Effect size
In statistics, an effect size is a quantitative measure of the strength of a phenomenon.[1] Examples of effect sizes are the correlation between two variables, the regression coefficient in a regression, the mean difference, or even the risk with which something happens, such as how many people survive after a heart attack for every one person that does not survive. For each type of effect size, a larger absolute value always indicates a stronger effect. Effect sizes complement statistical hypothesis testing, and play an important role in power analyses, sample size planning, and in meta-analyses. They are the first item (magnitude) in the MAGIC criteria for evaluating the strength of a statistical claim.
Especially in meta-analysis, where the purpose is to combine multiple effect sizes, the standard error (S.E.) of the effect size is of critical importance. The S.E. of the effect size is used to weight effect sizes when combining studies, so that large studies are considered more important than small studies in the analysis. The S.E. of the effect size is calculated differently for each type of effect size, but generally only requires knowing the study's sample size (N), or the number of observations in each group (n's).
Reporting effect sizes is considered good practice when presenting empirical research findings in many fields.[2][3] The reporting of effect sizes facilitates the interpretation of the substantive, as opposed to the statistical, significance of a research result.[4] Effect sizes are particularly prominent in social and medical research. Relative and absolute measures of effect size convey different information, and can be used complementarily. A prominent task force in the psychology research community made the following recommendation:
Always present effect sizes for primary outcomes...If the units of measurement are meaningful on a practical level (e.g., number of cigarettes smoked per day), then we usually prefer an unstandardized measure (regression coefficient or mean difference) to a standardized measure (r or d).— L. Wilkinson and APA Task Force on Statistical Inference (1999, p. 599)
Overview
Population and sample effect sizes
The term effect size can refer to the value of a statistic calculated from a sample of data, the value of a parameter of a hypothetical statistical population, or to the equation that operationalizes how statistics or parameters lead to the effect size value.[1] Conventions for distinguishing sample from population effect sizes follow standard statistical practices — one common approach is to use Greek letters like ρ to denote population parameters and Latin letters like r to denote the corresponding statistic; alternatively, a "hat" can be placed over the population parameter to denote the statistic, e.g. with being the estimate of the parameter .


As in any statistical setting, effect sizes are estimated with sampling error, and may be biased unless the effect size estimator that is used is appropriate for the manner in which the data were sampled and the manner in which the measurements were made. An example of this is publication bias, which occurs when scientists only report results when the estimated effect sizes are large or are statistically significant. As a result, if many researchers carry out studies with low statistical power, the reported effect sizes will tend to be larger than the true (population) effects, if any.[5] Another example where effect sizes may be distorted is in a multiple trial experiment, where the effect size calculation is based on the averaged or aggregated response across the trials.[6]
Relationship to test statistics
Sample-based effect sizes are distinguished from test statistics used in hypothesis testing, in that they estimate the strength (magnitude) of, for example, an apparent relationship, rather than assigning a significance level reflecting whether the magnitude of the relationship observed could be due to chance. The effect size does not directly determine the significance level, or vice versa. Given a sufficiently large sample size, a non-null statistical comparison will always show a statistically significant results unless the population effect size is exactly zero (and even there it will show statistical significance at the rate of the Type I error used). For example, a sample Pearson correlation coefficient of 0.01 is statistically significant if the sample size is 1000. Reporting only the significant p-value from this analysis could be misleading if a correlation of 0.01 is too small to be of interest in a particular application.
Standardized and unstandardized effect sizes
The term effect size can refer to a standardized measure of effect (such as r, Cohen's d, or the odds ratio), or to an unstandardized measure (e.g., the difference between group means or the unstandardized regression coefficients). Standardized effect size measures are typically used when:
- the metrics of variables being studied do not have intrinsic meaning (e.g., a score on a personality test on an arbitrary scale),
- results from multiple studies are being combined,
- some or all of the studies use different scales, or
- it is desired to convey the size of an effect relative to the variability in the population.
In meta-analyses, standardized effect sizes are used as a common measure that can be calculated for different studies and then combined into an overall summary.
Types
About 50 to 100 different measures of effect size are known.
Correlation family: Effect sizes based on "variance explained"
These effect sizes estimate the amount of the variance within an experiment that is "explained" or "accounted for" by the experiment's model.
Pearson r or correlation coefficient
Pearson's correlation, often denoted r and introduced by Karl Pearson, is widely used as an effect size when paired quantitative data are available; for instance if one were studying the relationship between birth weight and longevity. The correlation coefficient can also be used when the data are binary. Pearson's r can vary in magnitude from −1 to 1, with −1 indicating a perfect negative linear relation, 1 indicating a perfect positive linear relation, and 0 indicating no linear relation between two variables. Cohen gives the following guidelines for the social sciences:[7][8]
| Effect size | r |
|---|---|
| Small | 0.10 |
| Medium | 0.30 |
| Large | 0.50 |
Coefficient of determination
A related effect size is r2, the coefficient of determination (also referred to as R2 or "r-squared"), calculated as the square of the Pearson correlation r. In the case of paired data, this is a measure of the proportion of variance shared by the two variables, and varies from 0 to 1. For example, with an r of 0.21 the coefficient of determination is 0.0441, meaning that 4.4% of the variance of either variable is shared with the other variable. The r2 is always positive, so does not convey the direction of the correlation between the two variables.
Eta-squared (η2)
Eta-squared describes the ratio of variance explained in the dependent variable by a predictor while controlling for other predictors, making it analogous to the r2. Eta-squared is a biased estimator of the variance explained by the model in the population (it estimates only the effect size in the sample). This estimate shares the weakness with r2 that each additional variable will automatically increase the value of η2. In addition, it measures the variance explained of the sample, not the population, meaning that it will always overestimate the effect size, although the bias grows smaller as the sample grows larger.

