UTF-8
UTF-8 is a character encoding capable of encoding all possible characters, or code points, defined by Unicode and originally designed by Ken Thompson and Rob Pike.[1]
The encoding is variable-length and uses 8-bit code units. It was designed for backward compatibility with ASCII and to avoid the complications of endianness and byte order marks in the alternative UTF-16 and UTF-32 encodings. The name is derived from Unicode (or Universal Coded Character Set) Transformation Format – 8-bit.[2]
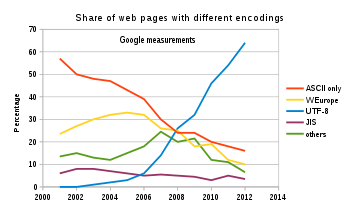
UTF-8 is the dominant character encoding for the World Wide Web, accounting for 87.9% of all Web pages in November 2016 (the most popular East Asian encodings, Shift JIS and GB 2312, have 1.1% and 0.8% respectively).[3][4][5] The Internet Mail Consortium (IMC) recommends that all e-mail programs be able to display and create mail using UTF-8,[6] and the W3C recommends UTF-8 as the default encoding in XML and HTML.[7]
UTF-8 encodes each of the 1,112,064 valid code points in the Unicode code space (1,114,112 code points minus 2,048 surrogate code points) using one to four 8-bit bytes (a group of 8 bits is known as an octet in the Unicode Standard). Code points with lower numerical values (i.e., earlier code positions in the Unicode character set, which tend to occur more frequently) are encoded using fewer bytes. The first 128 characters of Unicode, which correspond one-to-one with ASCII, are encoded using a single octet with the same binary value as ASCII, so that valid ASCII text is valid UTF-8-encoded Unicode as well. Since ASCII bytes do not occur when encoding non-ASCII code points into UTF-8, UTF-8 is safe to use within most programming and document languages that interpret certain ASCII characters in a special way, such as end of string.
History
By early 1992, the search was on for a good byte stream encoding of multi-byte character sets. The draft ISO 10646 standard contained a non-required annex called UTF-1 that provided a byte stream encoding of its 32-bit code points. This encoding was not satisfactory on performance grounds, among other problems, and the biggest problem was probably that it did not have a clear separation between ASCII and non-ASCII: new UTF-1 tools would be backward compatible with ASCII-encoded text, but UTF-1-encoded text could confuse existing code expecting ASCII (or extended ASCII), because it could contain continuation bytes in the range 0x21–0x7E that meant something else in ASCII, e.g., 0x2F for '/', the Unix path directory separator, and this example is reflected in the name and introductory text of its replacement. The table below was derived from a textual description in the annex.
| Number of bytes | First code point | Last code point | Byte 1 | Byte 2 | Byte 3 | Byte 4 | Byte 5 |
|---|---|---|---|---|---|---|---|
| 1 | U+0000 | U+009F | 00–9F | ||||
| 2 | U+00A0 | U+00FF | A0 | A0–FF | |||
| 2 | U+0100 | U+4015 | A1–F5 | 21–7E, A0–FF | |||
| 3 | U+4016 | U+38E2D | F6–FB | 21–7E, A0–FF | 21–7E, A0–FF | ||
| 5 | U+38E2E | U+7FFFFFFF | FC–FF | 21–7E, A0–FF | 21–7E, A0–FF | 21–7E, A0–FF | 21–7E, A0–FF |
In July 1992, the X/Open committee XoJIG was looking for a better encoding. Dave Prosser of Unix System Laboratories submitted a proposal for one that had faster implementation characteristics and introduced the improvement that 7-bit ASCII characters would only represent themselves; all multibyte sequences would include only bytes where the high bit was set. The name File System Safe UCS Transformation Format (FSS-UTF) and most of the text of this proposal were later preserved in the final specification.[8][9][10][11]
| Number of bytes | Bits for code point | First code point | Last code point | Byte 1 | Byte 2 | Byte 3 | Byte 4 | Byte 5 |
|---|---|---|---|---|---|---|---|---|
| 1 | 7 | U+0000 | U+007F | 0xxxxxxx | ||||
| 2 | 13 | U+0080 | U+207F | 10xxxxxx | 1xxxxxxx | |||
| 3 | 19 | U+2080 | U+8207F | 110xxxxx | 1xxxxxxx | 1xxxxxxx | ||
| 4 | 25 | U+82080 | U+208207F | 1110xxxx | 1xxxxxxx | 1xxxxxxx | 1xxxxxxx | |
| 5 | 31 | U+2082080 | U+7FFFFFFF | 11110xxx | 1xxxxxxx | 1xxxxxxx | 1xxxxxxx | 1xxxxxxx |
In August 1992, this proposal was circulated by an IBM X/Open representative to interested parties. A modification by Ken Thompson of the Plan 9 operating system group at Bell Labs made it somewhat less bit-efficient than the previous proposal but crucially allowed it to be self-synchronizing, letting a reader start anywhere and immediately detect byte sequence boundaries. It also abandoned the use of biases and instead added the rule that only the shortest possible encoding is allowed; the additional loss in compactness is relatively insignificant, but readers now have to look out for invalid encodings to avoid reliability and especially security issues. Thompson's design was outlined on September 2, 1992, on a placemat in a New Jersey diner with Rob Pike. In the following days, Pike and Thompson implemented it and updated Plan 9 to use it throughout, and then communicated their success back to X/Open, which accepted it as the specification for FSS-UTF.[10]
| Number of bytes | Bits for code point | First code point | Last code point | Byte 1 | Byte 2 | Byte 3 | Byte 4 | Byte 5 | Byte 6 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 7 | U+0000 | U+007F | 0xxxxxxx | |||||
| 2 | 11 | U+0080 | U+07FF | 110xxxxx | 10xxxxxx | ||||
| 3 | 16 | U+0800 | U+FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |||
| 4 | 21 | U+10000 | U+1FFFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | ||
| 5 | 26 | U+200000 | U+3FFFFFF | 111110xx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | |
| 6 | 31 | U+4000000 | U+7FFFFFFF | 1111110x | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
UTF-8 was first officially presented at the USENIX conference in San Diego, from January 25 to 29, 1993.
