Comparative method (linguistics)
In linguistics, the comparative method is a technique for studying the development of languages by performing a feature-by-feature comparison of two or more languages with common descent from a shared ancestor, as opposed to the method of internal reconstruction, which analyses the internal development of a single language over time.[1] Ordinarily both methods are used together to reconstruct prehistoric phases of languages, to fill in gaps in the historical record of a language, to discover the development of phonological, morphological, and other linguistic systems, and to confirm or refute hypothesized relationships between languages.
The comparative method was developed over the 19th century. Key contributions were made by the Danish scholars Rasmus Rask and Karl Verner and the German scholar Jacob Grimm. The first linguist to offer reconstructed forms from a proto-language was August Schleicher, in his Compendium der vergleichenden Grammatik der indogermanischen Sprachen, originally published in 1861.[2] Here is Schleicher’s explanation of why he offered reconstructed forms:[3]
In the present work an attempt is made to set forth the inferred Indo-European original language side by side with its really existent derived languages. Besides the advantages offered by such a plan, in setting immediately before the eyes of the student the final results of the investigation in a more concrete form, and thereby rendering easier his insight into the nature of particular Indo-European languages, there is, I think, another of no less importance gained by it, namely that it shows the baselessness of the assumption that the non-Indian Indo-European languages were derived from Old-Indian (Sanskrit).
Demonstrating genetic relationship
The comparative method aims to prove that two or more historically attested languages are descended from a single proto-language by comparing lists of cognate terms. From them, regular sound correspondences between the languages are established, and a sequence of regular sound changes can then be postulated, which allows the proto-language to be reconstructed. Relation is deemed certain only if at least a partial reconstruction of the common ancestor is feasible, and if regular sound correspondences can be established with chance similarities ruled out.
Terminology
Descent is defined as transmission across the generations: children learn a language from the parents' generation and after being influenced by their peers transmit it to the next generation, and so on. For example, a continuous chain of speakers across the centuries links Vulgar Latin to all of its modern descendants.
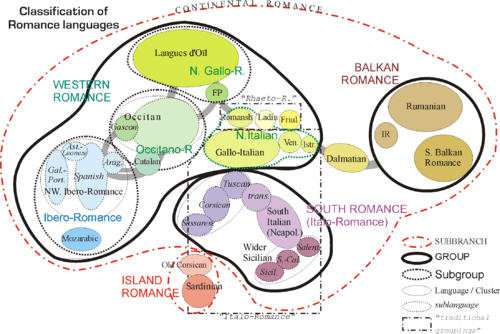
Two languages are genetically related if they descended from the same ancestor language.[4] For example, Italian and French both come from Latin and therefore belong to the same family, the Romance languages.[5]
However, it is possible for languages to have different degrees of relatedness. English, for example, is related to both German and Russian, but is more closely related to the former than it is to the latter. Although all three languages share a common ancestor, Proto-Indo-European, English and German also share a more recent common ancestor, Proto-Germanic, while Russian does not. Therefore, English and German are considered to belong to a different subgroup, the Germanic languages.[6]
Shared retentions from the parent language are not sufficient evidence of a sub-group. For example, as a result of heavy borrowing from Arabic into Persian, Modern Persian in fact takes more of its vocabulary from Arabic than from its direct ancestor, Proto-Indo-Iranian.[7] The division of related languages into sub-groups is more certainly accomplished by finding shared linguistic innovations from the parent language.
Origin and development of the method

Languages have been compared since antiquity. For example, in the 1st century BC the Romans were aware of the similarities between Greek and Latin, which they explained mythologically, as the result of Rome being a Greek colony speaking a debased dialect. In the 9th or 10th century, Yehuda Ibn Quraysh compared the phonology and morphology of Hebrew, Aramaic, and Arabic, but attributed this resemblance to the Biblical story of Babel, with Abraham, Isaac and Joseph retaining Adam's language, with other languages at various removes becoming more altered from the original Hebrew.[8]
In publications of 1647 and 1654, Marcus van Boxhorn first described a rigid methodology for historical linguistic comparisons[9] and proposed the existence of an Indo-European proto-language (which he called "Scythian") unrelated to Hebrew, but ancestral to Germanic, Greek, Romance, Persian, Sanskrit, Slavic, Celtic and Baltic languages. The Scythian theory was further developed by Andreas Jäger (1686) and William Wotton (1713), who made first forays to reconstruct this primitive common language. In 1710 and 1723, Lambert ten Kate first formulated the regularity of sound laws, introducing among others, the term root vowel.[9]
Another early systematic attempt to prove the relationship between two languages on the basis of similarity of grammar and lexicon was made by the Hungarian János Sajnovics in 1770, when he attempted to demonstrate the relationship between Sami and Hungarian (work that was later extended to the whole Finno-Ugric language family in 1799 by his countryman Samuel Gyarmathi),[10] But the origin of modern historical linguistics is often traced back to Sir William Jones, an English philologist living in India, who in 1786 made his famous observation:[11]
“The Sanscrit language, whatever be its antiquity, is of a wonderful structure; more perfect than the Greek, more copious than the Latin, and more exquisitely refined than either, yet bearing to both of them a stronger affinity, both in the roots of verbs and the forms of grammar, than could possibly have been produced by accident; so strong indeed, that no philologer could examine them all three, without believing them to have sprung from some common source, which, perhaps, no longer exists. There is a similar reason, though not quite so forcible, for supposing that both the Gothick and the Celtick, though blended with a very different idiom, had the same origin with the Sanscrit; and the old Persian might be added to the same family.”
