Hidden Markov model
| Machine learning and data mining |
|---|
 |
|
Machine learning venues
|
|
A hidden Markov model (HMM) is a statistical Markov model in which the system being modeled is assumed to be a Markov process with unobserved (hidden) states. An HMM can be presented as the simplest dynamic Bayesian network. The mathematics behind the HMM were developed by L. E. Baum and coworkers.[1][2][3][4][5] It is closely related to an earlier work on the optimal nonlinear filtering problem by Ruslan L. Stratonovich,[6] who was the first to describe the forward-backward procedure.
In simpler Markov models (like a Markov chain), the state is directly visible to the observer, and therefore the state transition probabilities are the only parameters. In a hidden Markov model, the state is not directly visible, but the output, dependent on the state, is visible. Each state has a probability distribution over the possible output tokens. Therefore, the sequence of tokens generated by an HMM gives some information about the sequence of states. The adjective 'hidden' refers to the state sequence through which the model passes, not to the parameters of the model; the model is still referred to as a 'hidden' Markov model even if these parameters are known exactly.
Hidden Markov models are especially known for their application in temporal pattern recognition such as speech, handwriting, gesture recognition,[7] part-of-speech tagging, musical score following,[8] partial discharges[9] and bioinformatics.
A hidden Markov model can be considered a generalization of a mixture model where the hidden variables (or latent variables), which control the mixture component to be selected for each observation, are related through a Markov process rather than independent of each other. Recently, hidden Markov models have been generalized to pairwise Markov models and triplet Markov models which allow consideration of more complex data structures [10][11] and the modelling of nonstationary data.[12][13]
Description in terms of urns

X — states
y — possible observations
a — state transition probabilities
b — output probabilities
In its discrete form, a hidden Markov process can be visualized as a generalization of the Urn problem with replacement (where each item from the urn is returned to the original urn before the next step).[14] Consider this example: in a room that is not visible to an observer there is a genie. The room contains urns X1, X2, X3, … each of which contains a known mix of balls, each ball labeled y1, y2, y3, … . The genie chooses an urn in that room and randomly draws a ball from that urn. It then puts the ball onto a conveyor belt, where the observer can observe the sequence of the balls but not the sequence of urns from which they were drawn. The genie has some procedure to choose urns; the choice of the urn for the n-th ball depends only upon a random number and the choice of the urn for the (n − 1)-th ball. The choice of urn does not directly depend on the urns chosen before this single previous urn; therefore, this is called a Markov process. It can be described by the upper part of Figure 1.
The Markov process itself cannot be observed, only the sequence of labeled balls, thus this arrangement is called a "hidden Markov process". This is illustrated by the lower part of the diagram shown in Figure 1, where one can see that balls y1, y2, y3, y4 can be drawn at each state. Even if the observer knows the composition of the urns and has just observed a sequence of three balls, e.g. y1, y2 and y3 on the conveyor belt, the observer still cannot be sure which urn (i.e., at which state) the genie has drawn the third ball from. However, the observer can work out other information, such as the likelihood that the third ball came from each of the urns.
Architecture
The diagram below shows the general architecture of an instantiated HMM. Each oval shape represents a random variable that can adopt any of a number of values. The random variable x(t) is the hidden state at time t (with the model from the above diagram, x(t) ∈ { x1, x2, x3 }). The random variable y(t) is the observation at time t (with y(t) ∈ { y1, y2, y3, y4 }). The arrows in the diagram (often called a trellis diagram) denote conditional dependencies.
From the diagram, it is clear that the conditional probability distribution of the hidden variable x(t) at time t, given the values of the hidden variable x at all times, depends only on the value of the hidden variable x(t − 1); the values at time t − 2 and before have no influence. This is called the Markov property. Similarly, the value of the observed variable y(t) only depends on the value of the hidden variable x(t) (both at time t).
In the standard type of hidden Markov model considered here, the state space of the hidden variables is discrete, while the observations themselves can either be discrete (typically generated from a categorical distribution) or continuous (typically from a Gaussian distribution). The parameters of a hidden Markov model are of two types, transition probabilities and emission probabilities (also known as output probabilities). The transition probabilities control the way the hidden state at time t is chosen given the hidden state at time .

The hidden state space is assumed to consist of one of N possible values, modeled as a categorical distribution. (See the section below on extensions for other possibilities.) This means that for each of the N possible states that a hidden variable at time t can be in, there is a transition probability from this state to each of the N possible states of the hidden variable at time , for a total of transition probabilities. Note that the set of transition probabilities for transitions from any given state must sum to 1. Thus, the matrix of transition probabilities is a Markov matrix. Because any one transition probability can be determined once the others are known, there are a total of transition parameters.




