DNA-binding domain
A DNA-binding domain (DBD) is an independently folded protein domain that contains at least one structural motif that recognizes double- or single-stranded DNA. A DBD can recognize a specific DNA sequence (a recognition sequence) or have a general affinity to DNA.[1] Some DNA-binding domains may also include nucleic acids in their folded structure.
Function
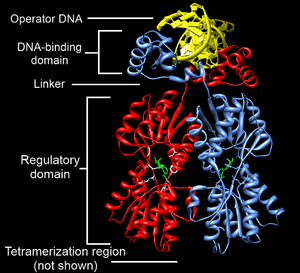
One or more DNA-binding domains are often part of a larger protein consisting of further protein domains with differing function. The extra domains often regulate the activity of the DNA-binding domain. The function of DNA binding is either structural or involves transcription regulation, with the two roles sometimes overlapping.
DNA-binding domains with functions involving DNA structure have biological roles in DNA replication, repair, storage, and modification, such as methylation.
Many proteins involved in the regulation of gene expression contain DNA-binding domains. For example, proteins that regulate transcription by binding DNA are called transcription factors. The final output of most cellular signaling cascades is gene regulation.
The DBD interacts with the nucleotides of DNA in a DNA sequence-specific or non-sequence-specific manner, but even non-sequence-specific recognition involves some sort of molecular complementarity between protein and DNA. DNA recognition by the DBD can occur at the major or minor groove of DNA, or at the sugar-phosphate DNA backbone (see the structure of DNA). Each specific type of DNA recognition is tailored to the protein's function. For example, the DNA-cutting enzyme DNAse I cuts DNA almost randomly and so must bind to DNA in a non-sequence-specific manner. But, even so, DNAse I recognizes a certain 3-D DNA structure, yielding a somewhat specific DNA cleavage pattern that can be useful for studying DNA recognition by a technique called DNA footprinting.
Many DNA-binding domains must recognize specific DNA sequences, such as DBDs of transcription factors that activate specific genes, or those of enzymes that modify DNA at specific sites, like restriction enzymes and telomerase. The hydrogen bonding pattern in the DNA major groove is less degenerate than that of the DNA minor groove, providing a more attractive site for sequence-specific DNA recognition.
The specificity of DNA-binding proteins can be studied using many biochemical and biophysical techniques, such as gel electrophoresis, analytical ultracentrifugation, calorimetry, DNA mutation, protein structure mutation or modification, nuclear magnetic resonance, x-ray crystallography, surface plasmon resonance, electron paramagnetic resonance, cross-linking and microscale thermophoresis (MST).
Types of DNA-binding domains
Helix-turn-helix
Originally discovered in bacteria, the helix-turn-helix motif is commonly found in repressor proteins and is about 20 amino acids long. In eukaryotes, the homeodomain comprises 2 helices, one of which recognizes the DNA (aka recognition helix). They are common in proteins that regulate developmental processes (PROSITE HTH).
Zinc finger
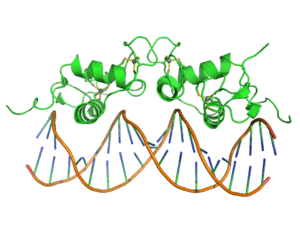
The zinc finger domain is generally between 23 and 28 amino acids long and is stabilized by coordinating zinc ions with regularly spaced zinc-coordinating residues (either histidines or cysteines). The most common class of zinc finger (Cys2His2) coordinates a single zinc ion and consists of a recognition helix and a 2-strand beta-sheet.[3] In transcription factors these domains are often found in arrays (usually separated by short linker sequences) and adjacent fingers are spaced at 3 basepair intervals when bound to DNA.
Leucine zipper
The basic leucine zipper (bZIP) domain contains an alpha helix with a leucine at every 7th amino acid. If two such helices find one another, the leucines can interact as the teeth in a zipper, allowing dimerization of two proteins. When binding to the DNA, basic amino acid residues bind to the sugar-phosphate backbone while the helices sit in the major grooves. It regulates gene expression.
Winged helix
Consisting of about 110 amino acids, the winged helix (WH) domain has four helices and a two-strand beta-sheet.
Winged helix turn helix
The winged helix-turn-helix (wHTH) domain SCOP 46785 is typically 85-90 amino acids long. It is formed by a 3-helical bundle and a 4-strand beta-sheet (wing).
Helix-loop-helix
The basic helix-loop-helix (bHLH) domain is found in some transcription factors and is characterized by two alpha helices (α-helixes) connected by a loop. One helix is typically smaller and due to the flexibility of the loop, allows dimerization by folding and packing against another helix. The larger helix typically contains the DNA-binding regions.
HMG-box
HMG-box domains are found in high mobility group proteins which are involved in a variety of DNA-dependent processes like replication and transcription. The domain consists of three alpha helices separated by loops.