The comparative method developed out of attempts to reconstruct the proto-language mentioned by Jones, which he did not name, but subsequent linguists named Proto-Indo-European (PIE). The first professional comparison between the Indo-European languages known then was made by the German linguist Franz Bopp in 1816. Though he did not attempt a reconstruction, he demonstrated that Greek, Latin and Sanskrit shared a common structure and a common lexicon.[12] Friedrich Schlegel in 1808 first stated the importance of using the eldest possible form of a language when trying to prove its relationships;[13] in 1818, Rasmus Christian Rask developed the principle of regular sound changes to explain his observations of similarities between individual words in the Germanic languages and their cognates in Greek and Latin.[14] Jacob Grimm - better known for his Fairy Tales - in Deutsche Grammatik (published 1819-37 in four volumes) made use of the comparative method in attempting to show the development of the Germanic languages from a common origin, the first systematic study of diachronic language change.[15]
Both Rask and Grimm were unable to explain apparent exceptions to the sound laws that they had discovered. Although Hermann Grassmann explained one of these anomalies with the publication of Grassmann's law in 1862,[16] it was Karl Verner who in 1875 made a methodological breakthrough when he identified a pattern now known as Verner's law, the first sound law based on comparative evidence showing that a phonological change in one phoneme could depend on other factors within the same word, such as the neighbouring phonemes and the position of the accent,[17] now called conditioning environments.
Similar discoveries made by the Junggrammatiker (usually translated as Neogrammarians) at the University of Leipzig in the late 1800s led them to conclude that all sound changes were ultimately regular, resulting in the famous statement by Karl Brugmann and Hermann Osthoff in 1878 that "sound laws have no exceptions".[18] This idea is fundamental to the modern comparative method, since the method necessarily assumes regular correspondences between sounds in related languages, and consequently regular sound changes from the proto-language. This Neogrammarian Hypothesis led to application of the comparative method to reconstruct Proto-Indo-European, with Indo-European being at that time by far the most well-studied language family. Linguists working with other families soon followed suit, and the comparative method quickly became the established method for uncovering linguistic relationships.[10]
Application
There is no fixed set of steps to be followed in the application of the comparative method, but some steps are suggested by Lyle Campbell[19] and Terry Crowley,[20] both authors of introductory texts in historical linguistics. The abbreviated summary below is based on their concepts of how to proceed.
Step 1, assemble potential cognate lists
This step involves making lists of words that are likely cognates among the languages being compared. If there is a regularly recurring match between the phonetic structure of basic words with similar meanings a genetic kinship can probably be established.[21] For example, looking at the Polynesian family linguists might come up with a list similar to the following (a list actually used by them would be much longer):[22]
| Gloss | one | two | three | four | five | man | sea | taboo | octopus | canoe | enter |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Tongan | taha | ua | tolu | fā | nima | taŋata | tahi | tapu | feke | vaka | hū |
| Samoan | tasi | lua | tolu | fā | lima | taŋata | tai | tapu | feʔe | vaʔa | ulu |
| Māori | tahi | rua | toru | ɸā | rima | taŋata | tai | tapu | ɸeke | waka | uru |
| Rapanui | -tahi | -rua | -toru | -ha | -rima | taŋata | tai | tapu | heke | vaka | uru |
| Rarotongan | taʔi | rua | toru | ʔā | rima | taŋata | tai | tapu | ʔeke | vaka | uru |
| Hawaiian | kahi | lua | kolu | hā | lima | kanaka | kai | kapu | heʔe | waʔa | ulu |
Borrowings or false cognates could skew or obscure the correct data.[23] For example, English taboo ([tæbu]) is like the six Polynesian forms due to borrowing from Tongan into English, and not because of a genetic similarity.[24] This problem can usually be overcome by using basic vocabulary such as kinship terms, numbers, body parts, pronouns, and other basic terms.[25] Nonetheless, even basic vocabulary can be sometimes borrowed. Finnish, for example, borrowed the word for "mother", äiti, from Gothic aiþei.;[26] English borrowed the pronouns "they", "them", and "their(s)" from Norse;[27] and Thai (along with various other East Asian languages) borrowed its numbers from Chinese. An extreme case is represented by Pirahã, a Muran language of South America, which is controversially[28] claimed to have borrowed all its pronouns from Nheengatu.[29][30]
Step 2, establish correspondence sets
The next step is to determine the regular sound correspondences exhibited by the potential cognates lists. Mere phonetic similarity, as between English day and Latin dies (both with the same meaning), has no probative value.[31] English initial d- does not regularly match Latin d-,[32] and whatever sporadic matches can be observed are due either to chance (as in the above example) or to borrowing (for example, Latin diabolus and English devil, both ultimately of Greek origin[33]). English and Latin do exhibit a regular correspondence of t- : d-[32] (where the notation "A : B" means "A corresponds to B"); for example,[34]
| English | ten | two | tow | tongue | tooth |
| Latin | decem | duo | dūco | dingua | dent- |
If there are many regular correspondence sets of this kind (the more the better), then a common origin becomes a virtual certainty, particularly if some of the correspondences are non-trivial or unusual.[21]
Step 3, discover which sets are in complementary distribution
During the late 18th to late 19th century, two major developments improved the method's effectiveness.