Omega-squared (ω2)
A less biased estimator of the variance explained in the population is ω2[9][10][11]

This form of the formula is limited to between-subjects analysis with equal sample sizes in all cells.[11] Since it is less biased (although not unbiased), ω2 is preferable to η2; however, it can be more inconvenient to calculate for complex analyses. A generalized form of the estimator has been published for between-subjects and within-subjects analysis, repeated measure, mixed design, and randomized block design experiments.[12] In addition, methods to calculate partial Omega2 for individual factors and combined factors in designs with up to three independent variables have been published.[12]
Cohen's ƒ2
Cohen's ƒ2 is one of several effect size measures to use in the context of an F-test for ANOVA or multiple regression. Its amount of bias (overestimation of the effect size for the ANOVA) depends on the bias of its underlying measurement of variance explained (e.g., R2, η2, ω2).
The ƒ2 effect size measure for multiple regression is defined as:

- where R2 is the squared multiple correlation.
Likewise, ƒ2 can be defined as:
- or


- for models described by those effect size measures.[13]
The effect size measure for sequential multiple regression and also common for PLS modeling[14] is defined as:


- where R2A is the variance accounted for by a set of one or more independent variables A, and R2AB is the combined variance accounted for by A and another set of one or more independent variables of interest B. By convention, ƒ2B effect sizes of 0.02, 0.15, and 0.35 are termed small, medium, and large, respectively.[7]
Cohen's can also be found for factorial analysis of variance (ANOVA) working backwards using :


In a balanced design (equivalent sample sizes across groups) of ANOVA, the corresponding population parameter of is

wherein μj denotes the population mean within the jth group of the total K groups, and σ the equivalent population standard deviations within each groups. SS is the sum of squares in ANOVA.
Cohen's q
Another measure that is used with correlation differences is Cohen's q. This is the difference between two Fisher transformed Pearson regression coefficients. In symbols this is

where r1 and r2 are the regressions being compared. The expected value of q is zero and its variance is

where N1 and N2 are the number of data points in the first and second regression respectively.
Difference family: Effect sizes based on differences between means
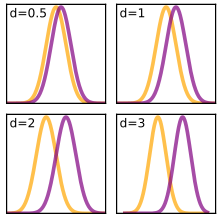
A (population) effect size θ based on means usually considers the standardized mean difference between two populations[15]:78

where μ1 is the mean for one population, μ2 is the mean for the other population, and σ is a standard deviation based on either or both populations.
In the practical setting the population values are typically not known and must be estimated from sample statistics. The several versions of effect sizes based on means differ with respect to which statistics are used.
This form for the effect size resembles the computation for a t-test statistic, with the critical difference that the t-test statistic includes a factor of . This means that for a given effect size, the significance level increases with the sample size. Unlike the t-test statistic, the effect size aims to estimate a population parameter and is not affected by the sample size.