Wor3 domain
Wor3 domains, named after the White–Opaque Regulator 3 (Wor3) in Candida albicans arose more recently in evolutionary time than most previously described DNA-binding domains and are restricted to a small number of fungi.[4]
OB-fold domain
The OB-fold is a small structural motif originally named for its oligonucleotide/oligosaccharide binding properties. OB-fold domains range between 70 and 150 amino acids in length.[5] OB-folds bind single-stranded DNA, and hence are single-stranded binding proteins.[5]
OB-fold proteins have been identified as critical for DNA replication, DNA recombination, DNA repair, transcription, translation, cold shock response, and telomere maintenance.[6]
Unusual DNA binding domains
Immunoglobulin fold
The immunoglobulin domain (InterPro: IPR013783) consists of a beta-sheet structure with large connecting loops, which serve to recognize either DNA major grooves or antigens. Usually found in immunoglobulin proteins, they are also present in Stat proteins of the cytokine pathway. This is likely because the cytokine pathway evolved relatively recently and has made use of systems that were already functional, rather than creating its own.
B3 domain
The B3 DBD (InterPro: IPR003340, SCOP 117343) is found exclusively in transcription factors from higher plants and restriction endonucleases EcoRII and BfiI and typically consists of 100-120 residues. It includes seven beta sheets and two alpha helices, which form a DNA-binding pseudobarrel protein fold.
TAL effector DNA-binding domain
TAL effectors are found in bacterial plant pathogens of the genus Xanthomonas and are involved in regulating the genes of the host plant in order to facilitate bacterial virulence, proliferation, and dissemination.[7] They contain a central region of tandem 33-35 residue repeats and each repeat region encodes a single DNA base in the TALE's binding site.[8][9] Within the repeat it is residue 13 alone that directly contacts the DNA base, determining sequence specificity, while other positions make contacts with the DNA backbone, stabilising the DNA-binding interaction.[10] Each repeat within the array takes the form of paired alpha-helices, while the whole repeat array forms a right-handed superhelix, wrapping around the DNA-double helix. TAL effector repeat arrays have been shown to contract upon DNA binding and a two-state search mechanism has been proposed whereby the elongated TALE begins to contract around the DNA beginning with a successful Thymine recognition from a unique repeat unit N-terminal of the core TAL-effector repeat array.[11] Related proteins are found in bacterial plant pathogen Ralstonia solanacearum,[12] the fungal endosymbiont Burkholderia rhizoxinica [13] and two as-yet unidentified marine-microorganisms.[14] The DNA binding code and the structure of the repeat array is conserved between these groups, referred to collectively as the TALE-likes.
RNA-guided DNA-binding domain
The CRISPR/Cas system of Streptococcus pyogenes can be programmed to direct both activation[15] and repression to natural and artificial eukaryotic promoters through the simple engineering of guide RNAs with base-pairing complementarity to target DNA sites.[16] Cas9 can be used as a customizable RNA-guided DNA-binding platform. Domain Cas9 can be functionalized with regulatory domains of interest (e.g.,activation, repression, or epigenetic effector) or with endonuclease domain as a versatile tool for genome engineering biology.[17][18] and then be targeted to multiple loci using different guide RNAs.
See also
References
- ↑ Lilley, David M. J. (1995). DNA-protein: structural interactions. Oxford: IRL Press at Oxford University Press. ISBN 0-19-963453-X.
- ↑ Swint-Kruse L, Matthews KS (April 2009). "Allostery in the LacI/GalR family: variations on a theme". Curr. Opin. Microbiol. 12 (2): 129–37. doi:10.1016/j.mib.2009.01.009. PMC 2688824
 . PMID 19269243.
. PMID 19269243. - ↑ Pabo CO, Peisach E, Grant RA (2001). "Design and selection of novel Cys2His2 zinc finger proteins". Annual Review of Biochemistry. 70: 313–40. doi:10.1146/annurev.biochem.70.1.313. PMID 11395410.
- ↑ Lohse MB, Hernday AD, Fordyce PM, Noiman L, Sorrells TR, Hanson-Smith V, Nobile CJ, DeRisi JL, Johnson AD (May 2013). "Identification and characterization of a previously undescribed family of sequence-specific DNA-binding domains". Proceedings of the National Academy of Sciences of the United States of America. 110 (19): 7660–5. Bibcode:2013PNAS..110.7660L. doi:10.1073/pnas.1221734110. PMC 3651432. PMID 23610392.
- 1 2 Flynn RL, Zou L (2010). "Oligonucleotide/oligosaccharide-binding fold proteins: a growing family of genome guardians". Critical Reviews in Biochemistry and Molecular Biology. 45 (4): 266–275. doi:10.3109/10409238.2010.488216. PMC 2906097. PMID 20515430.
- ↑ Theobald DL, Mitton-Fry RM, Wuttke DS (2003). "Nucleic acid recognition by OB-fold proteins". Annu Rev Biophys Biomol Struct. 32: 115–33. doi:10.1146/annurev.biophys.32.110601.142506. PMC 1564333. PMID 12598368.