First, it was found that many sound changes are conditioned by a specific context. For example, in both Greek and Sanskrit, an aspirated stop evolved into an unaspirated one, but only if a second aspirate occurred later in the same word;[35] this is Grassmann's law, first described for Sanskrit by Sanskrit grammarian Pāṇini[36] and promulgated by Hermann Grassmann in 1863.
Second, it was found that sometimes sound changes occurred in contexts that were later lost. For instance, in Sanskrit velars (k-like sounds) were replaced by palatals (ch-like sounds) whenever the following vowel was *i or *e.[37] Subsequent to this change, all instances of *e were replaced by a.[38] The situation would have been unreconstructable, had not the original distribution of e and a been recoverable from the evidence of other Indo-European languages.[39] For instance, Latin suffix que, "and", preserves the original *e vowel that caused the consonant shift in Sanskrit:
| 1. | *ke | Pre-Sanskrit "and" |
| 2. | *ce | Velars replaced by palatals before *i and *e |
| 3. | ca | The attested Sanskrit form. *e has become a |
| 4. | ca | Pronounced ča, Avestan "and" |
Verner's Law, discovered by Karl Verner in about 1875, is a similar case: the voicing of consonants in Germanic languages underwent a change that was determined by the position of the old Indo-European accent. Following the change, the accent shifted to initial position.[40] Verner solved the puzzle by comparing the Germanic voicing pattern with Greek and Sanskrit accent patterns.
This stage of the comparative method, therefore, involves examining the correspondence sets discovered in step 2 and seeing which of them apply only in certain contexts. If two (or more) sets apply in complementary distribution, they can be assumed to reflect a single original phoneme: "some sound changes, particularly conditioned sound changes, can result in a proto-sound being associated with more than one correspondence set".[41]
For example, the following potential cognate list can be established for Romance languages, which descend from Latin:
| Italian | Spanish | Portuguese | French | Gloss | |
|---|---|---|---|---|---|
| 1. | corpo | cuerpo | corpo | corps | body |
| 2. | crudo | crudo | cru | cru | raw |
| 3. | catena | cadena | cadeia | chaîne | chain |
| 4. | cacciare | cazar | caçar | chasser | to hunt |
They evidence two correspondence sets, k : k and k : ʃ:
| Italian | Spanish | Portuguese | French | |
|---|---|---|---|---|
| 1. | k | k | k | k |
| 2. | k | k | k | ʃ |
Since French ʃ only occurs before a where the other languages also have a, while French k occurs elsewhere, the difference is due to different environments (being before an a conditions the change) and the sets are complementary. They can therefore be assumed to reflect a single proto-phoneme (in this case *k, spelled <c> in Latin).[42] The original words are corpus, crudus, catena and captiare, all with an initial k-sound. If more evidence along these lines were given, one might conclude to an alteration of the original k because of a different environment.
A more complex case involves consonant clusters in Proto-Algonquian. The Algonquianist Leonard Bloomfield used the reflexes of the clusters in four of the daughter languages to reconstruct the following correspondence sets:[43]
| Ojibwe | Meskwaki | Plains Cree | Menomini | |
|---|---|---|---|---|
| 1. | kk | hk | hk | hk |
| 2. | kk | hk | sk | hk |
| 3. | sk | hk | sk | t͡ʃk |
| 4. | ʃk | ʃk | sk | sk |
| 5. | sk | ʃk | hk | hk |
Although all five correspondence sets overlap with one another in various places, they are not in complementary distribution, and so Bloomfield recognized that a different cluster must be reconstructed for each set; his reconstructions were, respectively, *hk, *xk, *čk (=[t͡ʃk]), *šk (=[ʃk]), and çk (where ‘x’ and ‘ç’ are arbitrary symbols, not attempts to guess the phonetic value of the proto-phonemes).[44]
Step 4, reconstruct proto-phonemes
Typology assists in deciding what reconstruction best fits the data. For example, the voicing of voiceless stops between vowels is common, but not the devoicing of voiced stops there. If a correspondence -t- : -d- between vowels is found in two languages, the proto-phoneme is more likely to be *-t-, with a development to the voiced form in the second language. The opposite reconstruction would create a rare type.