In addition, for each of the N possible states, there is a set of emission probabilities governing the distribution of the observed variable at a particular time given the state of the hidden variable at that time. The size of this set depends on the nature of the observed variable. For example, if the observed variable is discrete with M possible values, governed by a categorical distribution, there will be separate parameters, for a total of emission parameters over all hidden states. On the other hand, if the observed variable is an M-dimensional vector distributed according to an arbitrary multivariate Gaussian distribution, there will be M parameters controlling the means and parameters controlling the covariance matrix, for a total of emission parameters. (In such a case, unless the value of M is small, it may be more practical to restrict the nature of the covariances between individual elements of the observation vector, e.g. by assuming that the elements are independent of each other, or less restrictively, are independent of all but a fixed number of adjacent elements.)





Inference

5 3 2 5 3 2
4 3 2 5 3 2
3 1 2 5 3 2
We can find the most likely sequence by evaluating the joint probability of both the state sequence and the observations for each case (simply by multiplying the probability values, which here correspond to the opacities of the arrows involved). In general, this type of problem (i.e. finding the most likely explanation for an observation sequence) can be solved efficiently using the Viterbi algorithm.
Several inference problems are associated with hidden Markov models, as outlined below.
Probability of an observed sequence
The task is to compute in a best way, given the parameters of the model, the probability of a particular output sequence. This requires summation over all possible state sequences:
The probability of observing a sequence

of length L is given by

where the sum runs over all possible hidden-node sequences

Applying the principle of dynamic programming, this problem, too, can be handled efficiently using the forward algorithm.
Probability of the latent variables
A number of related tasks ask about the probability of one or more of the latent variables, given the model's parameters and a sequence of observations

Filtering
The task is to compute, given the model's parameters and a sequence of observations, the distribution over hidden states of the last latent variable at the end of the sequence, i.e. to compute . This task is normally used when the sequence of latent variables is thought of as the underlying states that a process moves through at a sequence of points of time, with corresponding observations at each point in time. Then, it is natural to ask about the state of the process at the end.

This problem can be handled efficiently using the forward algorithm.
Smoothing
This is similar to filtering but asks about the distribution of a latent variable somewhere in the middle of a sequence, i.e. to compute for some . From the perspective described above, this can be thought of as the probability distribution over hidden states for a point in time k in the past, relative to time t.


