Han unification
Han unification is an effort by the authors of Unicode and the Universal Character Set to map multiple character sets of the so-called CJK languages into a single set of unified characters. Han characters are a common feature of written Chinese (hanzi), Japanese (kanji), and Korean (hanja).
Modern Chinese, Japanese and Korean typefaces typically use regional or historical variants of a given Han character. In the formulation of Unicode, an attempt was made to unify these variants by considering them different glyphs representing the same "grapheme", or orthographic unit, hence, "Han unification", with the resulting character repertoire sometimes contracted to Unihan.
Unihan can also refer to the Unihan Database maintained by the Unicode Consortium, which provides information about all of the unified Han characters encoded in the Unicode Standard, including mappings to various national and industry standards, indices into standard dictionaries, encoded variants, pronunciations in various languages, and an English definition. The database is available to the public as text files[1] and via an interactive Web site.[2][3] The latter also includes representative glyphs and definitions for compound words drawn from the free Japanese EDICT and Chinese CEDICT dictionary projects (which are provided for convenience and are not a formal part of the Unicode Standard).
Rationale and controversy
The Unicode Standard details the principles of Han unification.[4][5] The Ideographic Rapporteur Group (IRG), made up of experts from the Chinese-speaking countries, North and South Korea, Japan, Vietnam, and other countries, is responsible for the process.
One possible rationale is the desire to limit the size of the full Unicode character set, where CJK characters as represented by discrete ideograms may approach or exceed 100,000 (while those required for ordinary literacy in any language are probably under 3,000). Version 1 of Unicode was designed to fit into 16 bits and only 20,940 characters (32%) out of the possible 65,536 were reserved for these CJK Unified Ideographs. Later Unicode has been extended to 21 bits allowing many more CJK characters (80,388 are assigned, with room for more).
The secret life of Unicode article located on IBM DeveloperWorks attempts to illustrate part of the motivation for Han unification:
The problem stems from the fact that Unicode encodes characters rather than "glyphs," which are the visual representations of the characters. There are four basic traditions for East Asian character shapes: traditional Chinese, simplified Chinese, Japanese, and Korean. While the Han root character may be the same for CJK languages, the glyphs in common use for the same characters may not be, and new characters were invented in each country.For example, the traditional Chinese glyph for "grass" uses four strokes for the "grass" radical 艹, whereas the simplified Chinese, Japanese, and Korean glyphs use three. But there is only one Unicode point for the grass character (U+8349) regardless of writing system. Another example is the ideograph for "one" (壹, 壱, or 一), which is different in Chinese, Japanese, and Korean. Many people think that the three versions should be encoded differently.
In fact, the three ideographs for "one" are encoded separately in Unicode, as they are not considered national variants. The first and second are used on financial instruments to prevent tampering (they may be considered variants), while the third is the common form in all three countries.
However, Han unification has also caused considerable controversy, particularly among the Japanese public, who, with the nation's literati, have a history of protesting the culling of historically and culturally significant variants. (See Kanji#Orthographic reform and lists of kanji. Today, the list of characters officially recognized for use in proper names continues to expand at a modest pace.)
Graphemes versus glyphs
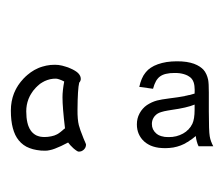
A grapheme is the smallest abstract unit of meaning in a writing system. Any grapheme has many possible glyph expressions, but all are recognized as the same grapheme by those with reading and writing knowledge of a particular writing system. Although Unicode typically assigns characters to code points to express the graphemes within a system of writing, the Unicode Standard (section 3.4 D7) does with caution:
An abstract character does not necessarily correspond to what a user thinks of as a "character" and should not be confused with a grapheme.