In November 2003, UTF-8 was restricted by RFC 3629 to match the constraints of the UTF-16 character encoding: explicitly prohibiting code points corresponding to the high and low surrogate characters removed more than 3% of the three-byte sequences, and ending at U+10FFFF removed more than 48% of the four-byte sequences and all five- and six-byte sequences.
Google reported that in 2008, UTF-8 (labelled "Unicode") became the most common encoding for HTML files.[12]
Description
This table shows UTF-8 as it is since 2003 (the x characters are replaced by the bits of the code point):
| Number of bytes | Bits for code point | First code point | Last code point | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
|---|---|---|---|---|---|---|---|
| 1 | 7 | U+0000 | U+007F | 0xxxxxxx | |||
| 2 | 11 | U+0080 | U+07FF | 110xxxxx | 10xxxxxx | ||
| 3 | 16 | U+0800 | U+FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |
| 4 | 21 | U+10000 | U+10FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
The salient features of this scheme are as follows:
- Backward compatibility: One-byte codes are used only for the ASCII values 0 through 127. In this case the UTF-8 code has the same value as the ASCII code. The high-order bit of these codes is always 0. This means that ASCII text is valid UTF-8, and UTF-8 can be used for parsers expecting 8-bit extended ASCII even if they are not designed for UTF-8.
- Clear distinction between multi-byte and single-byte characters: Code points larger than 127 are represented by multi-byte sequences, composed of a leading byte and one or more continuation bytes. The leading byte has two or more high-order 1s followed by a 0, while continuation bytes all have '10' in the high-order position. Thus, no bytes representing ASCII characters appear in multi-byte sequences.
- Clear indication of byte sequence length: Like in UTF-1, the first byte indicates the number of bytes in the sequence. Unlike in UTF-1, for multi-byte sequences it is simply the number of high-order 1s in the leading byte.
- Prefix property: From the sequence length indication in the first byte (for both UTF-1 and UTF-8), a reader also knows where a sequence ends, which implies that no valid sequence is a prefix of any other. This means that a reader reading from a stream can instantaneously decode each individual fully received sequence, without first having to wait for either the first byte of a next sequence or an end-of-stream indication.
- Self-synchronization: Unlike in UTF-1, the high-order bits of every byte determine the type of byte: single bytes (
0xxxxxxx), leading bytes (11...xxx), and continuation bytes (10xxxxxx) do not share values. The start of a character can be found by backing up at most 3 bytes (5 bytes before RFC 3629 restriction, see above). Together with the prefix property, this makes the scheme self-synchronizing. - Code structure: The remaining bits of the encoding are used for the bits of the code point being encoded, padded with high-order 0s if necessary. The high-order bits go in the leading byte, lower-order bits in subsequent continuation bytes. The number of bytes in the encoding must be the minimum required to hold all the significant bits of the code point.
The first 128 characters (US-ASCII) need one byte. The next 1,920 characters need two bytes to encode. This covers the remainder of almost all Latin alphabets, and also Greek, Cyrillic, Coptic, Armenian, Hebrew, Arabic, Syriac, Thaana and N'Ko alphabets, as well as Combining Diacritical Marks. Three bytes are needed for characters in the rest of the Basic Multilingual Plane, which contains virtually all characters in common use[13] including most Chinese, Japanese and Korean characters. Four bytes are needed for characters in the other planes of Unicode, which include less common CJK characters, various historic scripts, mathematical symbols, and emoji (pictographic symbols).
Examples
Consider the encoding of the Euro sign, €.
- The Unicode code point for "€" is U+20AC.
- According to the scheme table above, this will take three bytes to encode, since it is between U+0800 and U+FFFF.
- Hexadecimal
20ACis binary0010 0000 1010 1100. The two leading zeros are added because, as the scheme table shows, a three-byte encoding needs exactly sixteen bits from the code point. - Because the encoding will be three bytes long, its leading byte starts with three 1s, then a 0 (
1110...) - The first four bits of the code point are stored in the remaining low order four bits of this byte (
1110 0010), leaving 12 bits of the code point yet to be encoded (...0000 1010 1100). - All continuation bytes contain exactly six bits from the code point. So the next six bits of the code point are stored in the low order six bits of the next byte, and
10is stored in the high order two bits to mark it as a continuation byte (so1000 0010). - Finally the last six bits of the code point are stored in the low order six bits of the final byte, and again
10is stored in the high order two bits (1010 1100).
The three bytes 1110 0010 1000 0010 1010 1100 can be more concisely written in hexadecimal, as E2 82 AC.
Since UTF-8 uses groups of six bits, it is sometimes useful to use octal notation which uses 3-bit groups. With a calculator which can convert between hexadecimal and octal it can be easier to manually create or interpret UTF-8 compared to using binary.
- Octal 0200–3777 (hex 80-7FF) shall be coded with two bytes. xxyy will be 3xx 2yy.
- Octal 4000–177777 (hex 800-FFFF) shall be coded with three bytes. xxyyzz will be (340+xx) 2yy 2zz.
- Octal 200000-4177777 (hex 10000-10FFFF) shall be coded with four bytes. wxxyyzz will be 36w 2xx 2yy 2zz.