Cohen's d
Cohen's d is defined as the difference between two means divided by a standard deviation for the data, i.e.

Jacob Cohen defined s, the pooled standard deviation, as (for two independent samples):[7]:67

where the variance for one of the groups is defined as

and similar for the other group.
The table below contains descriptors for magnitudes of d = 0.01 to 2.0, as initially suggested by Cohen and expanded by Sawilowsky.[16]
| Effect Size | d | Reference |
|---|---|---|
| Very Small | 0.01 | Sawilowsky, 2009 |
| Small | 0.20 | Cohen, 1988 |
| Medium | 0.50 | Cohen, 1988 |
| Large | 0.80 | Cohen, 1988 |
| Very Large | 1.20 | Sawilowsky, 2009 |
| Huge | 2.0 | Sawilowsky, 2009 |
Other authors choose a slightly different computation of the standard deviation when referring to "Cohen's d" where the denominator is without "-2"[17][18]:14

This definition of "Cohen's d" is termed the maximum likelihood estimator by Hedges and Olkin,[15] and it is related to Hedges' g by a scaling factor (see below).
So, in the example above of visiting England and observing men's and women's heights, the data (Aaron,Kromrey,& Ferron, 1998, November; from a 2004 UK representative sample of 2436 men and 3311 women) are:
- Men: mean height = 1750 mm; standard deviation = 89.93 mm
- Women: mean height = 1612 mm; standard deviation = 69.05 mm
The effect size (using Cohen's d) would equal 1.72 (95% confidence intervals: 1.66 – 1.78). This is very large and you should have no problem in detecting that there is a consistent height difference, on average, between men and women.
With two paired samples, we look at the distribution of the difference scores. In that case, s is the standard deviation of this distribution of difference scores. This creates the following relationship between the t-statistic to test for a difference in the means of the two groups and Cohen's d:

and

Cohen's d is frequently used in estimating sample sizes for statistical testing. A lower Cohen's d indicates the necessity of larger sample sizes, and vice versa, as can subsequently be determined together with the additional parameters of desired significance level and statistical power.[19]
Glass' Δ
In 1976 Gene V. Glass proposed an estimator of the effect size that uses only the standard deviation of the second group[15]:78

The second group may be regarded as a control group, and Glass argued that if several treatments were compared to the control group it would be better to use just the standard deviation computed from the control group, so that effect sizes would not differ under equal means and different variances.
Under a correct assumption of equal population variances a pooled estimate for σ is more precise.
Hedges' g
Hedges' g, suggested by Larry Hedges in 1981,[20] is like the other measures based on a standardized difference[15]:79

where the pooled standard deviation is computed as:


However, as an estimator for the population effect size θ it is biased. Nevertheless, this bias can be approximately corrected through multiplication by a factor

Hedges and Olkin refer to this less-biased estimator as d,[15] but it is not the same as Cohen's d. The exact form for the correction factor J() involves the gamma function[15]:104


Ψ, Root-Mean-Square Standardized Effect
A similar effect size estimator for multiple comparisons (e.g., ANOVA) is the Ψ root-mean-square standardized effect.[13] This essentially presents the omnibus difference of the entire model adjusted by the root mean square, analogous to d or g. The simplest formula for Ψ, suitable for one-way ANOVA, is

In addition, a generalization for multi-factorial designs has been provided.[13]
Distribution of effect sizes based on means
Provided that the data is Gaussian distributed a scaled Hedges' g, , follows a noncentral t-distribution with the noncentrality parameter and (n1 + n2 − 2) degrees of freedom. Likewise, the scaled Glass' Δ is distributed with n2 − 1 degrees of freedom.