However, unusual sound changes do occur. The Proto-Indo-European word for two, for example, is reconstructed as *dwō, which is reflected in Classical Armenian as erku. Several other cognates demonstrate a regular change *dw- → erk- in Armenian.[45] Similarly, in Bearlake, a dialect of the Athabaskan language of Slavey, there has been a sound change of Proto-Athabaskan *ts → Bearlake kʷ.[46] It is very unlikely that *dw- changed directly into erk- and *ts into kʷ, but instead they must have gone through several intermediate steps to arrive at the later forms. It is not phonetic similarity which matters when utilizing the comparative method, but regular sound correspondences.[31]
By the Principle of Economy, the reconstruction of a proto-phoneme should require as few sound changes as possible to arrive at the modern reflexes in the daughter languages. For example, Algonquian languages exhibit the following correspondence set:[47][48]
| Ojibwe | Míkmaq | Cree | Munsee | Blackfoot | Arapaho |
|---|---|---|---|---|---|
| m | m | m | m | m | b |
The simplest reconstruction for this set would be either *m or *b. Both *m → b and *b → m are likely. Because m occurs in five of the languages, and b in only one, if *b is reconstructed, then it is necessary to assume five separate changes of *b → m, whereas if *m is reconstructed, it is only necessary to assume a single change of *m → b. *m would be most economical. (This argument assumes that the languages other than Arapaho are at least partly independent of each other. If they all formed a common subgroup, the development *b → m would only have to be assumed having occurred once.)
Step 5, examine the reconstructed system typologically
In the final step, the linguist checks to see how the proto-phonemes fit the known typological constraints. For example, in a hypothetical system,
| p | t | k |
|---|---|---|
| b | ||
| n | ŋ | |
| l |
there is only one voiced stop, *b, and although there is an alveolar and a velar nasal, *n and *ŋ, there is no corresponding labial nasal. However, languages generally (though not always) tend to maintain symmetry in their phonemic inventories. In this case, the linguist might attempt to investigate the possibilities that what was earlier reconstructed as *b is in fact *m, or that the *n and *ŋ are in fact *d and *g.
Even a symmetrical system can be typologically suspicious. For example, the traditional Proto-Indo-European stop inventory is:[49]
| Labials | Dentals | Velars | Labiovelars | Palatovelars | |
|---|---|---|---|---|---|
| Voiceless | p | t | k | kʷ | kʲ |
| Voiced | (b) | d | g | ɡʷ | ɡʲ |
| Voiced aspirated | bʱ | dʱ | ɡʱ | ɡʷʱ | ɡʲʱ |
An earlier voiceless aspirated row was removed on grounds of insufficient evidence. Since the mid-20th century, a number of linguists have argued that this phonology is implausible;[50] that it is extremely unlikely for a language to have a voiced aspirated (breathy voice) series without a corresponding voiceless aspirated series. A potential solution was provided by Thomas Gamkrelidze and Vyacheslav Ivanov, who argued that the series traditionally reconstructed as plain voiced should in fact be reconstructed as glottalized — either implosive (ɓ, ɗ, ɠ) or ejective (pʼ, tʼ, kʼ). The plain voiceless and voiced aspirated series would thus be replaced by just voiceless and voiced, with aspiration being a non-distinctive quality of both.[51] This example of the application of linguistic typology to linguistic reconstruction has become known as the Glottalic Theory. It has a large number of proponents but is not generally accepted.[52] As an alternative, the voiceless aspirated row was restored.
The reconstruction of proto-sounds logically precedes the reconstruction of grammatical morphemes (word-forming affixes and inflectional endings), patterns of declension and conjugation, and so on. The full reconstruction of an unrecorded protolanguage is an open-ended task.
Limitations
Problems with the history of historical linguistics
The limitations of the comparative method were recognized by the very linguists who developed it,[53] but it is still seen as a valuable tool. In the case of Indo-European, the method seemed to at least partially validate the centuries-old search for an Ursprache, the original language. These others were presumed ordered in a family tree, becoming the Tree model of the neogrammarians.
The archaeologists followed suit, attempting to find archaeological evidence of a culture or cultures that could be presumed to have spoken a proto-language, such as Vere Gordon Childe's The Aryans: a study of Indo-European origins, 1926. Childe was a philologist turned archaeologist. These views culminated in the Siedlungsarchaologie, or "settlement-archaeology", of Gustaf Kossinna, becoming known as "Kossinna's Law." He asserted that cultures represent ethnic groups, including their languages. It was rejected as a law in the post-World-War-II era. The fall of Kossinna's Law removed the temporal and spatial framework previously applied to many proto-languages. Fox concludes:[54]
The Comparative Method as such is not, in fact, historical; it provides evidence of linguistic relationships to which we may give a historical interpretation. ...[Our increased knowledge about the historical processes involved] has probably made historical linguists less prone to equate the idealizations required by the method with historical reality. ...Provided we keep [the interpretation of the results and the method itself] apart, the Comparative Method can continue to be used in the reconstruction of earlier stages of languages.