The following table summarises this conversion, as well as others with different lengths in UTF-8. The colors indicate how bits from the code point are distributed among the UTF-8 bytes. Additional bits added by the UTF-8 encoding process are shown in black.
| Character | Octal code point | Binary code point | Binary UTF-8 | Octal UTF-8 | Hexadecimal UTF-8 | |
|---|---|---|---|---|---|---|
| $ | U+0024 |
044 |
010 0100 |
00100100 |
044 |
24 |
| ¢ | U+00A2 |
0242 |
000 1010 0010 |
11000010 10100010 |
302 242 |
C2 A2 |
| € | U+20AC |
020254 |
0010 0000 1010 1100 |
11100010 10000010 10101100 |
342 202 254 |
E2 82 AC |
| 𐍈 | U+10348 |
0201510 |
0 0001 0000 0011 0100 1000 |
11110000 10010000 10001101 10001000 |
360 220 215 210 |
F0 90 8D 88 |
Codepage layout
The following table summarizes usage of UTF-8 code units (individual bytes or octets) in a code page format. The upper half (0_ to 7_) is for bytes only used in single-byte codes, so it looks like a normal code page; the lower half is for continuation bytes (8_ to B_) and (possible) leading bytes (C_ to F_), and is explained further in the legend below.
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _A | _B | _C | _D | _E | _F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0_ | NUL 0000 0 |
SOH 0001 1 |
STX 0002 2 |
ETX 0003 3 |
EOT 0004 4 |
ENQ 0005 5 |
ACK 0006 6 |
BEL 0007 7 |
BS 0008 8 |
HT 0009 9 |
LF 000A 10 |
VT 000B 11 |
FF 000C 12 |
CR 000D 13 |
SO 000E 14 |
SI 000F 15 |
| 1_ | DLE 0010 16 |
DC1 0011 17 |
DC2 0012 18 |
DC3 0013 19 |
DC4 0014 20 |
NAK 0015 21 |
SYN 0016 22 |
ETB 0017 23 |
CAN 0018 24 |
EM 0019 25 |
SUB 001A 26 |
ESC 001B 27 |
FS 001C 28 |
GS 001D 29 |
RS 001E 30 |
US 001F 31 |
| 2_ | SP 0020 32 |
! 0021 33 |
" 0022 34 |
# 0023 35 |
$ 0024 36 |
% 0025 37 |
& 0026 38 |
' 0027 39 |
( 0028 40 |
) 0029 41 |
* 002A 42 |
+ 002B 43 |
, 002C 44 |
- 002D 45 |
. 002E 46 |
/ 002F 47 |
| 3_ | 0 0030 48 |
1 0031 49 |
2 0032 50 |
3 0033 51 |
4 0034 52 |
5 0035 53 |
6 0036 54 |
7 0037 55 |
8 0038 56 |
9 0039 57 |
: 003A 58 |
; 003B 59 |
< 003C 60 |
= 003D 61 |
> 003E 62 |
? 003F 63 |
| 4_ | @ 0040 64 |
A 0041 65 |
B 0042 66 |
C 0043 67 |
D 0044 68 |
E 0045 69 |
F 0046 70 |
G 0047 71 |
H 0048 72 |
I 0049 73 |
J 004A 74 |
K 004B 75 |
L 004C 76 |
M 004D 77 |
N 004E 78 |
O 004F 79 |
| 5_ | P 0050 80 |
Q 0051 81 |
R 0052 82 |
S 0053 83 |
T 0054 84 |
U 0055 85 |
V 0056 86 |
W 0057 87 |
X 0058 88 |
Y 0059 89 |
Z 005A 90 |
[ 005B 91 |
\ 005C 92 |
] 005D 93 |
^ 005E 94 |
_ 005F 95 |
| 6_ | ` 0060 96 |
a 0061 97 |
b 0062 98 |
c 0063 99 |
d 0064 100 |
e 0065 101 |
f 0066 102 |
g 0067 103 |
h 0068 104 |
i 0069 105 |
j 006A 106 |
k 006B 107 |
l 006C 108 |
m 006D 109 |
n 006E 110 |
o 006F 111 |
| 7_ | p 0070 112 |
q 0071 113 |
r 0072 114 |
s 0073 115 |
t 0074 116 |
u 0075 117 |
v 0076 118 |
w 0077 119 |
x 0078 120 |
y 0079 121 |
z 007A 122 |
{ 007B 123 |
| 007C 124 |
} 007D 125 |
~ 007E 126 |
DEL 007F 127 |
| 8_ | • +00 128 |
• +01 129 |
• +02 130 |
• +03 131 |
• +04 132 |
• +05 133 |
• +06 134 |
• +07 135 |
• +08 136 |
• +09 137 |
• +0A 138 |
• +0B 139 |
• +0C 140 |
• +0D 141 |
• +0E 142 |
• +0F 143 |
| 9_ | • +10 144 |
• +11 145 |
• +12 146 |
• +13 147 |
• +14 148 |
• +15 149 |
• +16 150 |
• +17 151 |
• +18 152 |
• +19 153 |
• +1A 154 |
• +1B 155 |
• +1C 156 |
• +1D 157 |
• +1E 158 |
• +1F 159 |
| A_ | • +20 160 |
• +21 161 |
• +22 162 |
• +23 163 |
• +24 164 |
• +25 165 |
• +26 166 |
• +27 167 |
• +28 168 |
• +29 169 |
• +2A 170 |
• +2B 171 |
• +2C 172 |
• +2D 173 |
• +2E 174 |
• +2F 175 |
| B_ | • +30 176 |
• +31 177 |
• +32 178 |
• +33 179 |
• +34 180 |
• +35 181 |
• +36 182 |
• +37 183 |
• +38 184 |
• +39 185 |
• +3A 186 |
• +3B 187 |
• +3C 188 |
• +3D 189 |
• +3E 190 |
• +3F 191 |
| 2-byte C_ |
0000 192 |
0040 193 |
Latin 0080 194 |
Latin 00C0 195 |
Latin 0100 196 |
Latin 0140 197 |
Latin 0180 198 |
Latin 01C0 199 |
Latin 0200 200 |
IPA 0240 201 |
IPA 0280 202 |
IPA 02C0 203 |
accents 0300 204 |
accents 0340 205 |
Greek 0380 206 |
Greek 03C0 207 |
| 2-byte D_ |
Cyril 0400 208 |
Cyril 0440 209 |
Cyril 0480 210 |
Cyril 04C0 211 |
Cyril 0500 212 |
Armeni 0540 213 |
Hebrew 0580 214 |
Hebrew 05C0 215 |
Arabic 0600 216 |
Arabic 0640 217 |
Arabic 0680 218 |
Arabic 06C0 219 |
Syriac 0700 220 |
Arabic 0740 221 |
Thaana 0780 222 |
N'Ko 07C0 223 |
| 3-byte E_ |
Indic 0800* 224 |
Misc. 1000 225 |
Symbol 2000 226 |
Kana, CJK 3000 227 |
CJK 4000 228 |
CJK 5000 229 |
CJK 6000 230 |
CJK 7000 231 |
CJK 8000 232 |
CJK 9000 233 |
Asian A000 234 |
Hangul B000 235 |
Hangul C000 236 |
Hangul D000 237 |
PUA E000 238 |
Forms F000 239 |
| 4‑byte F_ |
SMP, SIP 10000* 240 |
40000 241 |
80000 242 |
SSP, SPUA C0000 243 |
SPUA-B 100000 244 |
140000 245 |
180000 246 |
1C0000 247 |
5-byte 200000* 248 |
5-byte 1000000 249 |
5-byte 2000000 250 |
5-byte 3000000 251 |
6-byte 4000000* 252 |
6-byte 40000000 253 |
254 |
255 |
Orange cells with a large dot are continuation bytes. The hexadecimal number shown after a "+" plus sign is the value of the six bits they add.