From the distribution it is possible to compute the expectation and variance of the effect sizes.
In some cases large sample approximations for the variance are used. One suggestion for the variance of Hedges' unbiased estimator is[15]:86

Categorical family: Effect sizes for associations among categorical variables
|
|
|
| Phi (φ) | Cramér's V (φc) |
|---|


Commonly used measures of association for the chi-squared test are the Phi coefficient and Cramér's V (sometimes referred to as Cramér's phi and denoted as φc). Phi is related to the point-biserial correlation coefficient and Cohen's d and estimates the extent of the relationship between two variables (2 x 2).[21] Cramér's V may be used with variables having more than two levels.
Phi can be computed by finding the square root of the chi-squared statistic divided by the sample size.
Similarly, Cramér's V is computed by taking the square root of the chi-squared statistic divided by the sample size and the length of the minimum dimension (k is the smaller of the number of rows r or columns c).
φc is the intercorrelation of the two discrete variables[22] and may be computed for any value of r or c. However, as chi-squared values tend to increase with the number of cells, the greater the difference between r and c, the more likely V will tend to 1 without strong evidence of a meaningful correlation.
Cramér's V may also be applied to 'goodness of fit' chi-squared models (i.e. those where c=1). In this case it functions as a measure of tendency towards a single outcome (i.e. out of k outcomes). In such a case one must use r for k, in order to preserve the 0 to 1 range of V. Otherwise, using c would reduce the equation to that for Phi.
Cohen's w
Another measure of effect size used for chi square tests is Cohen's w. This is defined as

where p0i is the value of the ith cell under H0 and p1i is the value of the ith cell under H1.
Odds ratio
The odds ratio (OR) is another useful effect size. It is appropriate when the research question focuses on the degree of association between two binary variables. For example, consider a study of spelling ability. In a control group, two students pass the class for every one who fails, so the odds of passing are two to one (or 2/1 = 2). In the treatment group, six students pass for every one who fails, so the odds of passing are six to one (or 6/1 = 6). The effect size can be computed by noting that the odds of passing in the treatment group are three times higher than in the control group (because 6 divided by 2 is 3). Therefore, the odds ratio is 3. Odds ratio statistics are on a different scale than Cohen's d, so this '3' is not comparable to a Cohen's d of 3.
Relative risk
The relative risk (RR), also called risk ratio, is simply the risk (probability) of an event relative to some independent variable. This measure of effect size differs from the odds ratio in that it compares probabilities instead of odds, but asymptotically approaches the latter for small probabilities. Using the example above, the probabilities for those in the control group and treatment group passing is 2/3 (or 0.67) and 6/7 (or 0.86), respectively. The effect size can be computed the same as above, but using the probabilities instead. Therefore, the relative risk is 1.28. Since rather large probabilities of passing were used, there is a large difference between relative risk and odds ratio. Had failure (a smaller probability) been used as the event (rather than passing), the difference between the two measures of effect size would not be so great.
While both measures are useful, they have different statistical uses. In medical research, the odds ratio is commonly used for case-control studies, as odds, but not probabilities, are usually estimated.[23] Relative risk is commonly used in randomized controlled trials and cohort studies, but relative risk contributes to overestimations of the effectiveness of interventions.[24]
Risk Difference
The risk difference (RD), sometimes called absolute risk reduction, is simply the difference in risk (probability) of an event between two groups. It is a useful measure in experimental research, since RD tells you the extent to which an experimental interventions changes the probability of an event or outcome. Using the example above, the probabilities for those in the control group and treatment group passing is 2/3 (or 0.67) and 6/7 (or 0.86), respectively, and so the RD effect size is 0.86 - 0.67 = 0.19 (or 19%). RD is the superior measure for assessing effectiveness of interventions.[24]
Cohen's h
One measure used in power analysis when comparing two independent proportions is Cohen's h. This is defined as follows