The forward-backward algorithm is an efficient method for computing the smoothed values for all hidden state variables.
Most likely explanation
The task, unlike the previous two, asks about the joint probability of the entire sequence of hidden states that generated a particular sequence of observations (see illustration on the right). This task is generally applicable when HMM's are applied to different sorts of problems from those for which the tasks of filtering and smoothing are applicable. An example is part-of-speech tagging, where the hidden states represent the underlying parts of speech corresponding to an observed sequence of words. In this case, what is of interest is the entire sequence of parts of speech, rather than simply the part of speech for a single word, as filtering or smoothing would compute.
This task requires finding a maximum over all possible state sequences, and can be solved efficiently by the Viterbi algorithm.
Statistical significance
For some of the above problems, it may also be interesting to ask about statistical significance. What is the probability that a sequence drawn from some null distribution will have an HMM probability (in the case of the forward algorithm) or a maximum state sequence probability (in the case of the Viterbi algorithm) at least as large as that of a particular output sequence?[15] When an HMM is used to evaluate the relevance of a hypothesis for a particular output sequence, the statistical significance indicates the false positive rate associated with failing to reject the hypothesis for the output sequence.
A concrete example
Consider two friends, Alice and Bob, who live far apart from each other and who talk together daily over the telephone about what they did that day. Bob is only interested in three activities: walking in the park, shopping, and cleaning his apartment. The choice of what to do is determined exclusively by the weather on a given day. Alice has no definite information about the weather where Bob lives, but she knows general trends. Based on what Bob tells her he did each day, Alice tries to guess what the weather must have been like.
Alice believes that the weather operates as a discrete Markov chain. There are two states, "Rainy" and "Sunny", but she cannot observe them directly, that is, they are hidden from her. On each day, there is a certain chance that Bob will perform one of the following activities, depending on the weather: "walk", "shop", or "clean". Since Bob tells Alice about his activities, those are the observations. The entire system is that of a hidden Markov model (HMM).
Alice knows the general weather trends in the area, and what Bob likes to do on average. In other words, the parameters of the HMM are known. They can be represented as follows in Python:
states = ('Rainy', 'Sunny')
observations = ('walk', 'shop', 'clean')
start_probability = {'Rainy': 0.6, 'Sunny': 0.4}
transition_probability = {
'Rainy' : {'Rainy': 0.7, 'Sunny': 0.3},
'Sunny' : {'Rainy': 0.4, 'Sunny': 0.6},
}
emission_probability = {
'Rainy' : {'walk': 0.1, 'shop': 0.4, 'clean': 0.5},
'Sunny' : {'walk': 0.6, 'shop': 0.3, 'clean': 0.1},
}
In this piece of code, start_probability represents Alice's belief about which state the HMM is in when Bob first calls her (all she knows is that it tends to be rainy on average). The particular probability distribution used here is not the equilibrium one, which is (given the transition probabilities) approximately {'Rainy': 0.57, 'Sunny': 0.43}. The transition_probability represents the change of the weather in the underlying Markov chain. In this example, there is only a 30% chance that tomorrow will be sunny if today is rainy. The emission_probability represents how likely Bob is to perform a certain activity on each day. If it is rainy, there is a 50% chance that he is cleaning his apartment; if it is sunny, there is a 60% chance that he is outside for a walk.
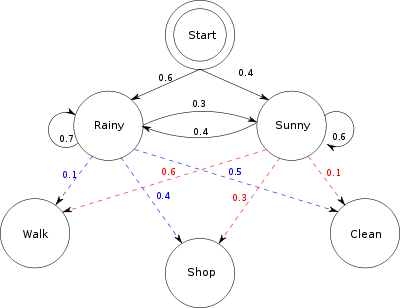
A similar example is further elaborated in the Viterbi algorithm page.
Learning
The parameter learning task in HMMs is to find, given an output sequence or a set of such sequences, the best set of state transition and emission probabilities. The task is usually to derive the maximum likelihood estimate of the parameters of the HMM given the set of output sequences. No tractable algorithm is known for solving this problem exactly, but a local maximum likelihood can be derived efficiently using the Baum–Welch algorithm or the Baldi–Chauvin algorithm. The Baum–Welch algorithm is a special case of the expectation-maximization algorithm.
Mathematical description
General description
A basic hidden Markov model can be described as follows:
| number of states | ||||||
| number of observations | ||||||
| emission parameter for an observation associated with state | ||||||
| probability of transition from state to state | ||||||
| -dimensional vector, composed of ; must sum to , the row of the matrix | ||||||
| (hidden) state at time | ||||||
| observation at time | ||||||
| probability distribution of an observation, parametrized on | ||||||



















Note that, in the above model (and also the one below), the prior distribution of the initial state is not specified. Typical learning models correspond to assuming a discrete uniform distribution over possible states (i.e. no particular prior distribution is assumed).

In a Bayesian setting, all parameters are associated with random variables, as follows:
| as above | ||||||
| as above | ||||||
| as above | ||||||
| shared hyperparameter for emission parameters | ||||||
| shared hyperparameter for transition parameters | ||||||
| prior probability distribution of emission parameters, parametrized on | ||||||








These characterizations use and to describe arbitrary distributions over observations and parameters, respectively. Typically will be the conjugate prior of . The two most common choices of are Gaussian and categorical; see below.


Compared with a simple mixture model
As mentioned above, the distribution of each observation in a hidden Markov model is a mixture density, with the states of the corresponding to mixture components. It is useful to compare the above characterizations for an HMM with the corresponding characterizations, of a mixture model, using the same notation.
A non-Bayesian mixture model:
| number of mixture components | ||||||
| number of observations | ||||||
| parameter of distribution of observation associated with component | ||||||
| mixture weight, i.e. prior probability of component | ||||||
| -dimensional vector, composed of ; must sum to | ||||||
| component of observation | ||||||
| observation | ||||||
| probability distribution of an observation, parametrized on | ||||||




A Bayesian mixture model:
| as above | ||||||
| as above | ||||||
| as above | ||||||
| shared hyperparameter for component parameters | ||||||
| shared hyperparameter for mixture weights | ||||||
| prior probability distribution of component parameters, parametrized on | ||||||

Examples
The following mathematical descriptions are fully written out and explained, for ease of implementation.
A typical non-Bayesian HMM with Gaussian observations looks like this:
| number of states | ||||||
| number of observations | ||||||
| probability of transition from state to state | ||||||
| -dimensional vector, composed of ; must sum to | ||||||
| mean of observations associated with state | ||||||
| variance of observations associated with state | ||||||
| state of observation at time | ||||||
| observation at time | ||||||



