P-rep
In statistical hypothesis testing, p-rep or prep has been proposed as a statistical alternative to the classic p-value.[1] Whereas a p-value is the probability of obtaining a result under the null hypothesis, p-rep computes the probability of replicating an effect. Whether it does so is heavily disputed – some have argued that the concept rests on a mathematical falsehood.
For a while, the Association for Psychological Science recommended that articles submitted to Psychological Science and their other journals report p-rep rather than the classic p-value,[2] but this is no longer the case.[3]
Calculation
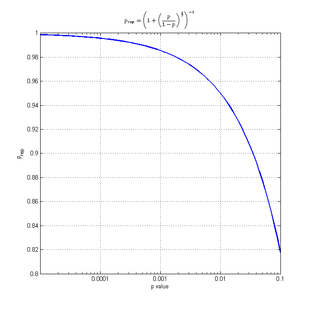
The value of the p-rep (prep) can be approximated based on the p-value (p) as follows:
![p_{{\text{rep}}}=\left[1+\left({\frac {p}{1-p}}\right)^{{{\frac {2}{3}}}}\right]^{{-1}}.](../I/m/9b74a8df1faaa18b67617a51f1e80b66000507ef.svg)
Criticism
The fact that the p-rep has a one-to-one correspondence with the p-value makes it clear that this new measure brings no additional information beyond that conveyed by the significance of the result. Killeen acknowledges this lack of information, but suggests that p-rep better-captures the way naive experimenters conceptualize p-values and statistical hypothesis testing.
Among the criticisms of p-rep is the fact that while it attempts to estimate replicability, it ignores results from other studies which can accurately guide this estimate.[4] For example, an experiment on some unlikely paranormal phenomenon may yield a p-rep of 0.75. Most people would still not conclude the probability of a replication was 75%. Rather, they would conclude it is much closer to 0: Extraordinary claims require extraordinary evidence, and p-rep ignores this. Because of this, p-rep may in fact be harder to interpret than a classical p-value. The fact that p-rep requires assumptions about prior probabilities for it to be valid makes its interpretation complex. Killeen argues that new results should be evaluated in their own right, without the "burden of history", with flat priors: that is what p-rep yields. A more pragmatic estimate of replicability would include prior knowledge, via, for instance, meta-analysis.
Critics have also underscored mathematical errors in the original Killeen paper. For example, the formula relating the effect sizes from two replications of a given experiment erroneously uses one of these random variables as a parameter of the probability distribution of the other while he previously hypothesized these two variables to be independent,[5] criticisms addressed in Killeen's rejoinder.[6]
A further criticism of the p-rep statistic involves the logic of experimentation. The scientific value of replicable data lies in the adequate accounting for previously unmeasured factors (including, for instance unmeasured participant variables, experimenter's bias, etc. The idea that a single study can capture a logical likelihood of such unmeasured factors affecting the outcome, and thus the likelihood of replicability, is a logical fallacy.
References
- ↑ Killeen PR (2005). "An alternative to null-hypothesis significance tests". Psychological science : a journal of the American Psychological Society / APS. 16 (5): 345–53. doi:10.1111/j.0956-7976.2005.01538.x. PMC 1473027
 . PMID 15869691.
. PMID 15869691. - ↑ archived version of "Psychological Science Journal, Author Guidelines"
- ↑ Psychological Science Journal, Author Guidelines.
- ↑ Macdonald, R. R. (2005) "Why Replication Probabilities Depend on Prior Probability Distributions" Psychological Science, 2005, 16, 1006–1008
- ↑ "p-rep" at Pro Bono Statistics
- ↑ Killeen, P. R. (2005)" Replicability, Confidence, and Priors", Psychological Science, 2005, 16, 1009–1012