of p-values while reducing the impact of the p-value fallacy, although these approaches introduce other biases as well.[33]
The p-value is incompatible with the likelihood principle and depends on the experiment design, the test statistic in question. That is, the definition of "more extreme" data depends on the sampling methodology adopted by the investigator;[34] for example, the situation in which the investigator flips the coin 100 times, yielding 50 heads, has a set of extreme data that is different from the situation in which the investigator continues to flip the coin until 50 heads are achieved yielding 100 flips.[35]
The incompatibility of the p-value with the likelihood principle has been said by some to indicate a lack of conceptual integrity in this methodology since the intentions of the analyst to analyze the data along differing prescriptions (experimental designs, choice of statistic) yield different results for the same data concerning the same underlying question about the coin's fairness. This concern over the issue of consistent reasoning concerning probable inference led Richard Cox to develop an axiomatic basis for probability conditioned on an essential consistency requirement that leads ultimately to Bayes Rule.[36]
Related quantities
A closely related concept is the E-value,[37] which is the expected number of times in multiple testing that one expects to obtain a test statistic at least as extreme as the one that was actually observed if one assumes that the null hypothesis is true. The E-value is the product of the number of tests and the p-value.
Orthographic note
Depending on which style guide is applied, the "p" is styled either italic or not, either capitalized or not, and either hyphenated or not. For example, AMA style uses "P value," APA style uses "p value," and the American Statistical Association uses "p-value."[38]
See also
- Bonferroni correction
- Confidence interval
- Counternull
- False discovery rate
- Fisher's method of combining p-values
- Generalized p-value
- Holm–Bonferroni method
- Multiple comparisons
- Null hypothesis
- p-rep
- p-value fallacy
- Statistical hypothesis testing
Notes
- ↑ Note that the statistical significance of a result does not imply that the result is scientifically significant as well.
- ↑ It should be noted that a statistical hypothesis is conceptually different from a scientific hypothesis.
- ↑ To be precise the p = 0.05 corresponds to about 1.96 standard deviations for a normal distribution (two-tailed test), and 2 standard deviations corresponds to about a 1 in 22 chance of being exceeded by chance, or p ≈ 0.045; Fisher notes these approximations.
References
- ↑ Wasserstein, Ronald L.; Lazar, Nicole A. (7 March 2016). "The ASA's Statement on p-Values: Context, Process, and Purpose". The American Statistician. 70 (2): 129–133. doi:10.1080/00031305.2016.1154108. Retrieved 30 October 2016.
- 1 2 Bhattacharya, Bhaskar; Habtzghi, DeSale (2002). "Median of the p value under the alternative hypothesis". The American Statistician. American Statistical Association. 56 (3): 202–6. doi:10.1198/000313002146. Retrieved 19 February 2016.
- ↑ Wetzels, R.; Matzke, D.; Lee, M. D.; Rouder, J. N.; Iverson, G. J.; Wagenmakers, E. -J. (2011). "Statistical Evidence in Experimental Psychology: An Empirical Comparison Using 855 t Tests". Perspectives on Psychological Science. 6 (3): 291–298. doi:10.1177/1745691611406923.
- ↑ Babbie, E. (2007). The practice of social research 11th ed. Thomson Wadsworth: Belmont, California.
- ↑ Biau 2010.
- ↑ Hubbard, R. (2004). Blurring the Distinctions Between p’s and a’s in Psychological Research, Theory Psychology June 2004 vol. 14 no. 3 295-327
- ↑ Nuzzo, R. (2014). "Scientific method: Statistical errors". Nature. 506 (7487): 150–152. doi:10.1038/506150a.
- 1 2 Wasserstein, Ronald L.; Lazar, Nicole A. (2016). "The ASA's statement on p-values: context, process, and purpose". The American Statistician. doi:10.1080/00031305.2016.1154108.
- ↑ "Scientists Perturbed by Loss of Stat Tool to Sift Research Fudge from Fact". Scientific American. April 16, 2015.
- 1 2 3 4 5 Goodman SN (1999). "Toward evidence-based medical statistics. 1: The P value fallacy.". Annals of Internal Medicine. 130 (12): 995–1004. doi:10.7326/0003-4819-130-12-199906150-00008. PMID 10383371.
- ↑ Aschwanden, Christie (Mar 7, 2016). "Statisticians Found One Thing They Can Agree On: It's Time To Stop Misusing P-Values". FiveThirtyEight.
- ↑ Hung, H.M.J.; O'Neill, R.T.; Bauer, P.; Kohne, K. (1997). "The behavior of the p-value when the alternative hypothesis is true". Biometrics. International Biometric Society. 53 (1): 11–22. doi:10.2307/2533093. JSTOR 2533093.
- 1 2 Head ML, Holman L, Lanfear R, Kahn AT, Jennions MD (2015). "The extent and consequences of p-hacking in science.". PLoS Biol. 13 (3): e1002106. doi:10.1371/journal.pbio.1002106. PMC 4359000
 . PMID 25768323.
. PMID 25768323. - ↑ Lakens D (2015). "What p-hacking really looks like: a comment on Masicampo and LaLande (2012).". Q J Exp Psychol (Hove). 68 (4): 829–32. doi:10.1080/17470218.2014.982664. PMID 25484109.
- ↑ Simonsohn U, Nelson LD, Simmons JP (2014). "p-Curve and Effect Size: Correcting for Publication Bias Using Only Significant Results.". Perspect Psychol Sci. 9 (6): 666–81. doi:10.1177/1745691614553988. PMID 26186117.
- ↑ Stigler 1986, p. 134.
- 1 2 Pearson 1900.
- ↑ Inman 2004.
- ↑ Hubbard & Bayarri 2003, p. 1.