A typical Bayesian HMM with Gaussian observations looks like this:
| number of states | ||||||
| number of observations | ||||||
| probability of transition from state to state | ||||||
| -dimensional vector, composed of ; must sum to | ||||||
| mean of observations associated with state | ||||||
| variance of observations associated with state | ||||||
| state of observation at time | ||||||
| observation at time | ||||||
| concentration hyperparameter controlling the density of the transition matrix | ||||||
| shared hyperparameters of the means for each state | ||||||
| shared hyperparameters of the variances for each state | ||||||




A typical non-Bayesian HMM with categorical observations looks like this:
| number of states | ||||||
| number of observations | ||||||
| probability of transition from state to state | ||||||
| -dimensional vector, composed of ; must sum to | ||||||
| dimension of categorical observations, e.g. size of word vocabulary | ||||||
| probability for state of observing the th item | ||||||
| -dimensional vector, composed of ; must sum to | ||||||
| state of observation at time | ||||||
| observation at time | ||||||





A typical Bayesian HMM with categorical observations looks like this:
| number of states | ||||||
| number of observations | ||||||
| probability of transition from state to state | ||||||
| -dimensional vector, composed of ; must sum to | ||||||
| dimension of categorical observations, e.g. size of word vocabulary | ||||||
| probability for state of observing the th item | ||||||
| -dimensional vector, composed of ; must sum to | ||||||
| state of observation at time | ||||||
| observation at time | ||||||
| shared concentration hyperparameter of for each state | ||||||
| concentration hyperparameter controlling the density of the transition matrix | ||||||




Note that in the above Bayesian characterizations, (a concentration parameter) controls the density of the transition matrix. That is, with a high value of (significantly above 1), the probabilities controlling the transition out of a particular state will all be similar, meaning there will be a significant probability of transitioning to any of the other states. In other words, the path followed by the Markov chain of hidden states will be highly random. With a low value of (significantly below 1), only a small number of the possible transitions out of a given state will have significant probability, meaning that the path followed by the hidden states will be somewhat predictable.
A two-level Bayesian HMM
An alternative for the above two Bayesian examples would be to add another level of prior parameters for the transition matrix. That is, replace the lines
| concentration hyperparameter controlling the density of the transition matrix | ||||||
with the following:
| concentration hyperparameter controlling how many states are intrinsically likely | ||||||
| concentration hyperparameter controlling the density of the transition matrix | ||||||
| -dimensional vector of probabilities, specifying the intrinsic probability of a given state | ||||||




What this means is the following:
- is a probability distribution over states, specifying which states are inherently likely. The greater the probability of a given state in this vector, the more likely is a transition to that state (regardless of the starting state).
- controls the density of . Values significantly above 1 cause a dense vector where all states will have similar prior probabilities. Values significantly below 1 cause a sparse vector where only a few states are inherently likely (have prior probabilities significantly above 0).
- controls the density of the transition matrix, or more specifically, the density of the N different probability vectors specifying the probability of transitions out of state i to any other state.
Imagine that the value of is significantly above 1. Then the different vectors will be dense, i.e. the probability mass will be spread out fairly evenly over all states. However, to the extent that this mass is unevenly spread, controls which states are likely to get more mass than others.
Now, imagine instead that is significantly below 1. This will make the vectors sparse, i.e. almost all the probability mass is distributed over a small number of states, and for the rest, a transition to that state will be very unlikely. Notice that there are different vectors for each starting state, and so even if all the vectors are sparse, different vectors may distribute the mass to different ending states. However, for all of the vectors, controls which ending states are likely to get mass assigned to them. For example, if is 0.1, then each will be sparse and, for any given starting state i, the set of states to which transitions are likely to occur will be very small, typically having only one or two members. Now, if the probabilities in are all the same (or equivalently, one of the above models without is used), then for different i, there will be different states in the corresponding , so that all states are equally likely to occur in any given . On the other hand, if the values in are unbalanced, so that one state has a much higher probability than others, almost all will contain this state; hence, regardless of the starting state, transitions will nearly always occur to this given state.

