Dependability
In systems engineering, dependability is a measure of a system's availability, reliability, and its maintainability, and maintenance support performance, and, in some cases, other characteristics such as durability, safety and security.[1] In software engineering, dependability is the ability to provide services that can defensibly be trusted within a time-period.[2] This may also encompass mechanisms designed to increase and maintain the dependability of a system or software.[3]
The International Electrotechnical Commission (IEC), via its Technical Committee TC 56 develops and maintains international standards that provide systematic methods and tools for dependability assessment and management of equipment, services, and systems throughout their life cycles.
Dependability can be broken down into three elements:
- Attributes - A way to assess the dependability of a system
- Threats - An understanding of the things that can affect the dependability of a system
- Means - Ways to increase a system's dependability
History
Some sources hold that word was coined in the nineteen-teens in Dodge Brothers automobile print advertising. But the word predates that period, with the Oxford English Dictionary finding its first use in 1901.
As interest in fault tolerance and system reliability increased in the 1960s and 1970s, dependability came to be a measure of [x] as measures of reliability came to encompass additional measures like safety and integrity.[4] In the early 1980s, Jean-Claude Laprie thus chose dependability as the term to encompass studies of fault tolerance and system reliability without the extension of meaning inherent in reliability.[5]
The field of dependability has evolved from these beginnings to be an internationally active field of research fostered by a number of prominent international conferences, notably the International Conference on Dependable Systems and Networks, the International Symposium on Reliable Distributed Systems and the International Symposium on Software Reliability Engineering.
Traditionally, dependability for a system incorporates availability, reliability, maintainability but since the 1980s, safety and security have been added to measures of dependability.[6]
Elements of dependability
Attributes
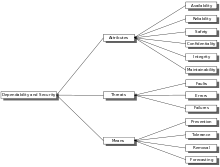
Attributes are qualities of a system. These can be assessed to determine its overall dependability using Qualitative or Quantitative measures. Avizienis et al. define the following Dependability Attributes:
- Availability - readiness for correct service
- Reliability - continuity of correct service
- Safety - absence of catastrophic consequences on the user(s) and the environment
- Integrity - absence of improper system alteration
- Maintainability - ability for a process to undergo modifications and repairs
As these definitions suggested, only Availability and Reliability are quantifiable by direct measurements whilst others are more subjective. For instance Safety cannot be measured directly via metrics but is a subjective assessment that requires judgmental information to be applied to give a level of confidence, whilst Reliability can be measured as failures over time.
Confidentiality, i.e. the absence of unauthorized disclosure of information is also used when addressing security. Security is a composite of Confidentiality, Integrity, and Availability. Security is sometimes classed as an attribute [7] but the current view is to aggregate it together with dependability and treat Dependability as a composite term called Dependability and Security.[3]
Practically, applying security measures to the appliances of a system generally improves the dependability by limiting the number of externally originated errors.
Threats
Threats are things that can affect a system and cause a drop in Dependability. There are three main terms that must be clearly understood:
- Fault: A fault (which is usually referred to as a bug for historic reasons) is a defect in a system. The presence of a fault in a system may or may not lead to a failure. For instance, although a system may contain a fault, its input and state conditions may never cause this fault to be executed so that an error occurs; and thus that particular fault never exhibits as a failure.
- Error: An error is a discrepancy between the intended behaviour of a system and its actual behaviour inside the system boundary. Errors occur at runtime when some part of the system enters an unexpected state due to the activation of a fault. Since errors are generated from invalid states they are hard to observe without special mechanisms, such as debuggers or debug output to logs.
- Failure: A failure is an instance in time when a system displays behaviour that is contrary to its specification. An error may not necessarily cause a failure, for instance an exception may be thrown by a system but this may be caught and handled using fault tolerance techniques so the overall operation of the system will conform to the specification.
It is important to note that Failures are recorded at the system boundary. They are basically Errors that have propagated to the system boundary and have become observable. Faults, Errors and Failures operate according to a mechanism. This mechanism is sometimes known as a Fault-Error-Failure chain.[8] As a general rule a fault, when activated, can lead to an error (which is an invalid state) and the invalid state generated by an error may lead to another error or a failure (which is an observable deviation from the specified behaviour at the system boundary).
Once a fault is activated an error is created. An error may act in the same way as a fault in that it can create further error conditions, therefore an error may propagate multiple times within a system boundary without causing an observable failure. If an error propagates outside the system boundary a failure is said to occur. A failure is basically the point at which it can be said that a service is failing to meet its specification. Since the output data from one service may be fed into another, a failure in one service may propagate into another service as a fault so a chain can be formed of the form: Fault leading to Error leading to Failure leading to Error, etc.
Means
Since the mechanism of a Fault-Error-Chain is understood it is possible to construct means to break these chains and thereby increase the dependability of a system. Four means have been identified so far:
- Prevention
- Removal
- Forecasting
- Tolerance
Fault Prevention deals with preventing faults being incorporated into a system. This can be accomplished by use of development methodologies and good implementation techniques.