White cells are the leading bytes for a sequence of multiple bytes, the length shown at the left edge of the row. The text shows the Unicode blocks encoded by sequences starting with this byte, and the hexadecimal code point shown in the cell is the lowest character value encoded using that leading byte.
Red cells must never appear in a valid UTF-8 sequence. The first two (C0 and C1) could only be used for an invalid "overlong encoding" of ASCII characters (i.e., trying to encode a 7-bit ASCII value between 0 and 127 using two bytes instead of one; see below). The remaining red cells indicate leading bytes of sequences that could only encode numbers larger than the 0x10FFFF limit of Unicode, or that were also never used in the original design for 31 bits (FE and FF).
Pink cells are the leading bytes for a sequence of multiple bytes, of which some, but not all, possible continuation sequences are valid. E0 and F0 could start overlong encodings, in this cast the lowest non-overlong-encoded code point is shown, marked by an asterisk "*". F4 can start code points greater than 0x10FFFF which are invalid. ED can start the encoding of a surrogate half that cannot be encoded in UTF-16 and are also invalid.
Overlong encodings
In principle, it would be possible to inflate the number of bytes in an encoding by padding the code point with leading 0s. To encode the Euro sign € from the above example in four bytes instead of three, it could be padded with leading 0s until it was 21 bits long – 000 000010 000010 101100, and encoded as 11110000 10000010 10000010 10101100 (or F0 82 82 AC in hexadecimal). This is called an overlong encoding.
The standard specifies that the correct encoding of a code point use only the minimum number of bytes required to hold the significant bits of the code point. Longer encodings are called overlong and are not valid UTF-8 representations of the code point. This rule maintains a one-to-one correspondence between code points and their valid encodings, so that there is a unique valid encoding for each code point. This ensures that string comparisons and searches are well-defined.
Modified UTF-8 uses the two-byte overlong encoding of U+0000 (the NUL character), 11000000 10000000 (hexadecimal C0 80), instead of 00000000 (hexadecimal 00). This allows the byte 00 to be used as a string terminator.
Invalid byte sequences
Not all sequences of bytes are valid UTF-8. A UTF-8 decoder should be prepared for:
- the red invalid bytes in the above table
- an unexpected continuation byte
- a leading byte not followed by enough continuation bytes (can happen in simple string truncation, when a string is too long to fit when copying it)
- an overlong encoding as described above
- a sequence that decodes to an invalid code point as described below
Many earlier decoders would happily try to decode these. Carefully crafted invalid UTF-8 could make them either skip or create ASCII characters such as NUL, slash, or quotes. Invalid UTF-8 has been used to bypass security validations in high-profile products including Microsoft's IIS web server[14] and Apache's Tomcat servlet container.[15]
RFC 3629 states "Implementations of the decoding algorithm MUST protect against decoding invalid sequences."[16] The Unicode Standard requires decoders to "...treat any ill-formed code unit sequence as an error condition. This guarantees that it will neither interpret nor emit an ill-formed code unit sequence."
Many UTF-8 decoders throw exceptions on encountering errors.[17] This can turn what would otherwise be harmless errors (producing a message such as "no such file") into a denial of service bug. Early versions of Python 3.0 would exit immediately if the command line or environment variables contained invalid UTF-8,[18] making it impossible to handle such errors.
More recent converters translate the first byte of an invalid sequence to a replacement character and continue parsing with the next byte. These error bytes will always have the high bit set. This avoids denial-of-service bugs, and it is very common in text rendering such as browser display, since mangled text is probably more useful than nothing for helping the user figure out what the string was supposed to contain. Popular replacements include:
- The replacement character "�" (U+FFFD) (or
EFBFBDin UTF-8) - The invalid Unicode code points U+DC80–U+DCFF where the low eight bits are the byte's value.[19] Sometimes it is called UTF-8B[20]
- The Unicode code points U+0080–U+00FF with the same value as the byte, thus interpreting the bytes according to ISO-8859-1
- The Unicode code point for the character represented by the byte in CP1252, which is similar to using ISO-8859-1, except that some characters in the range 0x80–0x9F are mapped into different Unicode code points. For example, 0x80 becomes the Euro sign, U+20AC.