Hence, a two-level model such as just described allows independent control over (1) the overall density of the transition matrix, and (2) the density of states to which transitions are likely (i.e. the density of the prior distribution of states in any particular hidden variable ). In both cases this is done while still assuming ignorance over which particular states are more likely than others. If it is desired to inject this information into the model, the probability vector can be directly specified; or, if there is less certainty about these relative probabilities, a non-symmetric Dirichlet distribution can be used as the prior distribution over . That is, instead of using a symmetric Dirichlet distribution with the single parameter (or equivalently, a general Dirichlet with a vector all of whose values are equal to ), use a general Dirichlet with values that are variously greater or less than , according to which state is more or less preferred.

Poisson hidden Markov model
Poisson hidden Markov models (PHMM) are special cases of hidden Markov models where a Poisson process has a rate which varies in association with changes between the different states of a Markov model.[16] PHMMs are not necessarily Markovian processes themselves because the underlying Markov chain or Markov process cannot be observed and only the Poisson signal is observed.
Applications
HMMs can be applied in many fields where the goal is to recover a data sequence that is not immediately observable (but other data that depend on the sequence are). Applications include:
- Single Molecule Kinetic analysis[17]
- Cryptanalysis
- Speech recognition
- Speech synthesis
- Part-of-speech tagging
- Document Separation in scanning solutions
- Machine translation
- Partial discharge
- Gene prediction
- Alignment of bio-sequences
- Time Series Analysis
- Activity recognition
- Protein folding[18]
- Metamorphic Virus Detection[19]
- DNA Motif Discovery[20]
History
The forward and backward recursions used in HMM as well as computations of marginal smoothing probabilities were first described by Ruslan L. Stratonovich in 1960[6] (pages 160—162) and in the late 1950s in his papers in Russian. The Hidden Markov Models were later described in a series of statistical papers by Leonard E. Baum and other authors in the second half of the 1960s. One of the first applications of HMMs was speech recognition, starting in the mid-1970s.[21][22][23][24]
In the second half of the 1980s, HMMs began to be applied to the analysis of biological sequences,[25] in particular DNA. Since then, they have become ubiquitous in the field of bioinformatics.[26]
Types
Hidden Markov models can model complex Markov processes where the states emit the observations according to some probability distribution. One such example is the Gaussian distribution, in such a Hidden Markov Model the states output are represented by a Gaussian distribution.
Moreover, it could represent even more complex behavior when the output of the states is represented as mixture of two or more Gaussians, in which case the probability of generating an observation is the product of the probability of first selecting one of the Gaussians and the probability of generating that observation from that Gaussian.
Extensions
In the hidden Markov models considered above, the state space of the hidden variables is discrete, while the observations themselves can either be discrete (typically generated from a categorical distribution) or continuous (typically from a Gaussian distribution). Hidden Markov models can also be generalized to allow continuous state spaces. Examples of such models are those where the Markov process over hidden variables is a linear dynamical system, with a linear relationship among related variables and where all hidden and observed variables follow a Gaussian distribution. In simple cases, such as the linear dynamical system just mentioned, exact inference is tractable (in this case, using the Kalman filter); however, in general, exact inference in HMMs with continuous latent variables is infeasible, and approximate methods must be used, such as the extended Kalman filter or the particle filter.
Hidden Markov models are generative models, in which the joint distribution of observations and hidden states, or equivalently both the prior distribution of hidden states (the transition probabilities) and conditional distribution of observations given states (the emission probabilities), is modeled. The above algorithms implicitly assume a uniform prior distribution over the transition probabilities. However, it is also possible to create hidden Markov models with other types of prior distributions. An obvious candidate, given the categorical distribution of the transition probabilities, is the Dirichlet distribution, which is the conjugate prior distribution of the categorical distribution. Typically, a symmetric Dirichlet distribution is chosen, reflecting ignorance about which states are inherently more likely than others. The single parameter of this distribution (termed the concentration parameter) controls the relative density or sparseness of the