- ↑ Fisher 1925, p. 47, Chapter III. Distributions.
- 1 2 Dallal 2012, Note 31: Why P=0.05?.
- ↑ Fisher 1925, pp. 78–79, 98, Chapter IV. Tests of Goodness of Fit, Independence and Homogeneity; with Table of χ2, Table III. Table of χ2.
- ↑ Fisher 1971, II. The Principles of Experimentation, Illustrated by a Psycho-physical Experiment.
- 1 2 Fisher 1971, Section 7. The Test of Significance.
- ↑ Fisher 1971, Section 12.1 Scientific Inference and Acceptance Procedures.
- ↑ Sellke, Thomas; Bayarri, M. J.; Berger, James O. (2001). "Calibration of p Values for Testing Precise Null Hypotheses". The American Statistician . 55 (1): 62–71. doi:10.1198/000313001300339950. JSTOR 2685531.
- ↑ Johnson, Valen (2013). "Revised standards for statistical evidence". Proceedings of the National Academy of Sciences USA. 110: 19313–19317. doi:10.1073/pnas.1313476110.
- ↑ Colquhoun, David (2015). "An investigation of the false discovery rate and the misinterpretation of p-values". Royal Society Open Science. 1: 140216. doi:10.1098/rsos.140216.
- 1 2 3 4 Dixon P (2003). "The p-value fallacy and how to avoid it.". Canadian Journal of Experimental Psychology. 57 (3): 189–202. doi:10.1037/h0087425. PMID 14596477.
- ↑ Hunter JE (1997). "Needed: A Ban on the Significance Test". Psychological Science. 8 (1): 3–7. doi:10.1111/j.1467-9280.1997.tb00534.x.
- ↑ Sterne JA, Smith GD (2001). "Sifting the evidence–what's wrong with significance tests?". BMJ. 322 (7280): 226–231. doi:10.1136/bmj.322.7280.226. PMC 1119478. PMID 11159626.
- ↑ Schervish MJ (1996). "P Values: What They Are and What They Are Not". The American Statistician. 50 (3): 203. doi:10.2307/2684655. JSTOR 2684655.
- ↑ Sellke T, Bayarri M, Berger JO (2001). "Calibration of p values for testing precise null hypotheses". The American Statistician. 55 (1): 62–71. doi:10.1198/000313001300339950.
- ↑ Casson, R. J. (2011). "The pesty P value". Clinical & Experimental Ophthalmology. 39 (9): 849–850. doi:10.1111/j.1442-9071.2011.02707.x.
- ↑ Johnson, D. H. (1999). "The Insignificance of Statistical Significance Testing". Journal of Wildlife Management. 63 (3): 763–772. doi:10.2307/3802789.
- ↑ Cox, Richard (1961). the Algebra of Probable Inference. Baltimore, MD: The Johns Hopkins Press. ISBN 080186982X.
- ↑ National Institutes of Health definition of E-value
- ↑ http://magazine.amstat.org/wp-content/uploads/STATTKadmin/style[1].pdf
{kind=link}
Further reading
- Pearson, Karl (1900). "On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling" (PDF). Philosophical Magazine Series 5. 50 (302): 157–175. doi:10.1080/14786440009463897.
- Elderton, William Palin (1902). "Tables for Testing the Goodness of Fit of Theory to Observation". Biometrika. 1 (2): 155–163. doi:10.1093/biomet/1.2.155.
- Fisher, Ronald (1925). Statistical Methods for Research Workers. Edinburgh: Oliver & Boyd. ISBN 0-05-002170-2.
- Fisher, Ronald A. (1971) [1935]. The Design of Experiments (9th ed.). Macmillan. ISBN 0-02-844690-9.
- Fisher, R. A.; Yates, F. (1938). Statistical tables for biological, agricultural and medical research. London.
- Stigler, Stephen M. (1986). The history of statistics : the measurement of uncertainty before 1900. Cambridge, Mass: Belknap Press of Harvard University Press. ISBN 0-674-40340-1.
- Hubbard, Raymond; Bayarri, M. J. (November 2003), P Values are not Error Probabilities (PDF), a working paper that explains the difference between Fisher's evidential p-value and the Neyman–Pearson Type I error rate α.
- Hubbard, Raymond; Armstrong, J. Scott (2006). "Why We Don't Really Know What Statistical Significance Means: Implications for Educators" (PDF). Journal of Marketing Education. 28 (2): 114–120. doi:10.1177/0273475306288399. Archived from the original on May 18, 2006.
- Hubbard, Raymond; Lindsay, R. Murray (2008). "Why P Values Are Not a Useful Measure of Evidence in Statistical Significance Testing" (PDF). Theory & Psychology. 18 (1): 69–88. doi:10.1177/0959354307086923.
- Stigler, S. (December 2008). "Fisher and the 5% level". Chance. 21 (4): 12. doi:10.1007/s00144-008-0033-3.
- Dallal, Gerard E. (2012). The Little Handbook of Statistical Practice.
- Biau, D.J.; Jolles, B.M.; Porcher, R. (March 2010). "P value and the theory of hypothesis testing: an explanation for new researchers.". Clin Orthop Relat Res. 463 (3): 885–892. doi:10.1007/s11999-009-1164-4.
- Reinhart, Alex. Statistics Done Wrong: The Woefully Complete Guide. No Starch Press. p. 176. ISBN 978-1593276201.
External links
| Wikimedia Commons has media related to P-value. |
- Free online p-values calculators for various specific tests (chi-square, Fisher's F-test, etc.).
- Understanding p-values, including a Java applet that illustrates how the numerical values of p-values can give quite misleading impressions about the truth or falsity of the hypothesis under test.
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||