These replacement algorithms are "lossy", as more than one sequence is translated to the same code point. This means that it would not be possible to reliably convert back to the original encoding, therefore losing information. Reserving 128 code points (such as U+DC80–U+DCFF) to indicate errors, and defining the UTF-8 encoding of these points as invalid so they convert to 3 errors, would seem to make conversion lossless. But this runs into practical difficulties: the converted text cannot be modified such that errors are arranged so they convert back into valid UTF-8, which means if the conversion is UTF-16, it cannot also be used to store arbitrary invalid UTF-16, which is usually needed on the same systems that need invalid UTF-8. U+DC80–U+DCFF are reserved for UTF-16 surrogates, so that when they are used for UTF-8 in this way, and the string is converted to UTF-16 this can lead to bugs or the string being rejected.
The large number of invalid byte sequences provides the advantage of making it easy to have a program accept both UTF-8 and legacy encodings such as ISO-8859-1. Software can check for UTF-8 correctness, and if that fails assume the input to be in the legacy encoding. It is technically true that this may detect an ISO-8859-1 string as UTF-8, but this is very unlikely if it contains any 8-bit bytes as they all have to be in unusual patterns of two or more in a row, such as "£".
Invalid code points
Since RFC 3629 (November 2003), the high and low surrogate halves used by UTF-16 (U+D800 through U+DFFF) and code points not encodable by UTF-16 (those after U+10FFFF) are not legal Unicode values, and their UTF-8 encoding must be treated as an invalid byte sequence.
Not decoding surrogate halves makes it impossible to store invalid UTF-16, such as Windows filenames, as UTF-8. Therefore, detecting these as errors is often not implemented and there are attempts to define this behavior formally (see WTF-8 and CESU below).
Official name and variants
The official Internet Assigned Numbers Authority (IANA) code for the encoding is "UTF-8".[21] All letters are upper-case, and the name is hyphenated. This spelling is used in all the Unicode Consortium documents relating to the encoding.
Alternatively, the name "utf-8" may be used by all standards conforming to the IANA list (which include CSS, HTML, XML, and HTTP headers),[22] as the declaration is case insensitive.[21]
Other descriptions that omit the hyphen or replace it with a space, such as "utf8" or "UTF 8", are not accepted as correct by the governing standards.[16] Despite this, most agents such as browsers can understand them, and so standards intended to describe existing practice (such as HTML5) may effectively require their recognition.
Unofficially, UTF-8-BOM and UTF-8-NOBOM are sometimes used to refer to text files which respectively contain and lack a byte order mark (BOM). In Japan especially, UTF-8 encoding without BOM is sometimes called "UTF-8N".[23][24]
In PCL, UTF-8 is called Symbol-ID "18N" (PCL supports 183 character encodings, called Symbol Sets, which potentially could be reduced to one, 18N, that is UTF-8).[25]
Derivatives
The following implementations show slight differences from the UTF-8 specification. They are incompatible with the UTF-8 specification.
CESU-8
Many programs added UTF-8 conversions for UCS-2 data and did not alter this UTF-8 conversion when UCS-2 was replaced with the surrogate-pair using UTF-16. In such programs each half of a UTF-16 surrogate pair is encoded as its own three-byte UTF-8 encoding, resulting in six-byte sequences rather than four bytes for characters outside the Basic Multilingual Plane. Oracle and MySQL databases use this, as well as Java and Tcl as described below, and probably many Windows programs where the programmers were unaware of the complexities of UTF-16. Although this non-optimal encoding is generally not deliberate, a supposed benefit is that it preserves UTF-16 binary sorting order when CESU-8 is binary sorted.
Modified UTF-8
In Modified UTF-8 (MUTF-8),[26] the null character (U+0000) uses the two-byte overlong encoding 11000000 10000000 (hexadecimal C0 80), instead of 00000000 (hexadecimal 00). Modified UTF-8 strings never contain any actual null bytes but can contain all Unicode code points including U+0000,[27] which allows such strings (with a null byte appended) to be processed by traditional null-terminated string functions.
All known Modified UTF-8 implementations also treat the surrogate pairs as in CESU-8.
In normal usage, the Java programming language supports standard UTF-8 when reading and writing strings through InputStreamReader and OutputStreamWriter (if it is the platform's default character set or as requested by the program). However it uses Modified UTF-8 for object serialization[28] among other applications of DataInput and DataOutput, for the Java Native Interface,[29] and for embedding constant strings in class files.[30]
The dex format defined by Dalvik also uses the same modified UTF-8 to represent string values.[31]
Tcl also uses the same modified UTF-8[32] as Java for internal representation of Unicode data, but uses strict CESU-8 for external data.
WTF-8
WTF-8 (Wobbly Transformation Format – 8-bit) is an extension of UTF-8 where the encodings of the surrogate halves (U+D800 through U+DFFF) are allowed.[33] This is necessary to store possibly-invalid UTF-16, such as Windows filenames. Many systems that deal with UTF-8 work this way without considering it a different encoding, as it is simpler.
WTF-8 has been used to refer to erroneously doubly-encoded UTF-8.[34][35][36]
Byte order mark
Many Windows programs (including Windows Notepad) add the bytes 0xEF, 0xBB, 0xBF at the start of any document saved as UTF-8. This is the UTF-8 encoding of the Unicode byte order mark (BOM), and is commonly referred to as a UTF-8 BOM, even though it is not relevant to byte order. A BOM can also appear if another encoding with a BOM is translated to UTF-8 without stripping it. Software that is not aware of multibyte encodings will display the BOM as three garbage characters at the start of the document, e.g. "" in software interpreting the document as ISO 8859-1 or Windows-1252 or "" if interpreted as code page 437, default for Windows console applications.
The Unicode Standard neither requires nor recommends the use of the BOM for UTF-8, but does allow the character to be at the start of a file.[37] The presence of the UTF-8 BOM may cause problems with existing software that could otherwise handle UTF-8, for example:
- Programming language parsers not explicitly designed for UTF-8 can often handle UTF-8 in string constants and comments, but cannot parse the BOM at the start of the file.