resulting transition matrix. A choice of 1 yields a uniform distribution. Values greater than 1 produce a dense matrix, in which the transition probabilities between pairs of states are likely to be nearly equal. Values less than 1 result in a sparse matrix in which, for each given source state, only a small number of destination states have non-negligible transition probabilities. It is also possible to use a two-level prior Dirichlet distribution, in which one Dirichlet distribution (the upper distribution) governs the parameters of another Dirichlet distribution (the lower distribution), which in turn governs the transition probabilities. The upper distribution governs the overall distribution of states, determining how likely each state is to occur; its concentration parameter determines the density or sparseness of states. Such a two-level prior distribution, where both concentration parameters are set to produce sparse distributions, might be useful for example in unsupervised part-of-speech tagging, where some parts of speech occur much more commonly than others; learning algorithms that assume a uniform prior distribution generally perform poorly on this task. The parameters of models of this sort, with non-uniform prior distributions, can be learned using Gibbs sampling or extended versions of the expectation-maximization algorithm.
An extension of the previously described hidden Markov models with Dirichlet priors uses a Dirichlet process in place of a Dirichlet distribution. This type of model allows for an unknown and potentially infinite number of states. It is common to use a two-level Dirichlet process, similar to the previously described model with two levels of Dirichlet distributions. Such a model is called a hierarchical Dirichlet process hidden Markov model, or HDP-HMM for short. It was originally described under the name "Infinite Hidden Markov Model"<sup class="reference plainlinks nourlexpansion" id="ref_Beal, Matthew J., Zoubin Ghahramani, and Carl Edward Rasmussen. "The infinite hidden Markov model." Advances in neural information processing systems 14 (2002): 577-584."> and was further formalized in<sup class="reference plainlinks nourlexpansion" id="ref_Teh, Yee Whye, et al. "Hierarchical dirichlet processes." Journal of the American Statistical Association 101.476 (2006).">.
A different type of extension uses a discriminative model in place of the generative model of standard HMMs. This type of model directly models the conditional distribution of the hidden states given the observations, rather than modeling the joint distribution. An example of this model is the so-called maximum entropy Markov model (MEMM), which models the conditional distribution of the states using logistic regression (also known as a "maximum entropy model"). The advantage of this type of model is that arbitrary features (i.e. functions) of the observations can be modeled, allowing domain-specific knowledge of the problem at hand to be injected into the model. Models of this sort are not limited to modeling direct dependencies between a hidden state and its associated observation; rather, features of nearby observations, of combinations of the associated observation and nearby observations, or in fact of arbitrary observations at any distance from a given hidden state can be included in the process used to determine the value of a hidden state. Furthermore, there is no need for these features to be statistically independent of each other, as would be the case if such features were used in a generative model. Finally, arbitrary features over pairs of adjacent hidden states can be used rather than simple transition probabilities. The disadvantages of such models are: (1) The types of prior distributions that can be placed on hidden states are severely limited; (2) It is not possible to predict the probability of seeing an arbitrary observation. This second limitation is often not an issue in practice, since many common usages of HMM's do not require such predictive probabilities.
A variant of the previously described discriminative model is the linear-chain conditional random field. This uses an undirected graphical model (aka Markov random field) rather than the directed graphical models of MEMM's and similar models. The advantage of this type of model is that it does not suffer from the so-called label bias problem of MEMM's, and thus may make more accurate predictions. The disadvantage is that training can be slower than for MEMM's.
Yet another variant is the factorial hidden Markov model, which allows for a single observation to be conditioned on the corresponding hidden variables of a set of independent Markov chains, rather than a single Markov chain. It is equivalent to a single HMM, with states (assuming there are states for each chain), and therefore, learning in such a model is difficult: for a sequence of length , a straightforward Viterbi algorithm has complexity . To find an exact solution, a junction tree algorithm could be used, but it results in an complexity. In practice, approximate techniques, such as variational approaches, could be used.[27]