where p1 and p2 are the proportions of the two samples being compared and arcsin is the arcsine transformation.
Common language effect size
To more easily describe the meaning of an effect size, to people outside statistics, the common language effect size, as the name implies, was designed to communicate it in plain English. It is used to describe a difference between two groups and was proposed, as well as named, by Kenneth McGraw and S. P. Wong in 1992.[25] They used the following example (about heights of men and women): "in any random pairing of young adult males and females, the probability of the male being taller than the female is .92, or in simpler terms yet, in 92 out of 100 blind dates among young adults, the male will be taller than the female",[26] when describing the population value of the common language effect size.
The population value, for the common language effect size, is often reported like this, in terms of pairs randomly chosen from the population. Kerby (2014) notes that a pair, defined as a score in one group paired with a score in another group, is a core concept of the common language effect size.[27]
As an other example, consider a scientific study (maybe of a treatment for some chronic disease, such as arthritis) with ten people in the treatment group and ten people in a control group. If everyone in the treatment group is compared to everyone in the control group, then there are (10×10=) 100 pairs. At the end of the study, the outcome is rated into a score, for each individual (for example on a scale of mobility and pain, in the case of an arthritis study), and then all the scores are compared between the pairs. The results, as the percent of pairs that support the hypothesis, is the common language effect size. In the example study it could be (lets say) .80, if 80 out of the 100 comparison pairs shows a better outcome for the treatment group, than the control group, and the report may read as follows: "When a patient in the treatment group was compared to a patient in the control group, in 80 of 100 pairs the treated patient showed a better treatment outcome." The sample value, in for example a study like this, is an unbiased estimator of the population value.[28]
Vargha and Delaney generalized the common language effect size (Vargha-Delaney A), to cover ordinal level data.[29] The R package orddom calculates A as well as bootstrap confidence intervals.
Rank-biserial correlation
An effect size related to the common language effect size is the rank-biserial correlation. This measure was introduced by Cureton as an effect size for the Mann-Whitney U test.[30] That is, there are two groups, and scores for the groups have been converted to ranks. The Kerby simple difference formula [27] computes the rank-biserial correlation from the common language effect size. Letting f be the proportion of pairs favorable to the hypothesis (the common language effect size), and letting u be the proportion of pairs not favorable, the rank-biserial r is the simple difference between the two proportions: r = f - u. In other words, the correlation is the difference between the common language effect size and its complement. For example, if the common language effect size is 60%, then the rank-biserial r equals 60% minus 40%, or r = .20. The Kerby formula is directional, with positive values indicating that the results support the hypothesis.
A non-directional formula for the rank-biserial correlation was provided by Wendt, such that the correlation is always positive.[31] The advantage of the Wendt formula is that it can be computed with information that is readily available in published papers. The formula uses only the test value of U from the Mann-Whitney U test, and the sample sizes of the two groups: r = 1 – (2U)/ (n1 * n2). Note that U is defined here according to the classic definition as the smaller of the two U values which can be computed from the data. This ensures that 2*U < n1*n2, as n1*n2 is the maximum value of the U statistics.
An example can illustrate the use of the two formulas. Consider a health study of twenty older adults, with ten in the treatment group and ten in the control group; hence, there are ten times ten or 100 pairs. The health program uses diet, exercise, and supplements to improve memory, and memory is measured by a standardized test. A Mann-Whitney U test shows that the adult in the treatment group had the better memory in 70 of the 100 pairs, and the poorer memory in 30 pairs. The Mann-Whitney U is the smaller of 70 and 30, so U = 30. The correlation between memory and treatment performance by the Kerby simple difference formula is r = (70/100) - (30/100) = 0.40. The correlation by the Wendt formula is r = 1 - (2*30) / (10*10) = 0.40.
Effect size for ordinal data
Cliff's delta or was originally developed by Norman Cliff for use with ordinal data.[32] In short, is a measure of how often one the values in one distribution are larger than the values in a second distribution. Crucially, it does not require any assumptions about the shape or spread of the two distributions.

The sample estimate is given by:

where the two distributions are of size and with items and , respectively, and is defined as the number of times.





is linearly related to the Mann-Whitney U statistic, however it captures the direction of the difference in its sign. Given the Mann-Whitney , is:


The R package orddom calculates as well as bootstrap confidence intervals.
Confidence intervals by means of noncentrality parameters
Confidence intervals of standardized effect sizes, especially Cohen's and , rely on the calculation of confidence intervals of noncentrality parameters (ncp). A common approach to construct the confidence interval of ncp is to find the critical ncp values to fit the observed statistic to tail quantiles α/2 and (1 − α/2). The SAS and R-package MBESS provides functions to find critical values of ncp.


t-test for mean difference of single group or two related groups
For a single group, M denotes the sample mean, μ the population mean, SD the sample's standard deviation, σ the population's standard deviation, and n is the sample size of the group. The t value is used to test the hypothesis on the difference between the mean and a baseline μbaseline. Usually, μbaseline is zero. In the case of two related groups, the single group is constructed by the differences in pair of samples, while SD and σ denote the sample's and population's standard deviations of differences rather than within original two groups.


and Cohen's

is the point estimate of

So,

t-test for mean difference between two independent groups
n1 or n2 are the respective sample sizes.

wherein


and Cohen's
- is the point estimate of


So,

One-way ANOVA test for mean difference across multiple independent groups
One-way ANOVA test applies noncentral F distribution. While with a given population standard deviation , the same test question applies noncentral chi-squared distribution.