- Programs that identify file types by leading characters may fail to identify the file if a BOM is present even if the user of the file could skip the BOM. An example is the Unix shebang syntax. Another example is Internet Explorer which will render pages in standards mode only when it starts with a document type declaration.
- Programs that insert information at the start of a file will break use of the BOM to identify UTF-8 (one example is offline browsers that add the originating URL to the start of the file).
Advantages and disadvantages
General
Advantages
- UTF-8 is the only encoding for XML entities that does not require a BOM or an indication of the encoding.[38]
- UTF-8 and UTF-16 are the standard encodings for Unicode text in HTML documents, with UTF-8 as the preferred and most used encoding.
- UTF-8 strings can be fairly reliably recognized as such by a simple heuristic algorithm.[39] Valid UTF-8 cannot contain a lone byte with the high bit set, and the chance that any pair of bytes both with the high bit set is valid UTF-8 is 11.7%[nb 1] and the odds are much lower for longer sequences. This makes it extremely unlikely that text in any other encoding (such as ISO/IEC 8859-1) is valid UTF-8. This is an advantage that most other encodings do not have, and allows UTF-8 to be mixed with a legacy encoding without having to add data to identify which encoding is in use, avoiding errors (mojibake) typically encountered when trying to change a system to a new default encoding, or introducing data with a different encoding than the default one.
- Sorting a set of UTF-8 encoded strings as strings of unsigned bytes yields the same order as sorting the corresponding Unicode strings lexicographically by codepoint.
- Ascii is valid UTF8 and has the shortest possible encoding. Even in non western languages, for XML documents like HTML, docx or odt, ascii characters are almost always the most common ones due to the large amount of markup.
- UTF-8 uses the codes 0–127 only for the ASCII characters. This means that UTF-8 is an ASCII extension and can be processed by software that supports 7-bit characters and assigns no meaning to non-ASCII bytes. This means that strings in most programming languages which use single byte charcters can use the same native interface. This greatly simplifies adapting software for international use as only the part of the software that deals with user interaction and system software to present glyphs need to be upgraded. By contrast, in Shift-JIS a byte that can be a 7-bit ASCII character can also be used as part of a multi-byte character; the byte 0x5C, for example, might be part of a multibyte character, but in the context of a string some programming languages or application software would instead interpret it as a backslash ('\') and assume that it marks the beginning of an escape sequence, incorrectly influencing the interpretation of subsequent bytes.[40] And if using UTF-16 for an upgrade of old software, all code which handle strings must be rewritten. If translating strings using UTF-16 software such as Excel, conversion to UTF-8 is well-defined and done by copy-and-paste into the editor, in opposite to using various 8-bit code pages for internationalization.
Compared to single-byte encodings
Advantages
- UTF-8 can encode any Unicode character, avoiding the need to figure out and set a "code page" or otherwise indicate what character set is in use, and allowing output in multiple scripts at the same time. For many scripts there have been more than one single-byte encoding in usage, so even knowing the script was insufficient information to display it correctly.
- The bytes 0xFE and 0xFF do not appear, so a valid UTF-8 stream never matches the UTF-16 byte order mark and thus cannot be confused with it. The absence of 0xFF (0377) also eliminates the need to escape this byte in Telnet (and FTP control connection).
Disadvantages
- UTF-8 encoded text is larger than specialized single-byte encodings except for plain ASCII characters. In the case of scripts which used 8-bit character sets with non-Latin characters encoded in the upper half (such as most Cyrillic and Greek alphabet code pages), characters in UTF-8 will be double the size. For some scripts, such as Thai and Hindi's Devanagari, characters will triple in size. There are even examples where a single byte turns into a composite character in Unicode and is thus six times larger in UTF-8. This has caused objections in India and other countries.
- It is possible in UTF-8 (or any other multi-byte encoding) to split or truncate a string in the middle of a character. This can result in an invalid string which some software refuse to accept. A good parser should ignore a truncated character at the end, which is easy in UTF-8 but tricky in some other multi-byte encodings.
- If the code points are all the same size, measurements of a fixed number of them is easy. Due to ASCII-era documentation where "character" is used as a synonym for "byte" this is often considered important. However, by measuring string positions using bytes instead of "characters" most algorithms can be easily and efficiently adapted for UTF-8. Searching for a string within a long string can for example be done byte by byte.
- Some software, such as text editors, will refuse to correctly display or interpret UTF-8 unless the text starts with a byte order mark, and will insert such a mark. This has the effect of making it impossible to use UTF-8 with any older software that can handle ASCII-like encodings but cannot handle the byte order mark. This, however, is no problem of UTF-8 itself but one of bad software implementations.
Compared to other multi-byte encodings
Advantages
- UTF-8 can encode any Unicode character. Files in different scripts can be displayed correctly without having to choose the correct code page or font. For instance Chinese and Arabic can be supported (in the same text) without special codes inserted or manual settings to switch the encoding.
- UTF-8 is self-synchronizing: character boundaries are easily identified by scanning for well-defined bit patterns in either direction. If bytes are lost due to error or corruption, one can always locate the next valid character and resume processing. If there is a need to shorten a string to fit a specified field, the previous valid character can easily be found. Many multi-byte encodings are much harder to resynchronize.
- Any byte oriented string searching algorithm can be used with UTF-8 data, since the sequence of bytes for a character cannot occur anywhere else. Some older variable-length encodings (such as Shift JIS) did not have this property and thus made string-matching algorithms rather complicated. In Shift JIS the end byte of a character and the first byte of the next character could look like another legal character, something that can't happen in UTF-8.
- Efficient to encode using simple bit operations. UTF-8 does not require slower mathematical operations such as multiplication or division (unlike the obsolete UTF-1 encoding).