All of the above models can be extended to allow for more distant dependencies among hidden states, e.g. allowing for a given state to be dependent on the previous two or three states rather than a single previous state; i.e. the transition probabilities are extended to encompass sets of three or four adjacent states (or in general adjacent states). The disadvantage of such models is that dynamic-programming algorithms for training them have an running time, for adjacent states and total observations (i.e. a length- Markov chain).

Another recent extension is the triplet Markov model,[28] in which an auxiliary underlying process is added to model some data specificities. Many variants of this model have been proposed. One should also mention the interesting link that has been established between the theory of evidence and the triplet Markov models [10] and which allows to fuse data in Markovian context [11] and to model nonstationary data.[12][13]
See also
- Andrey Markov
- Baum–Welch algorithm
- Bayesian inference
- Bayesian programming
- Conditional random field
- Estimation theory
- HHpred / HHsearch free server and software for protein sequence searching
- HMMER, a free hidden Markov model program for protein sequence analysis
- Hidden Bernoulli model
- Hidden semi-Markov model
- Hierarchical hidden Markov model
- Layered hidden Markov model
- Sequential dynamical system
- Stochastic context-free grammar
- Time Series Analysis
- Variable-order Markov model
- Viterbi algorithm
References
- ↑ Baum, L. E.; Petrie, T. (1966). "Statistical Inference for Probabilistic Functions of Finite State Markov Chains". The Annals of Mathematical Statistics. 37 (6): 1554–1563. doi:10.1214/aoms/1177699147. Retrieved 28 November 2011.
- ↑ Baum, L. E.; Eagon, J. A. (1967). "An inequality with applications to statistical estimation for probabilistic functions of Markov processes and to a model for ecology". Bulletin of the American Mathematical Society. 73 (3): 360. doi:10.1090/S0002-9904-1967-11751-8. Zbl 0157.11101.
- ↑ Baum, L. E.; Sell, G. R. (1968). "Growth transformations for functions on manifolds". Pacific Journal of Mathematics. 27 (2): 211–227. doi:10.2140/pjm.1968.27.211. Retrieved 28 November 2011.
- ↑ Baum, L. E.; Petrie, T.; Soules, G.; Weiss, N. (1970). "A Maximization Technique Occurring in the Statistical Analysis of Probabilistic Functions of Markov Chains". The Annals of Mathematical Statistics. 41: 164. doi:10.1214/aoms/1177697196. JSTOR 2239727. MR MR287613. Zbl 0188.49603.
- ↑ Baum, L.E. (1972). "An Inequality and Associated Maximization Technique in Statistical Estimation of Probabilistic Functions of a Markov Process". Inequalities. 3: 1–8.
- 1 2 Stratonovich, R.L. (1960). "Conditional Markov Processes". Theory of Probability and its Applications. 5 (2): 156–178. doi:10.1137/1105015.
- ↑ Thad Starner, Alex Pentland. Real-Time American Sign Language Visual Recognition From Video Using Hidden Markov Models. Master's Thesis, MIT, Feb 1995, Program in Media Arts
- ↑ B. Pardo and W. Birmingham. Modeling Form for On-line Following of Musical Performances. AAAI-05 Proc., July 2005.
- ↑ Satish L, Gururaj BI (April 2003). "Use of hidden Markov models for partial discharge pattern classification". IEEE Transactions on Dielectrics and Electrical Insulation.
- 1 2 Pr. Pieczynski, W. Pieczynski, Multisensor triplet Markov chains and theory of evidence, International Journal of Approximate Reasoning, Vol. 45, No. 1, pp. 1-16, 2007.
- 1 2 Boudaren et al., M. Y. Boudaren, E. Monfrini, W. Pieczynski, and A. Aissani, Dempster-Shafer fusion of multisensor signals in nonstationary Markovian context, EURASIP Journal on Advances in Signal Processing, No. 134, 2012.
- 1 2 Lanchantin et al., P. Lanchantin and W. Pieczynski, Unsupervised restoration of hidden non stationary Markov chain using evidential priors, IEEE Trans. on Signal Processing, Vol. 53, No. 8, pp. 3091-3098, 2005.
- 1 2 Boudaren et al., M. Y. Boudaren, E. Monfrini, and W. Pieczynski, Unsupervised segmentation of random discrete data hidden with switching noise distributions, IEEE Signal Processing Letters, Vol. 19, No. 10, pp. 619-622, October 2012.
- ↑ Lawrence R. Rabiner (February 1989). "A tutorial on Hidden Markov Models and selected applications in speech recognition" (PDF). Proceedings of the IEEE. 77 (2): 257–286. doi:10.1109/5.18626.
- ↑ Newberg, L. (2009). "Error statistics of hidden Markov model and hidden Boltzmann model results". BMC Bioinformatics. 10: 212. doi:10.1186/1471-2105-10-212. PMC 2722652
 . PMID 19589158.
. PMID 19589158. - ↑ R. Paroli. et al., Poisson hidden Markov models for time series of overdispersed insurance counts