Proto-languages can be verified in many historical instances, such as Latin. Although no longer a law, settlement-archaeology is known to be essentially valid for some cultures that straddle history and prehistory, such as the Celtic Iron Age (mainly Celtic) and Mycenaean civilization (mainly Greek). None of these models can be or have been completely rejected, and yet none alone are sufficient.
Problems with the neogrammarian hypothesis
The foundation of the comparative method, and of comparative linguistics in general, is the Neogrammarians' fundamental assumption that "sound laws have no exceptions." When it was initially proposed, critics of the Neogrammarians proposed an alternate position, summarized by the maxim "each word has its own history".[55] Several types of change do in fact alter words in non-regular ways. Unless identified, they may hide or distort laws and cause false perceptions of relationship.
Borrowing
All languages borrow words from other languages in various contexts. They are likely to have followed the laws of the languages from which they were borrowed rather than the laws of the borrowing language.
Areal diffusion
Borrowing on a larger scale occurs in areal diffusion, when features are adopted by contiguous languages over a geographical area. The borrowing may be phonological, morphological or lexical. A false proto-language over the area may be reconstructed for them or may be taken to be a third language serving as a source of diffused features.[56]
Several areal features and other influences may converge to form a sprachbund, a wider region sharing features that appear to be related but are diffusional. For instance, the Mainland Southeast Asia linguistic area suggested several false classifications of such languages as Chinese, Thai and Vietnamese before it was recognized.
Random mutations
Sporadic changes, such as irregular inflections, compounding, and abbreviation, do not follow any laws. For example, the Spanish words palabra ('word'), peligro ('danger') and milagro ('miracle') should have been parabla, periglo, miraglo by regular sound changes from the Latin parabŏla, perīcŭlum and mīrācŭlum, but the r and l changed places by sporadic metathesis.[57]
Analogy
Analogy is the sporadic change of a feature to be like another feature in the same or a different language. It may affect a single word or be generalized to an entire class of features, such as a verb paradigm. For example, the Russian word for nine, by regular sound changes from Proto-Slavic, should have been /nʲevʲatʲ/, but is in fact /dʲevʲatʲ/. It is believed that the initial nʲ- changed to dʲ- under influence of the word for "ten" in Russian, /dʲesʲatʲ/.[58]
Gradual application
Students of contemporary language changes, such as William Labov, note that even a systematic sound change is at first applied in an unsystematic fashion, with the percentage of its occurrence in a person's speech dependent on various social factors.[59] The sound change gradually spreads, a process known as lexical diffusion. While not invalidating the Neogrammarians' axiom that "sound laws have no exceptions", their gradual application shows that they do not always apply to all lexical items at the same time. Hock notes,[60] "While it probably is true in the long run every word has its own history, it is not justified to conclude as some linguists have, that therefore the Neogrammarian position on the nature of linguistic change is falsified."
Problems with the Tree Model
The comparative method is used to construct a Tree model (German Stammbaum) of language evolution,[61] in which daughter languages are seen as branching from the proto-language, gradually growing more distant from it through accumulated phonological, morpho-syntactic, and lexical changes.
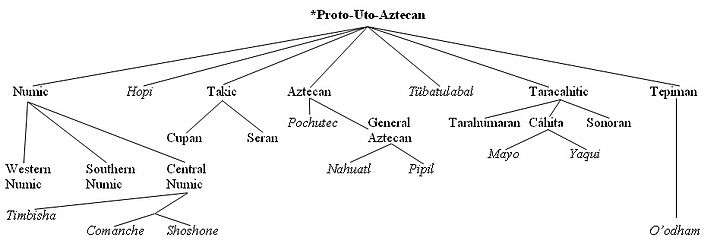
The presumption of a well-defined node
The tree model features nodes that are presumed to be distinct proto-languages existing independently in distinct regions during distinct historical times. The reconstruction of unattested proto-languages lends itself to that illusion: they cannot be verified and the linguist is free to select whatever definite times and places for them seem best. Right from the outset of Indo-European studies, however, Thomas Young said:[64]
It is not, however, very easy to say what the definition should be that should constitute a separate language, but it seems most natural to call those languages distinct, of which the one cannot be understood by common persons in the habit of speaking the other … Still, however, it may remain doubtfull whether the Danes and the Swedes could not, in general, understand each other tolerably well … nor is it possible to say if the twenty ways of pronouncing the sounds, belonging to the Chinese characters, ought or ought not to be considered as so many languages or dialects… But, … the languages so nearly allied must stand next to each other in a systematic order…
The assumption of uniformity in a proto-language, implicit in the comparative method, is problematic. Even in small language communities there are always dialect differences, whether based on area, gender, class, or other factors. The Pirahã language of Brazil is spoken by only several hundred people, but it has at least two different dialects, one spoken by men and one by women.[65] Campbell points out:[66]
It is not so much that the comparative method 'assumes' no variation; rather, it is just that there is nothing built into the comparative method which would allow it to address variation directly....This assumption of uniformity is a reasonable idealization; it does no more damage to the understanding of the language than, say, modern reference grammars do which concentrate on a language's general structure, typically leaving out consideration of regional or social variation.