However, this quote refers to the fact that some graphemes are composed of several characters. So, for example, the character U+0061 a LATIN SMALL LETTER A combined with U+030A ◌̊ COMBINING RING ABOVE (i.e. the combination "å") might be understood by a user as a single grapheme while being composed of multiple Unicode abstract characters. In addition, Unicode also assigns some code points to a small number (other than for compatibility reasons) of formatting characters, whitespace characters, and other abstract characters that are not graphemes, but instead used to control the breaks between lines, words, graphemes and grapheme clusters. With the unified Han ideographs, the Unicode Standard makes a departure from prior practices in assigning abstract characters not as graphemes, but according to the underlying meaning of the grapheme: what linguists sometimes call sememes. This departure therefore is not simply explained by the oft quoted distinction between an abstract character and a glyph, but is more rooted in the difference between an abstract character assigned as a grapheme and an abstract character assigned as a sememe. In contrast, consider ASCII's unification of punctuation and diacritics, where graphemes with widely different meanings (for example, an apostrophe and a single quotation mark) are unified because the graphemes are the same. For Unihan the characters are not unified by their appearance, but by their definition or meaning.
For a grapheme to be represented by various glyphs means that the grapheme has glyph variations that are usually determined by selecting one font or another or using glyph substitution features where multiple glyphs are included in a single font. Such glyph variations are considered by Unicode a feature of rich text protocols and not properly handled by the plain text goals of Unicode. However, when the change from one glyph to another constitutes a change from one grapheme to another—where a glyph cannot possibly still, for example, mean the same grapheme understood as the small letter "a"—Unicode separates those into separate code points. For Unihan the same thing is done whenever the abstract meaning changes, however rather than speaking of the abstract meaning of a grapheme (the letter "a"), the unification of Han ideographs assigns a new code point for each different meaning—even if that meaning is expressed by distinct graphemes in different languages. Although a grapheme such as "ö" might mean something different in English (as used in the word "coördinated") than it does in German, it is still the same grapheme and can be easily unified so that English and German can share a common abstract Latin writing system (along with Latin itself). This example also points to another reason that "abstract character" and grapheme as an abstract unit in a written language do not necessarily map one-to-one. In English the combining diaeresis, "¨", and the "o" it modifies may be seen as two separate graphemes, whereas in languages such as Swedish, the letter "ö" may be seen as a single grapheme. Similarly in English the dot on an "i" is understood as a part of the "i" grapheme whereas in other languages, such as Turkish, the dot may be seen as a separate grapheme added to the dotless "ı".
To deal with the use of different graphemes for the same Unihan sememe, Unicode has relied on several mechanisms: especially as it relates to rendering text. One has been to treat it as simply a font issue so that different fonts might be used to render Chinese, Japanese or Korean. Also font formats such as OpenType allow for the mapping of alternate glyphs according to language so that a text rendering system can look to the user's environmental settings to determine which glyph to use. The problem with these approaches is that they fail to meet the goals of Unicode to define a consistent way of encoding multilingual text.[6]
So rather than treat the issue as a rich text problem of glyph alternates, Unicode added the concept of variation selectors, first introduced in version 3.2 and supplemented in version 4.0.[7] While variation selectors are treated as combining characters, they have no associated diacritic or mark. Instead, by combining with a base character, they signal the two character sequence selects a variation (typically in terms of grapheme, but also in terms of underlying meaning as in the case of a location name or other proper noun) of the base character. This then is not a selection of an alternate glyph, but the selection of a grapheme variation or a variation of the base abstract character. Such a two-character sequence however can be easily mapped to a separate single glyph in modern fonts. Since Unicode has assigned 256 separate variation selectors, it is capable of assigning 256 variations for any Han ideograph. Such variations can be specific to one language or another and enable the encoding of plain text that includes such grapheme variations.