- ↑ NICOLAI, CHRISTOPHER (2013). "SOLVING ION CHANNEL KINETICS WITH THE QuB SOFTWARE". Biophysical Reviews and Letters. 8 (3n04): 191–211. doi:10.1142/S1793048013300053.
- ↑ Stigler, J.; Ziegler, F.; Gieseke, A.; Gebhardt, J. C. M.; Rief, M. (2011). "The Complex Folding Network of Single Calmodulin Molecules". Science. 334 (6055): 512–516. doi:10.1126/science.1207598. PMID 22034433.
- ↑ Wong, W.; Stamp, M. (2006). "Hunting for metamorphic engines". Journal in Computer Virology. 2 (3): 211–229. doi:10.1007/s11416-006-0028-7.
- ↑ Wong, K. -C.; Chan, T. -M.; Peng, C.; Li, Y.; Zhang, Z. (2013). "DNA motif elucidation using belief propagation". Nucleic Acids Research. 41 (16): e153. doi:10.1093/nar/gkt574. PMC 3763557. PMID 23814189.
- ↑ Baker, J. (1975). "The DRAGON system—An overview". IEEE Transactions on Acoustics, Speech, and Signal Processing. 23: 24–29. doi:10.1109/TASSP.1975.1162650.
- ↑ Jelinek, F.; Bahl, L.; Mercer, R. (1975). "Design of a linguistic statistical decoder for the recognition of continuous speech". IEEE Transactions on Information Theory. 21 (3): 250. doi:10.1109/TIT.1975.1055384.
- ↑ Xuedong Huang; M. Jack; Y. Ariki (1990). Hidden Markov Models for Speech Recognition. Edinburgh University Press. ISBN 0-7486-0162-7.
- ↑ Xuedong Huang; Alex Acero; Hsiao-Wuen Hon (2001). Spoken Language Processing. Prentice Hall. ISBN 0-13-022616-5.
- ↑ M. Bishop and E. Thompson (1986). "Maximum Likelihood Alignment of DNA Sequences". Journal of Molecular Biology. 190 (2): 159–165. doi:10.1016/0022-2836(86)90289-5. PMID 3641921.
- ↑ Richard Durbin; Sean R. Eddy; Anders Krogh; Graeme Mitchison (1999). Biological Sequence Analysis: Probabilistic Models of Proteins and Nucleic Acids. Cambridge University Press. ISBN 0-521-62971-3.
- ↑ Ghahramani, Zoubin; Jordan, Michael I. (1997). "Factorial Hidden Markov Models". Machine Learning. 29 (2/3): 245–273. doi:10.1023/A:1007425814087.
- ↑ Triplet Markov Chain, W. Pieczynski,Chaînes de Markov Triplet, Triplet Markov Chains, Comptes Rendus de l’Académie des Sciences – Mathématique, Série I, Vol. 335, No. 3, pp. 275-278, 2002.
External links
![]() Media related to Hidden Markov Model at Wikimedia Commons
Media related to Hidden Markov Model at Wikimedia Commons
Concepts
- Teif V. B. and K. Rippe (2010) Statistical–mechanical lattice models for protein–DNA binding in chromatin. J. Phys.: Condens. Matter, 22, 414105, http://iopscience.iop.org/0953-8984/22/41/414105
- A Revealing Introduction to Hidden Markov Models by Mark Stamp, San Jose State University.
- Fitting HMM's with expectation-maximization – complete derivation
- Switching Autoregressive Hidden Markov Model (SAR HMM)
- A step-by-step tutorial on HMMs (University of Leeds)
- Hidden Markov Models (an exposition using basic mathematics)
- Hidden Markov Models (by Narada Warakagoda)
- Hidden Markov Models: Fundamentals and Applications Part 1, Part 2 (by V. Petrushin)
- Lecture on a Spreadsheet by Jason Eisner, Video and interactive spreadsheet
Software
- Hidden Markov Model (HMM) Toolbox for Matlab (by Kevin Murphy)
- Hidden Markov Model Toolkit (HTK) (a portable toolkit for building and manipulating hidden Markov models)
- Hidden Markov Model R-Package to set up, apply and make inference with discrete time and discrete space Hidden Markov Models
- HMMlib (an optimized library for work with general (discrete) hidden Markov models)
- parredHMMlib (a parallel implementation of the forward algorithm and the Viterbi algorithm. Extremely fast for HMMs with small state spaces)
- zipHMMlib (a library for general (discrete) hidden Markov models, exploiting repetitions in the input sequence to greatly speed up the forward algorithm. Implementation of the posterior decoding algorithm and the Viterbi algorithm are also provided.)
- GHMM Library (home page of the GHMM Library project)
- Jahmm Java Library (general-purpose Java library)
- HMM and other statistical programs (Implementation in C by Tapas Kanungo)
- The hmm package A Haskell library for working with Hidden Markov Models.
- GT2K Georgia Tech Gesture Toolkit (referred to as GT2K)
- Hidden Markov Models -online calculator for HMM – Viterbi path and probabilities. Examples with perl source code.
- A discrete Hidden Markov Model class, based on OpenCV.
- depmixS4 R-Package (Hidden Markov Models of GLMs and Other Distributions in S4 )
- MLPACK contains a C++ implementation of HMMs
- Hidden Markov Models Java Library contains basic HMMs abstractions in Java 8
- SFIHMM high-speed C code for the estimation of Hidden Markov Models, Viterbi Path Reconstruction, and the generation of simulated data from HMMs.