For each j-th sample within i-th group Xi,j, denote

While,

So, both ncp(s) of F and equate


In case of for K independent groups of same size, the total sample size is N := n·K.


The t-test for a pair of independent groups is a special case of one-way ANOVA. Note that the noncentrality parameter of F is not comparable to the noncentrality parameter of the corresponding t. Actually, , and .




Effect Sizes Descriptors
Whether an effect size should be interpreted small, medium, or large depends on its substantive context and its operational definition. Cohen's conventional criteria small, medium, or big[7] are near ubiquitous across many fields, although Cohen[7] cautioned:
"The terms 'small,' 'medium,' and 'large' are relative, not only to each other, but to the area of behavioral science or even more particularly to the specific content and research method being employed in any given investigation....In the face of this relativity, there is a certain risk inherent in offering conventional operational definitions for these terms for use in power analysis in as diverse a field of inquiry as behavioral science. This risk is nevertheless accepted in the belief that more is to be gained than lost by supplying a common conventional frame of reference which is recommended for use only when no better basis for estimating the ES index is available." (p. 25)
In the two sample layout, Sawilowsky [16] concluded "Based on current research findings in the applied literature, it seems appropriate to revise the rules of thumb for effect sizes," keeping in mind Cohen's cautions, and expanded the descriptions to include very small, very large, and huge. The same de facto standards could be developed for other layouts.
Lenth [33] noted for a "medium" effect size, "you'll choose the same n regardless of the accuracy or reliability of your instrument, or the narrowness or diversity of your subjects. Clearly, important considerations are being ignored here. Researchers should interpret the substantive significance of their results by grounding them in a meaningful context or by quantifying their contribution to knowledge, and Cohen's effect size descriptions can be helpful as a starting point."[4] Similarly, a U.S. Dept of Education sponsored report said "The widespread indiscriminate use of Cohen’s generic small, medium, and large effect size values to characterize effect sizes in domains to which his normative values do not apply is thus likewise inappropriate and misleading."[34]
They suggested that "appropriate norms are those based on distributions of effect sizes for comparable outcome measures from comparable interventions targeted on comparable samples." Thus if a study in a field where most interventions are tiny yielded a small effect (by Cohen's criteria), these new criteria would call it "large". In a related point, see Abelson's paradox and Sawilowsky's paradox.
See also
- Estimation statistics
- Statistical significance
- Z-factor, an alternative measure of effect size
References
- 1 2 Kelley, Ken; Preacher, Kristopher J. (2012). "On Effect Size". Psychological Methods. 17 (2): 137–152. doi:10.1037/a0028086.
- ↑ Wilkinson, Leland (1999). "Statistical methods in psychology journals: Guidelines and explanations". American Psychologist. 54 (8): 594–604. doi:10.1037/0003-066X.54.8.594.
- ↑ Nakagawa, Shinichi; Cuthill, Innes C (2007). "Effect size, confidence interval and statistical significance: a practical guide for biologists". Biological Reviews Cambridge Philosophical Society. 82 (4): 591–605. doi:10.1111/j.1469-185X.2007.00027.x. PMID 17944619.
- 1 2 Ellis, Paul D. (2010). The Essential Guide to Effect Sizes: Statistical Power, Meta-Analysis, and the Interpretation of Research Results. Cambridge University Press. ISBN 978-0-521-14246-5.
- ↑ Brand A, Bradley MT, Best LA, Stoica G (2008). "Accuracy of effect size estimates from published psychological research" (PDF). Perceptual and Motor Skills. 106 (2): 645–649. doi:10.2466/PMS.106.2.645-649. PMID 18556917.
