Audio time-scale/pitch modification
Time stretching is the process of changing the speed or duration of an audio signal without affecting its pitch. Pitch scaling or pitch shifting is the opposite: the process of changing the pitch without affecting the speed. Similar methods can change speed, pitch, or both at once, in a time-varying way.
These processes are used, for instance, to match the pitches and tempos of two pre-recorded clips for mixing when the clips cannot be reperformed or resampled. (A drum track containing no pitched instruments could be moderately resampled for tempo without adverse effects, but a pitched track could not). They are also used to create effects such as increasing the range of an instrument (like pitch shifting a guitar down an octave).
Resampling
The simplest way to change the duration or pitch of a digital audio clip is to resample it. This is a mathematical operation that effectively rebuilds a continuous waveform from its samples and then samples that waveform again at a different rate. When the new samples are played at the original sampling frequency, the audio clip sounds faster or slower. Unfortunately, the frequencies in the sample are always scaled at the same rate as the speed, transposing its perceived pitch up or down in the process. In other words, slowing down the recording lowers the pitch, speeding it up raises the pitch, and using this method the two effects cannot be separated. This is analogous to speeding up or slowing down an analogue recording, like a phonograph record or tape, creating the Chipmunk effect.
Fundamental Principle of Time-Scale Modification (TSM)
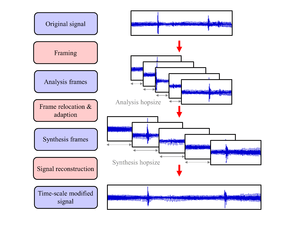
In order to preserve an audio signal's pitch when stretching or compressing its duration, many TSM procedures follow a common fundamental strategy.[1] Given an original discrete-time audio signal, this strategy's first step is to split the signal into short analysis frames of fixed length. The analysis frames are spaced by a fixed number of samples, called the analysis hopsize . To achieve the actual time-scale modification, the analysis frames are then temporally relocated to have a synthesis hopsize . This frame relocation results in a modification of the signal's duration by a stretching factor of . However, simply superimposing the unmodified analysis frames typically results in undesired artifacts such as phase discontinuities or amplitude fluctuations. To prevent this kind of artifacts, the analysis frames are adapted to form synthesis frames, prior to the reconstruction of the time-scale modified output signal.



The strategy of how to derive the synthesis frames from the analysis frames is a key difference among different TSM procedures.
Frequency domain
Phase vocoder
One way of stretching the length of a signal without affecting the pitch is to build a phase vocoder after Flanagan, Golden, and Portnoff.
Basic steps:
- compute the instantaneous frequency/amplitude relationship of the signal using the STFT, which is the discrete Fourier transform of a short, overlapping and smoothly windowed block of samples;
- apply some processing to the Fourier transform magnitudes and phases (like resampling the FFT blocks); and
- perform an inverse STFT by taking the inverse Fourier transform on each chunk and adding the resulting waveform chunks, also called overlap and add (OLA).[2]
The phase vocoder handles sinusoid components well, but early implementations introduced considerable smearing on transient ("beat") waveforms at all non-integer compression/expansion rates, which renders the results phasey and diffuse. Recent improvements allow better quality results at all compression/expansion ratios but a residual smearing effect still remains.
The phase vocoder technique can also be used to perform pitch shifting, chorusing, timbre manipulation, harmonizing, and other unusual modifications, all of which can be changed as a function of time.
Sinusoidal spectral modeling
.svg.png)
Another method for time stretching relies on a spectral model of the signal. In this method, peaks are identified in frames using the STFT of the signal, and sinusoidal "tracks" are created by connecting peaks in adjacent frames. The tracks are then re-synthesized at a new time scale. This method can yield good results on both polyphonic and percussive material, especially when the signal is separated into sub-bands. However, this method is more computationally demanding than other methods.
Time domain
SOLA
Rabiner and Schafer in 1978 put forth an alternate solution that works in the time domain: attempt to find the period (or equivalently the fundamental frequency) of a given section of the wave using some pitch detection algorithm (commonly the peak of the signal's autocorrelation, or sometimes cepstral processing), and crossfade one period into another.
This is called time-domain harmonic scaling[4] or the synchronized overlap-add method (SOLA) and performs somewhat faster than the phase vocoder on slower machines but fails when the autocorrelation mis-estimates the period of a signal with complicated harmonics (such as orchestral pieces).
Adobe Audition (formerly Cool Edit Pro) seems to solve this by looking for the period closest to a center period that the user specifies, which should be an integer multiple of the tempo, and between 30 Hz and the lowest bass frequency.
This is much more limited in scope than the phase vocoder based processing, but can be made much less processor intensive, for real-time applications. It provides the most coherent results for single-pitched sounds like voice or musically monophonic instrument recordings.
High-end commercial audio processing packages either combine the two techniques (for example by separating the signal into sinusoid and transient waveforms), or use other techniques based on the wavelet transform, or artificial neural network processing, producing the highest-quality time stretching.