Disadvantages
- UTF-8 will take more space than a multi-byte encoding designed for a specific script. East Asian legacy encodings generally used two bytes per character yet take three bytes per character in UTF-8.
Compared to UTF-16
Advantages
- Byte encodings and UTF-8 are represented by byte arrays in programs, and often nothing needs to be done to a function when converting from a byte encoding to UTF-8. UTF-16 is represented by 16-bit word arrays, and converting to UTF-16 while maintaining compatibility with existing ASCII-based programs (such as was done with Windows) requires every API and data structure that takes a string to be duplicated, one version accepting byte strings and another version accepting UTF-16.
- Text encoded in UTF-8 will be smaller than the same text encoded in UTF-16 if there are more code points below U+0080 than in the range U+0800..U+FFFF. This is true for all modern European languages.
- Most of the rich text formats (including HTML) contain a large proportion of ASCII characters for the sake of formatting, thus the size usually will be reduced significantly compared to UTF-16, even when the language mostly uses 3-byte long characters in UTF-8.[nb 2]
- Most communication and storage was designed for a stream of bytes. A UTF-16 string must use a pair of bytes for each code unit:
- The order of those two bytes becomes an issue and must be specified in the UTF-16 protocol, such as with a byte order mark.
- If an odd number of bytes is missing from UTF-16, the whole rest of the string will be meaningless text. Any bytes missing from UTF-8 will still allow the text to be recovered accurately starting with the next character after the missing bytes.
Disadvantages
- Characters U+0800 through U+FFFF use three bytes in UTF-8, but only two in UTF-16. As a result, text in (for example) Chinese, Japanese or Hindi will take more space in UTF-8 if there are more of these characters than there are ASCII characters. The impact becomes greater when data mainly consist of pure prose, but is lessened by the degree to which the context uses spaces, line terminators, digits, and punctuation that are encoded in ASCII.[nb 3]
See also
- Alt code
- Character encodings in HTML
- Comparison of e-mail clients § Features
- Comparison of Unicode encodings
- GB 18030
- Iconv – a standardized API used to convert between different character encodings
- ISO/IEC 8859
- Specials (Unicode block)
- Unicode and e-mail
- Unicode and HTML
- Universal Character Set
- UTF-8 in URIs
- UTF-EBCDIC
- UTF-9 and UTF-18
- UTF-16/UCS-2
Notes
- ↑ 1920 valid two-byte UTF-8 characters over 128 × 128 possible two-byte sequences.
- ↑ The 2010-10-27 version of UTF-8 generated 169 KB when converted with Notepad to UTF-16, and only 101 KB when converted back to UTF-8. The 2010-11-22 version of यूनिकोड (Unicode in Hindi) required 119 KB in UTF-16 and 76 KB in UTF-8.
- ↑ The 2010-11-22 version of यूनिकोड (Unicode in Hindi), when the pure text was pasted to Notepad, generated 19 KB when saved as UTF-16 and 22 KB when saved as UTF-8.
References
- 1 2 Email Subject: UTF-8 history, From: "Rob 'Commander' Pike", Date: Wed, 30 Apr 2003..., ...UTF-8 was designed, in front of my eyes, on a placemat in a New Jersey diner one night in September or so 1992...So that night Ken wrote packing and unpacking code and I started tearing into the C and graphics libraries. The next day all the code was done...
- ↑ "Chapter 2. General Structure". The Unicode Standard (6.0 ed.). Mountain View, California, USA: The Unicode Consortium. ISBN 978-1-936213-01-6.
- ↑ Davis, Mark (2010-01-28). "Unicode nearing 50% of the web". Official Google Blog. Google. Retrieved 2010-12-05.
- ↑ "Usage Statistics of Character Encodings for Websites, (updated daily)". W3Techs. Retrieved 2016-02-21.
- ↑ "UTF-8 Usage Statistics". BuiltWith. Retrieved 2011-03-28.
- ↑ "Using International Characters in Internet Mail". Internet Mail Consortium. 1998-08-01. Retrieved 2007-11-08.
- ↑ "Specifying the document's character encoding", HTML5, World Wide Web Consortium, 2014-06-17, retrieved 2014-07-30
- ↑ "Appendix F. FSS-UTF / File System Safe UCS Transformation format" (PDF). The Unicode Standard 1.1. Archived (PDF) from the original on 2016-06-07. Retrieved 2016-06-07.
- ↑ Whistler, Kenneth (2001-06-12). "FSS-UTF, UTF-2, UTF-8, and UTF-16". Archived from the original on 2016-06-07. Retrieved 2006-06-07.
- 1 2 Pike, Rob (2003-04-30). "UTF-8 history". Retrieved 2012-09-07.
- ↑ Pike, Rob (2012-09-06). "UTF-8 turned 20 years old yesterday". Retrieved 2012-09-07.
- ↑ Davis, Mark (2008-05-05). "Moving to Unicode 5.1". Retrieved 2013-03-01.
- ↑ Allen, Julie D.; Anderson, Deborah; Becker, Joe; Cook, Richard, eds. (2012). "The Unicode Standard, Version 6.1". Mountain View, California: Unicode Consortium.
The Basic Multilingual Plane (BMP, or Plane 0) contains the common-use characters for all the modern scripts of the world as well as many historical and rare characters. By far the majority of all Unicode characters for almost all textual data can be found in the BMP.
- ↑ Marin, Marvin (2000-10-17). "Web Server Folder Traversal MS00-078".
- ↑ "National Vulnerability Database - Summary for CVE-2008-2938".
- 1 2 Yergeau, F. (2003). "RFC 3629 - UTF-8, a transformation format of ISO 10646". Internet Engineering Task Force. Retrieved 2015-02-03.
- ↑ Java's DataInput IO Interface
- ↑ "Non-decodable Bytes in System Character Interfaces". python.org. 2009-04-22. Retrieved 2014-08-13.