- ↑ Brand A, Bradley MT, Best LA, Stoica G (2011). "Multiple trials may yield exaggerated effect size estimates" (PDF). The Journal of General Psychology. 138 (1): 1–11. doi:10.1080/00221309.2010.520360.
- 1 2 3 4 5 Cohen, Jacob (1988). Statistical Power Analysis for the Behavioral Sciences. Routledge. ISBN 1-134-74270-3.
- ↑ Cohen, J (1992). "A power primer". Psychological Bulletin. 112 (1): 155–159. doi:10.1037/0033-2909.112.1.155. PMID 19565683.
- ↑ Bortz, 1999, p. 269f.;
- ↑ Bühner & Ziegler (2009, p. 413f)
- 1 2 Tabachnick & Fidell (2007, p. 55)
- 1 2 Olejnik, S. & Algina, J. 2003. Generalized Eta and Omega Squared Statistics: Measures of Effect Size for Some Common Research Designs Psychological Methods. 8:(4)434-447. http://cps.nova.edu/marker/olejnik2003.pdf
- 1 2 3 Steiger, J. H. 2004. Beyond the F test: Effect size confidence intervals and tests of close fit in the analysis of variance and contrast analysis. Psychological Methods 9:(2) 164-182. http://www.statpower.net/Steiger%20Biblio/Steiger04.pdf
- ↑ Hair/Hult/Ringle/Sarstedt, A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM), Sage, 2014, pp. 177-178.
- 1 2 3 4 5 6 7 Larry V. Hedges & Ingram Olkin (1985). Statistical Methods for Meta-Analysis. Orlando: Academic Press. ISBN 0-12-336380-2.
- 1 2 Sawilowsky, S (2009). "New effect size rules of thumb.". Journal of Modern Applied Statistical Methods. 8 (2): 467–474.
- ↑ Robert E. McGrath; Gregory J. Meyer (2006). "When Effect Sizes Disagree: The Case of r and d" (PDF). Psychological Methods. 11 (4): 386–401. doi:10.1037/1082-989x.11.4.386.
- ↑ Hartung, Joachim; Knapp, Guido; Sinha, Bimal K. (2008). Statistical Meta-Analysis with Applications. John Wiley & Sons. ISBN 978-1-118-21096-3.
- ↑ Kenny, David A. (1987). "Chapter 13" (PDF). Statistics for the Social and Behavioral Sciences. Little, Brown. ISBN 978-0-316-48915-7.
- ↑ Larry V. Hedges (1981). "Distribution theory for Glass' estimator of effect size and related estimators". Journal of Educational Statistics. 6 (2): 107–128. doi:10.3102/10769986006002107.
- ↑ Aaron, B., Kromrey, J. D., & Ferron, J. M. (1998, November). Equating r-based and d-based effect-size indices: Problems with a commonly recommended formula. Paper presented at the annual meeting of the Florida Educational Research Association, Orlando, FL. (ERIC Document Reproduction Service No. ED433353)
- ↑ Sheskin, David J. (2003). Handbook of Parametric and Nonparametric Statistical Procedures (Third ed.). CRC Press. ISBN 978-1-4200-3626-8.
- ↑ Deeks J (1998). "When can odds ratios mislead? : Odds ratios should be used only in case-control studies and logistic regression analyses". BMJ. 317 (7166): 1155–6. doi:10.1136/bmj.317.7166.1155a. PMC 1114127
 . PMID 9784470.
. PMID 9784470. - 1 2 Stegenga, J. (2015). "Measuring Effectiveness". Studies in History and Philosophy of Biological and Biomedical Sciences. 54: 62–71. doi:10.1016/j.shpsc.2015.06.003.
- ↑ McGraw KO, Wong SP (1992). "A common language effect size statistic". Psychological Bulletin. 111 (2): 361–365. doi:10.1037/0033-2909.111.2.361.
- ↑ McGraw KO, Wong SP (1992). "A common language effect size statistic". Psychological Bulletin. 111 (2): 381. doi:10.1037/0033-2909.111.2.361.
- 1 2 Kerby, D. S. (2014). The simple difference formula: An approach to teaching nonparametric correlation. Comprehensive Psychology, volume 3, article 1. doi:10.2466/11.IT.3.1. link to pdf
- ↑ Grissom RJ (1994). "Statistical analysis of ordinal categorical status after therapies". Journal of Consulting and Clinical Psychology. 62 (2): 281–284. doi:10.1037/0022-006X.62.2.281.
- ↑ Vargha, András; Delaney, Harold D. (2000). "A Critique and Improvement of the CL Common Language Effect Size Statistics of McGraw and Wong" (PDF). Journal of Educational and Behavioral Statistics. 25 (2): 101–132. doi:10.3102/10769986025002101.