Unihan "abstract characters"
Since the Unihan standard encodes "abstract characters", not "glyphs", the graphical artifacts produced by Unicode have been considered temporary technical hurdles, and at most, cosmetic. However, again, particularly in Japan, due in part to the way in which Chinese characters were incorporated into Japanese writing systems historically, the inability to specify a particular variant was considered a significant obstacle to the use of Unicode in scholarly work. For example, the unification of "grass" (explained above), means that a historical text cannot be encoded so as to preserve its peculiar orthography. Instead, for example, the scholar would be required to locate the desired glyph in a specific typeface in order to convey the text as written, defeating the purpose of a unified character set. Unicode has responded to these needs by assigning variation selectors so that authors can select grapheme variations of particular ideographs (or even other characters).[7]
Small differences in graphical representation are also problematic when they affect legibility or the wrong cultural tradition. Besides making some Unicode fonts unusable for texts involving multiple "Unihan languages", names or other orthographically sensitive terminology might be displayed incorrectly. (Proper names tend to be especially orthographically conservative—compare this to changing the spelling of one's name to suit a language reform in the US or UK) While this may be considered primarily a graphical representation or rendering problem to be overcome by more artful fonts, the widespread use of Unicode would make it difficult to preserve such distinctions. The problem of one character representing semantically different concepts is also present in the Latin part of Unicode. The Unicode character for an apostrophe is the same as the character for a right single quote (’). On the other hand, the capital Latin letter "A" is not unified with the Greek letter "Α" (Alpha). This is, of course, desirable for reasons of compatibility, and deals with a much smaller alphabetic character set.
While the unification aspect of Unicode is controversial in some quarters for the reasons given above, Unicode itself does now encode a vast number of seldom-used characters of a more-or-less antiquarian nature.
Some of the controversy stems from the fact that the very decision of performing Han unification was made by the initial Unicode Consortium, which at the time was a consortium of North American companies and organizations (most of them in California),[8] but included no East Asia government representatives. The initial design goal was to create a 16-bit standard,[9] and Han unification was therefore a critical step for avoiding tens of thousands of character duplications. This 16-bit requirement was later abandoned, making the size of the character set less an issue today.
The controversy later extended to the internationally representative ISO: the initial CJK-JRG group favored a proposal (DIS 10646) for a non-unified character set, "which was thrown out in favor of unification with the Unicode Consortium's unified character set by the votes of American and European ISO members" (even though the Japanese position was unclear).[10] Endorsing the Unicode Han unification was a necessary step for the heated ISO 10646/Unicode merger.
Much of the controversy surrounding Han unification is based on the distinction between glyphs, as defined in Unicode, and the related but distinct idea of graphemes. Unicode assigns abstract characters (graphemes), as opposed to glyphs, which are a particular visual representations of a character in a specific typeface. One character may be represented by many distinct glyphs, for example a "g" or an "a", both of which may have one loop (a, g) or two (a, g). Yet for a reader of Latin script based languages the two variations of the "a" character are both recognized as the same grapheme. Graphemes present in national character code standards have been added to Unicode, as required by Unicode's Source Separation rule, even where they can be composed of characters already available. The national character code standards existing in CJK languages are considerably more involved, given the technological limitations under which they evolved, and so the official CJK participants in Han unification may well have been amenable to reform.
Unlike European versions, CJK Unicode fonts, due to Han unification, have large but irregular patterns of overlap, requiring language-specific fonts. Unfortunately, language-specific fonts also make it difficult to access to a variant which, as with the "grass" example, happens to appear more typically in another language style. (That is to say, it would be difficult to access "grass" with the four-stroke radical more typical of Traditional Chinese in a Japanese environment, which fonts would typically depict the three-stroke radical.) Unihan proponents tend to favor markup languages for defining language strings, but this would not ensure the use of a specific variant in the case given, only the language-specific font more likely to depict a character as that variant. (At this point, merely stylistic differences do enter in, as a selection of Japanese and Chinese fonts are not likely to be visually compatible.)
Chinese users seem to have fewer objections to Han unification, largely because Unicode did not attempt to unify Simplified Chinese characters (an invention of the People's Republic of China, and in use among Chinese speakers in the PRC, Singapore, and Malaysia), with Traditional Chinese characters, as used in Hong Kong, Taiwan (Big5), and, with some differences, more familiar to Korean and Japanese users. Unicode is seen as neutral with regards to this politically charged issue, and has encoded Simplified and Traditional Chinese glyphs separately (e.g. the ideograph for "discard" is 丟 U+4E1F for Traditional Chinese Big5 #A5E1 and 丢 U+4E22 for Simplified Chinese GB #2210). It is also noted that Traditional and Simplified characters should be encoded separately according to Unicode Han Unification rules, because they are distinguished in pre-existing PRC character sets. Furthermore, as with other variants, Traditional to Simplified characters is not a one-to-one relationship.