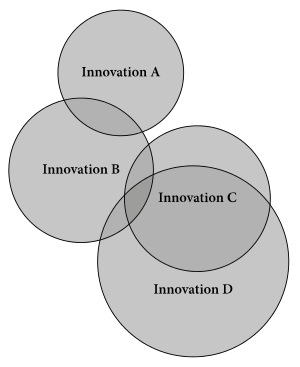
Different dialects, as they evolve into separate languages, remain in contact with one another and influence each other. Even after they are considered distinct, languages near to one another continue to influence each other, often sharing grammatical, phonological, and lexical innovations. A change in one language of a family may spread to neighboring languages; and multiple waves of change are communicated like waves across language and dialect boundaries, each with its own randomly delimited range.[67] If a language is divided into an inventory of features, each with its own time and range (isoglosses), they do not all coincide. History and prehistory may not offer a time and place for a distinct coincidence, as may be the case for proto-Italic, in which case the proto-language is only a concept. However, Hock[68] observes:
The discovery in the late nineteenth century that isoglosses can cut across well-established linguistic boundaries at first created considerable attention and controversy. And it became fashionable to oppose a wave theory to a tree theory... Today, however, it is quite evident that the phenomena referred to by these two terms are complementary aspects of linguistic change...
Subjectivity of the reconstruction
The reconstruction of unknown proto-languages is inherently subjective. In the Proto-Algonquian example above, the choice of *m as the parent phoneme is only likely, not certain. It is conceivable that a Proto-Algonquian language with *b in those positions split into two branches, one which preserved *b and one which changed it to *m instead; and while the first branch only developed into Arapaho, the second spread out wider and developed into all the other Algonquian tribes. It is also possible that the nearest common ancestor of the Algonquian languages used some other sound instead, such as *p, which eventually mutated to *b in one branch and to *m in the other. While examples of strikingly complicated and even circular developments are indeed known to have occurred (such as PIE *t > Pre-Proto-Germanic *þ > PG *ð > Proto-West-Germanic *d > Old High German t in fater > Modern German Vater), in the absence of any evidence or other reason to postulate a more complicated development, the preference of a simpler explanation is justified by the principle of parsimony, also known as Occam's razor. Since reconstruction involves many of these choices, some linguists prefer to view the reconstructed features as abstract representations of sound correspondences, rather than as objects with a historical time and place.
The existence of proto-languages and the validity of the comparative method is verifiable in cases where the reconstruction can be matched to a known language, which may only be known as a shadow in the loanwords of another language. For example, Finnic languages such as Finnish have borrowed many words from an early stage of Germanic, and the shape of the loans matches the forms that have been reconstructed for Proto-Germanic. Finnish kuningas 'king' and kaunis 'beautiful' match the Germanic reconstructions *kuningaz and *skauniz (> German König 'king', schön 'beautiful').[69]
Additional models
The Wave model was developed in the 1870s as an alternative to the Tree model, in order to represent the historical patterns of language diversification. Both the tree-based and the wave-based representations are compatible with the Comparative Method.
By contrast, some approaches are incompatible with the Comparative method, including glottochronology and mass lexical comparison. Most historical linguists consider these to be flawed and unreliable.[70]
Notes
- ↑ Lehmann 1993, pp. 31 ff.
- ↑ Lehmann 1993, p. 26.
- ↑ Schleicher 1874, p. 8.
- ↑ Lyovin 1997, pp. 1–2.
- ↑ Beekes 1995, p. 25.
- ↑ Beekes 1995, pp. 22, 27–29.
- ↑ Campbell 2000, p. 1341
- ↑ "The reason for this similarity and the cause of this intermixture was their close neighboring in the land and their genealogical closeness, since Terah the father of Abraham was Syrian, and Laban was Syrian. Ishmael and Kedar were Arabized from the Time of Division, the time of the confounding [of tongues] at Babel, and Abraham and Isaac and Jacob (peace be upon them) retained the Holy Tongue from the original Adam." Introduction of Risalat Yehuda Ibn Quraysh - مقدمة رسالة يهوذا بن قريش
- 1 2 George van Driem The genesis of polyphyletic linguistics Archived 26 July 2011 at the Wayback Machine.
- 1 2 Szemerényi 1996, p. 6.
- ↑ Jones, Sir William. Abbattista, Guido, ed. "The Third Anniversary Discourse delivered 2 February 1786 By the President [on the Hindus]". Eliohs Electronic Library of Historiography. Retrieved 18 December 2009.
