Merkle tree
In cryptography and computer science, a hash tree or Merkle tree is a tree in which every non-leaf node is labelled with the hash of the labels or values (in case of leaves) of its child nodes. Hash trees allow efficient and secure verification of the contents of large data structures. Hash trees are a generalization of hash lists and hash chains.
Demonstrating that a leaf node is a part of the given hash tree requires processing an amount of data proportional to the logarithm of the number of nodes of the tree;[1] this contrasts with hash lists, where the amount is proportional to the number of nodes.
The concept of hash trees is named after Ralph Merkle who patented it in 1979.[2][3]
Uses
Hash trees can be used to verify any kind of data stored, handled and transferred in and between computers. Currently the main use of hash trees is to make sure that data blocks received from other peers in a peer-to-peer network are received undamaged and unaltered, and even to check that the other peers do not lie and send fake blocks. Suggestions have been made to use hash trees in trusted computing systems.[4]
Hash trees are used in the IPFS, Btrfs and ZFS file systems[5] (to counter data degradation[6]), BitTorrent protocol, Apache Wave protocol,[7] Git distributed revision control system, the Tahoe-LAFS backup system, the Bitcoin peer-to-peer network, the Ethereum peer-to-peer network,[8] the Certificate Transparency framework, and a number of NoSQL systems like Apache Cassandra, Riak and DynamoDB.[9]
Overview
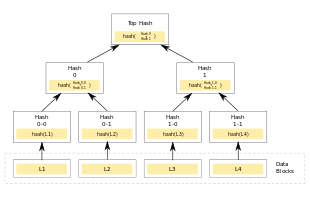
A hash tree is a tree of hashes in which the leaves are hashes of data blocks in, for instance, a file or set of files. Nodes further up in the tree are the hashes of their respective children. For example, in the picture hash 0 is the result of hashing the result of concatenating hash 0-0 and hash 0-1. That is, hash 0 = hash( hash 0-0 + hash 0-1 ) where + denotes concatenation.
Most hash tree implementations are binary (two child nodes under each node) but they can just as well use many more child nodes under each node.
Usually, a cryptographic hash function such as SHA-2 is used for the hashing . If the hash tree only needs to protect against unintentional damage, much less secure checksums such as CRCs can be used.
In the top of a hash tree there is a top hash (or root hash or master hash). Before downloading a file on a p2p network, in most cases the top hash is acquired from a trusted source, for instance a friend or a web site that is known to have good recommendations of files to download. When the top hash is available, the hash tree can be received from any non-trusted source, like any peer in the p2p network. Then, the received hash tree is checked against the trusted top hash, and if the hash tree is damaged or fake, another hash tree from another source will be tried until the program finds one that matches the top hash.
The main difference from a hash list is that one branch of the hash tree can be downloaded at a time and the integrity of each branch can be checked immediately, even though the whole tree is not available yet. For example, in the picture, the integrity of data block 2 can be verified immediately if the tree already contains hash 0-0 and hash 1 by hashing the data block and iteratively combining the result with hash 0-0 and then hash 1 and finally comparing the result with the top hash. Similarly, the integrity of data block 3 can be verified if the tree already has hash 1-1 and hash 0. This can be an advantage since it is efficient to split files up in very small data blocks so that only small blocks have to be re-downloaded if they get damaged. If the hashed file is very big, such a hash tree or hash list becomes fairly big. But if it is a tree, one small branch can be downloaded quickly, the integrity of the branch can be checked, and then the downloading of data blocks can start.
Second preimage attack
The Merkle hash root does not indicate the tree depth, enabling a second-preimage attack in which an attacker creates a document other than the original that has the same Merkle hash root. For the example above, an attacker can create a new document containing two data blocks, where the first is hash 0-0 + hash 0-1, and the second is hash 1-0 + hash 1-1.