- ↑ Boch J, Bonas U (2010). "Xanthomonas AvrBs3 family-type III effectors: discovery and function". Annual Review of Phytopathology. 48: 419–36. doi:10.1146/annurev-phyto-080508-081936. PMID 19400638.
- ↑ Moscou MJ, Bogdanove AJ (Dec 2009). "A simple cipher governs DNA recognition by TAL effectors". Science. 326 (5959): 1501. Bibcode:2009Sci...326.1501M. doi:10.1126/science.1178817. PMID 19933106.
- ↑ Boch J, Scholze H, Schornack S, Landgraf A, Hahn S, Kay S, Lahaye T, Nickstadt A, Bonas U (Dec 2009). "Breaking the code of DNA binding specificity of TAL-type III effectors". Science. 326 (5959): 1509–12. Bibcode:2009Sci...326.1509B. doi:10.1126/science.1178811. PMID 19933107.
- ↑ Mak, Amanda Nga-Sze; Bradley, Philip; Cernadas, Raul A.; Bogdanove, Adam J.; Stoddard, Barry L. (10 February 2012). "The crystal structure of TAL effector PthXo1 bound to its DNA target". Science (New York, N.Y.). 335 (6069): 716–719. doi:10.1126/science.1216211. ISSN 1095-9203. PMID 22223736.
- ↑ Cuculis, Luke; Abil, Zhanar; Zhao, Huimin; Schroeder, Charles M. (1 June 2015). "Direct observation of TALE protein dynamics reveals a two-state search mechanism". Nature Communications. 6: 7277. doi:10.1038/ncomms8277.
- ↑ de Lange, Orlando; Schreiber, Tom; Schandry, Niklas; Radeck, Jara; Braun, Karl Heinz; Koszinowski, Julia; Heuer, Holger; Strauß, Annett; Lahaye, Thomas (August 2013). "Breaking the DNA-binding code of TAL effectors provides new possibilities to generate plant resistance genes against bacterial wilt disease". New Phytologist. 199 (3): 773–786. doi:10.1111/nph.12324.
- ↑ Juillerat, Alexandre; Bertonati, Claudia; Dubois, Gwendoline; Guyot, Valérie; Thomas, Séverine; Valton, Julien; Beurdeley, Marine; Silva, George H.; Daboussi, Fayza; Duchateau, Philippe (23 January 2014). "BurrH: a new modular DNA binding protein for genome engineering". Scientific Reports. 4. doi:10.1038/srep03831.
- ↑ de Lange, Orlando; Wolf, Christina; Thiel, Philipp; Krüger, Jens; Kleusch, Christian; Kohlbacher, Oliver; Lahaye, Thomas (19 October 2015). "DNA-binding proteins from marine bacteria expand the known sequence diversity of TALE-like repeats". Nucleic Acids Research: gkv1053. doi:10.1093/nar/gkv1053.
- ↑ Perez-Pinera P, Kocak DD, Vockley CM, Adler AF, Kabadi AM, Polstein LR, Thakore PI, Glass KA, Ousterout DG, Leong KW, Guilak F, Crawford GE, Reddy TE, Gersbach CA (Oct 2013). "RNA-guided gene activation by CRISPR-Cas9-based transcription factors". Nature Methods. 10 (10): 973–6. doi:10.1038/nmeth.2600. PMID 23892895.
- ↑ Farzadfard F, Perli SD, Lu TK (Oct 2013). "Tunable and multifunctional eukaryotic transcription factors based on CRISPR/Cas". ACS Synthetic Biology. 2 (10): 604–613. doi:10.1021/sb400081r. PMC 3805333. PMID 23977949.
- ↑ Cho SW, Kim S, Kim JM, Kim JS (Mar 2013). "Targeted genome engineering in human cells with the Cas9 RNA-guided endonuclease". Nature Biotechnology. 31 (3): 230–2. doi:10.1038/nbt.2507. PMID 23360966.
- ↑ Mali P, Esvelt KM, Church GM (Oct 2013). "Cas9 as a versatile tool for engineering biology". Nature Methods. 10 (10): 957–63. doi:10.1038/nmeth.2649. PMC 4051438. PMID 24076990.
External links
- DBD database of predicted transcription factors Kummerfeld SK, Teichmann SA (Jan 2006). "DBD: a transcription factor prediction database". Nucleic Acids Research. 34 (Database issue): D74–81. doi:10.1093/nar/gkj131. PMC 1347493. PMID 16381970. Uses a curated set of DNA-binding domains to predict transcription factors in all completely sequenced genomes
- Table of DNA-binding motifs
- DNA Footprinting at the US National Library of Medicine Medical Subject Headings (MeSH)
- DNA-Binding Proteins at the US National Library of Medicine Medical Subject Headings (MeSH)
- DNA-binding domains in PROSITE