- ↑ Cureton, E.E. (1956). "Rank-biserial correlation". Psychometrika. 21 (3): 287–290. doi:10.1007/BF02289138.
- ↑ Wendt, H. W. (1972). "Dealing with a common problem in social science: A simplified rank-biserial coefficient of correlation based on the U statistic". European Journal of Social Psychology. 2 (4): 463–465. doi:10.1002/ejsp.2420020412.
- ↑ Cliff, Norman (1993). "Dominance statistics: Ordinal analyses to answer ordinal questions". Psychological Bulletin. 114 (3): 494. doi:10.1037/0033-2909.114.3.494.
- ↑ Russell V. Lenth. "Java applets for power and sample size". Division of Mathematical Sciences, the College of Liberal Arts or The University of Iowa. Retrieved 2008-10-08.
- ↑ Lipsey, M.W.; et al. (2012). Translating the Statistical Representation of the Effects of Education Interventions Into More Readily Interpretable Forms (PDF). United States: U.S. Dept of Education, National Center for Special Education Research, Institute of Education Sciences,NCSER 2013-3000.
Further reading
- Aaron, B., Kromrey, J. D., & Ferron, J. M. (1998, November). Equating r-based and d-based effect-size indices: Problems with a commonly recommended formula. Paper presented at the annual meeting of the Florida Educational Research Association, Orlando, FL. (ERIC Document Reproduction Service No. ED433353)
- Bonett, D. G. (2008). "Confidence intervals for standardized linear contrasts of means". Psychological Methods. 13: 99–109. doi:10.1037/1082-989x.13.2.99.
- Bonett, D. G. (2009). "Estimating standardized linear contrasts of means with desired precision". Psychological Methods. 14: 1–5. doi:10.1037/a0014270.
- Brooks, M.E.; Dalal, D.K.; Nolan, K.P. (2013). "Are common language effect sizes easier to understand than traditional effect sizes?". Journal of Applied Psychology. doi:10.1037/a0034745.
- Cumming, G.; Finch, S. (2001). "A primer on the understanding, use, and calculation of confidence intervals that are based on central and noncentral distributions". Educational and Psychological Measurement. 61: 530–572.
- Imdadullah, M. (2014). Effect Size for dependent Sample t test. itfeature.com document on Effect Size for dependent Sample t test
- Kelley, K (2007). "Confidence intervals for standardized effect sizes: Theory, application, and implementation". Journal of Statistical Software. 20 (8): 1–24.
- Lipsey, M. W., & Wilson, D. B. (2001). Practical meta-analysis. Sage: Thousand Oaks, CA.
- Sawilowsky, Shlomo S. (2003). A Different Future For Social And Behavioral Science Research, Journal of Modern Applied Statistical Methods, Vol 2(1), 128-132.
External links
| Wikiversity has learning materials about Effect size |
Online applications
- Copylefted Effect Size Confidence Interval R Code with RWeb service for t-test, ANOVA, regression, and RMSEA
- Online calculator for computing different effect sizes like Cohen's d, r, q, f, d from dependent t tests and transformation of different measures of effect size
Software
- compute.es: Compute Effect Sizes (R package)
- MBESS – One of R's packages providing confidence intervals of effect sizes based non-central parameters
- MIX 2.0 Software for professional meta-analysis in Excel. Many effect sizes available.
- Effect Size Calculators Calculate d and r from a variety of statistics.
- Free Effect Size Generator – PC & Mac Software
- G*Power 3 – Power analyses and effect size calculation, free software PC & Mac Software
- ES-Calc: a free add-on for Effect Size Calculation in ViSta 'The Visual Statistics System'. Computes Cohen's d, Glass' Delta, Hedges' g, CLES, Non-Parametric Cliff's Delta, d-to-r Conversion, etc.
- The orddom package (R package). Computes Cliff's delta with a visual description of the results.
Further explanations
- Effect Size (ES)
- EffectSizeFAQ.com
- Measuring Effect Size
- Computing and Interpreting Effect size Measures with ViSta
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||