- ↑ Szemerényi 1996, pp. 5–6
- ↑ Szemerényi 1996, p. 7
- ↑ Szémerenyi 1996, p. 17
- ↑ Szemerényi 1996, pp. 7–8.
- ↑ Szemerényi 1996, p. 19.
- ↑ Szemerényi 1996, p. 20.
- ↑ Szemerényi 1996, p. 21.
- ↑ Campbell 2004, pp. 126–147
- ↑ Crowley 1992, pp. 108–109
- 1 2 Lyovin 1997, pp. 2–3.
- ↑ The table is modified from Campbell 2004, pp. 168–169 and Crowley 1992, pp. 88–89 using sources such as Churchward 1959 for Tongan, and Pukui 1986 for Hawaiian.
- ↑ Lyovin 1997, pp. 3–5.
- ↑ "Taboo". Dictionary.com.
- ↑ Lyovin 1997, p. 3.
- ↑ Campbell 2004, pp. 65, 300.
- ↑ "They". Dictionary.com.
- ↑ Nevins, Andrew, David Pesetsky and Cilene Rodrigues (2009). "Piraha Exceptionality: a Reassessment", Language", 85.2, 355-404.
- ↑ Thomason 2005, pp. 8–12 in pdf; Aikhenvald 1999, p. 355.
- ↑ "Superficially, however, the Piraha pronouns don't look much like the Tupi–Guarani pronouns; so this proposal will not be convincing without some additional information about the phonology of Piraha that shows how the phonetic realizations of the Tupi–Guarani forms align with the Piraha phonemic system." "Pronoun borrowing" Sarah G. Thomason & Daniel L. Everett University of Michigan & University of Manchester
- 1 2 Lyovin 1997, p. 2.
- 1 2 Beekes 1995, p. 127
- ↑ "devil". Dictionary.com.
- ↑ In Latin, <c> represents /k/; dingua is an Old Latin form of the word later attested as lingua.
- ↑ Beekes 1995, p. 128.
- ↑ Sag 1974, p. 591; Janda 1989.
- ↑ The asterisk (*) means that the sound is inferred/reconstructed, rather than historically documented or attested
- ↑ Or, more accurately, earlier *e, *o, and *a merged as a.
- ↑ Beekes 1995, pp. 60–61.
- ↑ Beekes 1995, pp. 130–131.
- ↑ Campbell 2004, p. 136.
- ↑ Campbell 2004, p. 26.
- ↑ The table is modified from that in Campbell 2004, p. 141.
- ↑ Bloomfield 1925.
- ↑ Szemerényi 1996, p. 28; citing Szemerényi 1960, p. 96.
- ↑ Campbell 1997, p. 113.
- ↑ Redish, Laura; Lewis, Orrin (1998–2009). "Vocabulary Words in the Algonquian Language Family". Native Languages of the Americas. Retrieved 20 December 2009.
- ↑ Goddard 1974.
- ↑ Beekes 1995, p. 124.
- ↑ Szemerényi 1996, p. 143.
- ↑ Beekes 1995, pp. 109–113.
- ↑ Szemerényi 1996, pp. 151–152.
- ↑ Lyovin 1997, pp. 4–5, 7–8.
- ↑ Fox 1995, pp. 141–2.
- ↑ Szemerényi 1996, p. 23.
- ↑ Aikhenvald 2001, pp. 2–3.
- ↑ Campbell 2004, p. 39.
- ↑ Beekes 1995, p. 79.
- ↑ Beekes 1995, p. 55; Szemerényi 1996, p. 3.
- ↑ Hock 1991, pp. 446–447.
- ↑ Lyovin 1997, pp. 7–8.
- ↑ The diagram is based on the hierarchical list in Mithun 1999, pp. 539–540 and on the map in Campbell 1997, p. 358.
- ↑ This diagram is based partly on the one found in Fox 1995:128, and Johannes Schmidt, 1872. Die Verwandtschaftsverhältnisse der indogermanischen Sprachen. Weimar: H. Böhlau
- ↑ Young, Thomas (1855), "Languages, From the Supplement to the Encyclopædia Britannica, vol. V, 1824", in Leitch, John, Miscellaneous works of the late Thomas Young, Volume III, Hieroglyphical Essays and Correspondence, &c., London: John Murray, p. 480
- ↑ Aikhenvald 1999, p. 354; Ladefoged 2003, p. 14.
- ↑ Campbell 2004, pp. 146–147
- ↑ Fox 1995, p. 129
- ↑ Hock 1991, p. 454.
- ↑ Kylstra 1996, p. 62 for KAUNIS, p. 122 for KUNINGAS.
- ↑ Campbell 2004, p. 201; Lyovin 1997, p. 8.