One simple fix is defined in Certificate Transparency: when computing leaf node hashes, a 0x00 byte is prepended to the hash data, while 0x01 is prepended when computing internal node hashes. Limiting the hash tree size is a prerequisite of some formal security proofs, and helps in making some proofs tighter. Some implementations limit the tree depth using hash tree depth prefixes before hashes, so any extracted hash chain is defined to be valid only if the prefix decreases at each step and is still positive when the leaf is reached.
Tiger tree hash
The Tiger tree hash is a widely used form of hash tree. It uses a binary hash tree (two child nodes under each node), usually has a data block size of 1024 bytes and uses the cryptographically secure Tiger hash.[10]
Tiger tree hashes are used in Gnutella, Gnutella2, and Direct Connect P2P file sharing protocols and in file sharing applications such as Phex, BearShare, LimeWire, Shareaza, DC++[11] and Valknut.
Example
Base32: RBOEI7UYRYO5SUXGER5NMUOEZ5O6E4BHPP2MRFQ
URN: urn:tree:tiger:RBOEI7UYRYO5SUXGER5NMUOEZ5O6E4BHPP2MRFQ
magnet: magnet:?xt=urn:tree:tiger:RBOEI7UYRYO5SUXGER5NMUOEZ5O6E4BHPP2MRFQ
See also
References
- ↑ Georg Becker (2008-07-18). "Merkle Signature Schemes, Merkle Trees and Their Cryptanalysis" (PDF). Ruhr-Universität Bochum. p. 16. Retrieved 2013-11-20.
- ↑ Merkle, R. C. (1988). "A Digital Signature Based on a Conventional Encryption Function". Advances in Cryptology — CRYPTO '87. Lecture Notes in Computer Science. 293. p. 369. doi:10.1007/3-540-48184-2_32. ISBN 978-3-540-18796-7.
- ↑ US patent 4309569, Ralf Merkle, "Method of providing digital signatures", published Jan 5, 1982, assigned to The Board Of Trustees Of The Leland Stanford Junior University
- ↑ J. Kilian. Improved efficient arguments (preliminary version). In CRYPTO, 1995.
- ↑ Jeff Bonwick's Blog ZFS End-to-End Data Integrity
- ↑ Likai Liu. "Bitrot Resistance on a Single Drive". likai.org.
- ↑ Google Wave Federation Protocol Wave Protocol Verification Paper
- ↑ Cryptocash, cryptocurrencies, and cryptocontracts, Koblitz and Menezes, Designs, Codes and Cryptography, Volume 78, Issue 1, pp 87-102, January 2016.
- ↑ Adam Marcus. "The NoSQL Ecosystem". aosabook.org.
When a replica is down for an extended period of time, or the machine storing hinted handoffs for an unavailable replica goes down as well, replicas must synchronize from one another. In this case, Cassandra and Riak implement a Dynamo-inspired process called anti-entropy. In anti-entropy, replicas exchange Merkle trees to identify parts of their replicated key ranges which are out of sync. A Merkle tree is a hierarchical hash verification: if the hash over the entire keyspace is not the same between two replicas, they will exchange hashes of smaller and smaller portions of the replicated keyspace until the out-of-sync keys are identified. This approach reduces unnecessary data transfer between replicas which contain mostly similar data.
- ↑ Tree Hash EXchange format (THEX) (archive)
- ↑ "DC++'s feature list"
Further reading
- Merkle tree patent 4,309,569 – explains both the hash tree structure and the use of it to handle many one-time signatures
- Tree Hash EXchange format (THEX) – a detailed description of Tiger trees
- Efficient Use of Merkle Trees – an RSA labs explanation of the original purpose of Merkle trees, which is to handle many Lamport one-time signatures
External links

- A C implementation of a dynamically re-sizeable binary SHA-256 hash tree (Merkle Tree)
- Merkle Tree implementation in Java
- Tiger Tree Hash (TTH) source code in C#, by Gil Schmidt
- Tiger Tree Hash (TTH) implementations in C and Java
- RHash, an open source command-line tool, which can calculate TTH and magnet links with TTH
|