- ↑ Kuhn, Markus (2000-07-23). "Substituting malformed UTF-8 sequences in a decoder". Archived from the original on 2015-03-15. Retrieved 2014-09-25.
- ↑ Sittler, B. (2006-04-02). "Binary vs. UTF-8, and why it need not matter". Retrieved 2014-09-25.
- 1 2 "Character Sets". Internet Assigned Numbers Authority. 2013-01-23. Retrieved 2013-02-08.
- ↑ Dürst, Martin. "Setting the HTTP charset parameter". W3C. Retrieved 2013-02-08.
- ↑ "BOM - suikawiki" (in Japanese). Retrieved 2013-04-26.
- ↑ Davis, Mark. "Forms of Unicode". IBM. Archived from the original on 2005-05-06. Retrieved 2013-09-18.
- ↑ PCL Symbol Sets
- ↑ "Java SE documentation for Interface java.io.DataInput, subsection on Modified UTF-8". Oracle Corporation. 2015. Retrieved 2015-10-16.
- ↑ "The Java Virtual Machine Specification, section 4.4.7: "The CONSTANT_Utf8_info Structure"". Oracle Corporation. 2015. Retrieved 2015-10-16.
Java virtual machine UTF-8 strings never have embedded nulls.
- ↑ "Java Object Serialization Specification, chapter 6: Object Serialization Stream Protocol, section 2: Stream Elements". Oracle Corporation. 2010. Retrieved 2015-10-16.
[…] encoded in modified UTF-8.
- ↑ "Java Native Interface Specification, chapter 3: JNI Types and Data Structures, section: Modified UTF-8 Strings". Oracle Corporation. 2015. Retrieved 2015-10-16.
The JNI uses modified UTF-8 strings to represent various string types.
- ↑ "The Java Virtual Machine Specification, section 4.4.7: "The CONSTANT_Utf8_info Structure"". Oracle Corporation. 2015. Retrieved 2015-10-16.
[…] differences between this format and the "standard" UTF-8 format.
- ↑ "ART and Dalvik". Android Open Source Project. Retrieved 2013-04-09.
[T]he dex format encodes its string data in a de facto standard modified UTF-8 form, hereafter referred to as MUTF-8.
- ↑ "Tcler's Wiki: UTF-8 bit by bit (Revision 6)". 2009-04-25. Retrieved 2009-05-22.
In orthodox UTF-8, a NUL byte (\x00) is represented by a NUL byte. […] But […] we […] want NUL bytes inside […] strings […]
- ↑ Sapin, Simon (2016-03-11) [2014-09-25]. "The WTF-8 encoding". Archived from the original on 2016-05-24. Retrieved 2016-05-24.
- ↑ "WTF-8.com". 2006-05-18. Retrieved 2016-06-21.
- ↑ Speer, Rob (2015-05-21). "ftfy (fixes text for you) 4.0: changing less and fixing more". Retrieved 2016-06-21.
- ↑ "WTF-8, a transformation format of code page 1252". www-uxsup.csx.cam.ac.uk. Retrieved 2016-10-12.
- ↑ "The Unicode Standard - Chapter 2" (PDF). p. 30.
- ↑ "Extensible Markup Language (XML) 1.0 (Fifth Edition)". W3C. 2008-11-26. Retrieved 2013-02-08.
- ↑ Dürst, Martin. "Multilingual Forms". W3C. Retrieved 2013-02-08.
- ↑ "#418058 - iconv: half-smart on ascii compatible code conversion (shift-jis) - Debian Bug report logs". Bugs.debian.org. 2007-04-06. Retrieved 2014-06-13.
External links
| Look up UTF-8 in Wiktionary, the free dictionary. |
There are several current definitions of UTF-8 in various standards documents:
- RFC 3629 / STD 63 (2003), which establishes UTF-8 as a standard Internet protocol element
- The Unicode Standard, Version 6.0, §3.9 D92, §3.10 D95 (2011)
- ISO/IEC 10646:2012 §9.1
They supersede the definitions given in the following obsolete works:
- ISO/IEC 10646-1:1993 Amendment 2 / Annex R (1996)
- The Unicode Standard, Version 5.0, §3.9 D92, §3.10 D95 (2007)
- The Unicode Standard, Version 4.0, §3.9–§3.10 (2003)
- The Unicode Standard, Version 2.0, Appendix A (1996)
- RFC 2044 (1996)
- RFC 2279 (1998)
- The Unicode Standard, Version 3.0, §2.3 (2000) plus Corrigendum #1 : UTF-8 Shortest Form (2000)
- Unicode Standard Annex #27: Unicode 3.1 (2001)
They are all the same in their general mechanics, with the main differences being on issues such as allowed range of code point values and safe handling of invalid input.
- Original UTF-8 paper (or pdf) for Plan 9 from Bell Labs
- RFC 5198 defines UTF-8 NFC for Network Interchange
- UTF-8 test pages by Andreas Prilop, Jost Gippert and the World Wide Web Consortium
- Unix/Linux: UTF-8/Unicode FAQ, Linux Unicode HOWTO, UTF-8 and Gentoo
- The Unicode/UTF-8-character table displays UTF-8 in a variety of formats (with Unicode and HTML encoding information)
- Characters, Symbols and the Unicode Miracle – Computerphile on YouTube
| Early telecommunications |
|
|---|---|
| ISO/IEC 8859 | |
| Bibliographic use | |
| National standards | |
| EUC | |
| ISO/IEC 2022 | |
| MacOS code pages ("scripts") | |
| DOS code pages |
|
| IBM AIX code pages | |
| IBM Apple MacIntosh Emulations | |
| IBM Adobe Emulations |
|
| IBM DEC Emulations |
|
| IBM HP Emulations | |
| Windows code pages | |
| EBCDIC code pages |
|
| Platform specific |
|
| Unicode / ISO/IEC 10646 | |
| Miscellaneous code pages | |
| Related topics | |