See also
References
- Aikhenvald, Alexandra Y.; Dixon, R. M. W. (1999), "Other small families and isolates", in Dixon, R. M. W.; Aikhenvald, Alexandra Y., The Amazonian Languages, Cambridge University Press, pp. 341–384, ISBN 0-521-57021-2.
- Aikhenvald, Alexandra Y.; Dixon, R. M. W. (2001), "Introduction", in Dixon, R. M. W.; Aikhenvald, Alexandra Y., Areal Diffusion and Genetic Inheritance: Problems in Comparative Linguistics, Oxford Linguistics, Oxford: Oxford University Press, pp. 1–22.
- Beekes, Robert S. P. (1995). Comparative Indo-European Linguistics. Amsterdam: John Benjamins.
- Bloomfield, Leonard (December 1925). "On the Sound System of Central Algonquian". Language. 1 (4): 130–56. doi:10.2307/409540.
- Campbell, George L. (2000). Compendium of the World's Languages (2nd ed.). London: Routledge.
- Campbell, Lyle (1997). American Indian Languages: The Historical Linguistics of Native America. New York: Oxford University Press.
- Campbell, Lyle (2004). Historical Linguistics: An Introduction (2nd ed.). Cambridge: The MIT Press. ISBN 978-0-262-53267-9.
- Churchward, C. Maxwell (1959). Tongan Dictionary. Tonga: Government Printing Office.
- Crowley, Terry (1992). An Introduction to Historical Linguistics (2nd ed.). Auckland: Oxford University Press.
- Fox, Anthony (1995). Linguistic Reconstruction: An Introduction to Theory and Method. New York: Oxford University Press.
- Goddard, Ives (1974). "An Outline of the Historical Phonology of Arapaho and Atsina". International Journal of American Linguistics. 40: 102–16. doi:10.1086/465292..
- Hock, Hans Henrich (1991). Principles of Historical Linguistics (2nd revised and updated ed.). Berlin: Walter de Gruyter.
- Janda, Richard D.; Joseph, Brian D. (1989). "In Further Defence of a Non-Phonological Account for Sanskrit Root-Initial Aspiration Alternations" (PDF). Proceedings of the Fifth Eastern States Conference on Linguistics. Columbus, Ohio: Ohio State University Department of Linguistics: 246–260.
- Kylstra, A. D.; Sirkka-Liisa, Hahmo; Hofstra, Tette; Nikkilä, Osmo (1996). Lexikon der älteren germanischen Lehnwörter in den ostseefinnischen Sprachen (in German). Band II: K-O. Amsterdam, Atlanta: Rodopi B.V.
- Labov, William (2007). "Transmission and diffusion". Language. 83: 344–387. doi:10.1353/lan.2007.0082.
- Ladefoged, Peter (2003). Phonetic Data Analysis: An Introduction to Fieldwork and Instrumental Techniques. Oxford: Blackwell.
- Lehmann, Winfred P. (1993). Theoretical Bases of Indo-European Linguistics. London: Routledge.
- Lyovin, Anatole V. (1997). An Introduction to the Languages of the World. New York: Oxford University Press, Inc. ISBN 0-19-508116-1.
- Mithun, Marianne (1999). The Languages of Native North America. Cambridge Language Surveys. Cambridge: Cambridge University Press.
- Pukui, Mary Kawena; Samuel H. Elbert (1986). Hawaiian Dictionary. Honolulu: University of Hawai‘i Press. ISBN 0-8248-0703-0.
- Sag, Ivan. A. (Autumn 1974). "The Grassmann's Law Ordering Pseudoparadox". Linguistic Inquiry. 5 (4): 591–607..
- Schleicher, August; Bendall, Herbert, Translator (1874, 1877) [1871]. A Compendium of the Comparative Grammar of the Indo-European, Sanskrit, Greek, and Latin Languages, translated from the third German edition. London: Trübner and Co. Check date values in:
|date=(help) - Szemerényi, Oswald J. L. (1960). Studies in the Indo-European System of Numerals. Heidelberg: C. Winter.
- Szemerényi, Oswald J. L. (1996). Introduction to Indo-European Linguistics (4th ed.). Oxford: Oxford University Press.
- Thomason, Sarah G.; Everett, Daniel L. (2005). "Pronoun Borrowing". Proceedings of the annual meeting of the Berkeley Linguistics Society. 27: 301 ff.
- Trask, R. L. (1996). Historical Linguistics. New York: Oxford University Press.
- Zuckermann, Ghil'ad (2009). "Hybridity versus Revivability: Multiple Causation, Forms and Patterns" (PDF). Journal of Language Contact — Varia (2): 40–67.
External links
- Hubbard, Kathleen. "Everything you ever wanted to know about Proto-Indo-European (and the comparative method), but were afraid to ask!". University of Texas Department of Classics. Retrieved 22 December 2009.
- Gordon, Matthew. "Week 3:Comparative method and linguistic reconstruction" (pdf). Department of Linguistics, University of California, Santa Barbara. Retrieved 22 December 2009.