Fault Removal can be sub-divided into two sub-categories: Removal During Development and Removal During Use.
Removal during development requires verification so that faults can be detected and removed before a system is put into production. Once systems have been put into production a system is needed to record failures and remove them via a maintenance cycle.
Fault Forecasting predicts likely faults so that they can be removed or their effects can be circumvented.
Fault Tolerance deals with putting mechanisms in place that will allow a system to still deliver the required service in the presence of faults, although that service may be at a degraded level.
Dependability means are intended to reduce the number of failures presented to the user of a system. Failures are traditionally recorded over time and it is useful to understand how their frequency is measured so that the effectiveness of means can be assessed.
Dependability of information systems and survivability
Recent works, such [9] upon dependability take benefit of structured information systems, e.g. with SOA, to introduce a more efficient ability, the survivability, thus taking into account the degraded services that an Information System sustains or resumes after a non-maskable failure.
The flexibility of current frameworks encourage system architects to enable reconfiguration mechanisms that refocus the available, safe resources to support the most critical services rather than over-provisioning to build failure-proof system.
With the generalisation of networked information systems, accessibility was introduced to give greater importance to users' experience.
To take into account the level of performance, the measurement of performability is defined as "quantifying how well the object system performs in the presence of faults over a specified period of time".[10]
See also
- Safety engineering
- Fault-tolerance
- Fault injection
- List of system quality attributes
- Formal methods
- Dependable Systems and Networks Conference
References
- ↑ IEC, Electropedia del 192 Dependability, http://www.electropedia.org, select 192 Dependability, see 192-01-22 Dependability.
- ↑ R. Kumar, S. A. Khan and R. A. Khan, Revisiting Software Security: Durability Perspective, International Journal of Hybrid Information Technology (SERSC) Vol.8, No.2 pp.311-322, 2015.
- 1 2 A. Avizienis, J.-C. Laprie, Brian Randell, and C. Landwehr, "Basic Concepts and Taxonomy of Dependable and Secure Computing," IEEE Transactions on Dependable and Secure Computing, vol. 1, pp. 11-33, 2004.
- ↑ Brian Randell, "Software Dependability: A Personal View", in the Proc of the 25th International Symposium on Fault-Tolerant Computing (FTCS-25), California, USA, pp 35-41, June 1995.
- ↑ J.C. Laprie. "Dependable Computing and Fault Tolerance: Concepts and terminology," in Proc. 15th IEEE Int. Symp. on Fault-Tolerant Computing, 1985
- ↑ A. Avizienis, J.-C. Laprie and Brian Randell: Fundamental Concepts of Dependability. Research Report No 1145, LAAS-CNRS, April 2001
- ↑ I. Sommerville, Software Engineering: Addison-Wesley, 2004.
- ↑ A. Avizienis, V. Magnus U, J. C. Laprie, and Brian Randell, "Fundamental Concepts of Dependability," presented at ISW-2000, Cambridge, MA, 2000.
- ↑ John C. Knight, Elisabeth A. Strunk, Kevin J. Sullivan: Towards a Rigorous Definition of Information System Survivability
- ↑ John F. Meyer, Willam H. Sanders Specification and construction of performability models
Further reading
Papers
- Wilfredo Torres-Pomales: Software Fault Tolerance: A Tutorial, 2002
- Stefano Porcarelli, Marco Castaldi, Felicita Di Giandomenico, Andrea Bondavalli, Paola Inverardi An Approach to Manage Reconfiguration in Fault-Tolerant Distributed Systems
Journals
- Prognostics Journal is an open access journal that provides an international forum for the electronic publication of original research and industrial experience articles in all areas of systems dependability and prognostics.
- International Journal of Critical Computer-Based Systems
- Latin-American Symposium on Dependeable Computing
Books
- J.C. Laprie, Dependability: Basic Concepts and Terminology Springer-Verlag, 1992. ISBN 0-387-82296-8
Research projects
- DESEREC, DEpendability and Security by Enhanced REConfigurability, FP6/IST integrated project 2006–2008
- NODES, Network on DEpendable Systems
- ESFORS, European security Forum for Web Services, Software, and Systems, FP6/IST coordination action
- HIDENETS HIghly DEpendable ip-based NETworks and Services, FP6/IST targeted project 2006–2008
- RESIST FP6/IST Network of Excellence 2006–2007
- RODIN Rigorous Open Development Environment for Complex Systems FP6/IST targeted project 2004–2007
- SERENITY System Engineering for Security and Dependability, FP6/IST integrated project 2006–2008
- Willow Survivability Architecture, and STILT, System for Terrorism Intervention and Large-scale Teamwork 2002–2004
- ANIKETOS Dependable and Secure Service Composition, FP7/IST integrated project 2010–2014