Speed hearing and speed talking
For the specific case of speech, time stretching can be performed using PSOLA.
While one might expect speeding up to reduce comprehension, Herb Friedman says that "Experiments have shown that the brain works most efficiently if the information rate through the ears--via speech--is the "average" reading rate, which is about 200-300 wpm (words per minute), yet the average rate of speech is in the neighborhood of 100-150 wpm."
Speeding up audio is seen as the equivalent of "speed reading" .
Time stretching is often used to adjust Radio commercials and the audio of Television advertisements to fit exactly into the 30 or 60 seconds available.
Pitch scaling


These techniques can also be used to transpose an audio sample while holding speed or duration constant. This may be accomplished by time stretching and then resampling back to the original length. Alternatively, the frequency of the sinusoids in a sinusoidal model may be altered directly, and the signal reconstructed at the appropriate time scale.
Transposing can be called frequency scaling or pitch shifting, depending on perspective.
For example, one could move the pitch of every note up by a perfect fifth, keeping the tempo the same. One can view this transposition as "pitch shifting", "shifting" each note up 7 keys on a piano keyboard, or adding a fixed amount on the Mel scale, or adding a fixed amount in linear pitch space. One can view the same transposition as "frequency scaling", "scaling" (multiplying) the frequency of every note by 3/2.
Musical transposition preserves the ratios of the harmonic frequencies that determine the sound's timbre, unlike the frequency shift performed by amplitude modulation, which adds a fixed frequency offset to the frequency of every note. (In theory one could perform a literal pitch scaling in which the musical pitch space location is scaled [a higher note would be shifted at a greater interval in linear pitch space than a lower note], but that is highly unusual, and not musical).
Time domain processing works much better here, as smearing is less noticeable, but scaling vocal samples distorts the formants into a sort of Alvin and the Chipmunks-like effect, which may be desirable or undesirable. A process that preserves the formants and character of a voice involves analyzing the signal with a channel vocoder or LPC vocoder plus any of several pitch detection algorithms and then resynthesizing it at a different fundamental frequency.
A detailed description of older analog recording techniques for pitch shifting can be found within the Alvin and the Chipmunks entry.
See also
- others
- Dynamic tonality — the real-time changes of tuning and timbre for new chord progressions, musical temperament modulations, etc.
References
- ↑ Jonathan Driedger and Meinard Müller (2016). "A Review of Time-Scale Modification of Music Signals". Applied Sciences. 6 (2): 57.
- ↑ Jont B. Allen (June 1977). "Short Time Spectral Analysis, Synthesis, and Modification by Discrete Fourier Transform". IEEE Transactions on Acoustics, Speech, and Signal Processing. ASSP-25 (3): 235–238.
- ↑ McAulay, R. J.; Quatieri, T. F. (1988), "Speech Processing Based on a Sinusoidal Model" (PDF), The Lincoln Laboratory Journal, 1 (2): 153–167
- ↑ David Malah (April 1979). "Time-domain algorithms for harmonic bandwidth reduction and time scaling of speech signals". IEEE Transactions on Acoustics, Speech, and Signal Processing. ASSP-27 (2): 121–133.
External links
- Time Stretching and Pitch Shifting Overview A comprehensive overview of current time and pitch modification techniques by Stephan Bernsee
- Stephan Bernsee's smbPitchShift C source code C source code for doing frequency domain pitch manipulation
- pitchshift.js from KievII A Javascript pitchshifter based on smbPitchShift code, from the open source KievII library
- The Phase Vocoder: A Tutorial - A good description of the phase vocoder
- New Phase-Vocoder Techniques for Pitch-Shifting, Harmonizing and Other Exotic Effects
- A new Approach to Transient Processing in the Phase Vocoder
- PICOLA and TDHS
- How to build a pitch shifter Theory, equations, figures and performances of a real-time guitar pitch shifter running on a DSP chip
- ZTX Time Stretching Library Free and commercial versions of a popular 3rd party time stretching library for iOS, Linux, Windows and Mac OS X
- Elastique by zplane commercial cross-platform library, mainly used by DJ and DAW manufacturers
- Voice Synth from Qneo - specialized synthesizer for creative voice sculpting
- TSM toolbox Free MATLAB implementations of various Time-Scale Modification procedures
| Techniques |  | |||||||
|---|---|---|---|---|---|---|---|---|
| Formulas | ||||||||
| Luminaries | ||||||||
| Roles and professions | ||||||||
| Other | ||||||||