Alternatives
Specialist character sets developed to address, or regarded by some as not suffering from, these perceived deficiencies include:
- ISO/IEC 2022 (based on sequence codes to switch between Chinese, Japanese, Korean character sets - hence without unification)
- CNS character set
- CCCII character set
- TRON
- Mojikyo
- Big5 extensions
- GCCS and its successor HKSCS
However, none of these alternative standards has been as widely adopted as Unicode, which is now the base character set for many new standards and protocols, and is built into the architecture of operating systems (Microsoft Windows, Apple Mac OS X, and many Unix-like systems), programming languages (Perl, Python, C#, Java, Common Lisp, APL), and libraries (IBM International Components for Unicode (ICU) along with the Pango, Graphite, Scribe, Uniscribe, and ATSUI rendering engines), font formats (TrueType and OpenType) and so on.
Political unification attempts
During the 5th Northeast Asia Trilateral Forum, selection and popularization of 500 Chinese characters among the three countries were performed.[11][12]
During the 8th Northeast Asia Trilateral Forum (held by Xinhua News Agency, Nikkei News Group, JoongAng Ilbo) on July 8, 2013, a draft bill (Draft Chart of Most Commonly-Used 800 Chinese Characters among the three countries) edited by former Renmin University of China president Ji Baocheng containing a list 800 unified CJK ideographs was announced. The chart includes 801 characters from China, 7 of which are less frequently characters; 710 from Japan and 801 from South Korea. The International Academic Symposium to compile the 808 characters was held in Beijing, China on October 23 to 24, 2013. A final version of the bill was to be announced in the 9th Northeast Asia Trilateral Forum in 2014.[13][14][15][16][17]
Examples of language-dependent glyphs
In each row of the following table, the same character is repeated in all five columns. However, each column is marked (by the lang attribute) as being in a different language: Chinese (two varieties: simplified and traditional), Japanese, Korean, or Vietnamese. The browser should select, for each character, a glyph (from a font) suitable to the specified language. (Besides actual character variation—look for differences in stroke order, number, or direction—the typefaces may also reflect different typographical styles, as with serif and non-serif alphabets.) This only works for fallback glyph selection if you have CJK fonts installed on your system and the font selected to display this article does not include glyphs for these characters.
| Code point | Chinese (simplified) (zh-Hans) |
Chinese (traditional) (zh-Hant) |
Japanese (ja) |
Korean (ko) |
Vietnamese (vi-nom) |
English |
|---|---|---|---|---|---|---|
| U+4E0E | 与 | 与 | 与 | 与 | 与 | for |
| U+4ECA | 今 | 今 | 今 | 今 | 今 | now |
| U+4EE4 | 令 | 令 | 令 | 令 | 令 | cause/command |
| U+514D | 免 | 免 | 免 | 免 | 免 | exempt/spare |
| U+5165 | 入 | 入 | 入 | 入 | 入 | enter |
| U+5168 | 全 | 全 | 全 | 全 | 全 | all/total |
| U+5177 | 具 | 具 | 具 | 具 | 具 | tool |
| U+5203 | 刃 | 刃 | 刃 | 刃 | 刃 | knife edge |
| U+5316 | 化 | 化 | 化 | 化 | 化 | transform/change |
| U+5916 | 外 | 外 | 外 | 外 | 化 | outside |
| U+60C5 | 情 | 情 | 情 | 情 | 情 | feeling |
| U+624D | 才 | 才 | 才 | 才 | 免 | talent |
| U+62B5 | 抵 | 抵 | 抵 | 抵 | 抵 | arrive/resist |
| U+6B21 | 次 | 次 | 次 | 次 | 次 | secondary/follow |
| U+6D77 | 海 | 海 | 海 | 海 | 具 | sea |
| U+753B | 画 | 画 | 画 | 画 | 画 | face/surface/flour |
| U+76F4 | 直 | 直 | 直 | 直 | 直 | direct/straight |
| U+771F | 真 | 真 | 真 | 真 | 真 | true |
| U+795E | 神 | 神 | 神 | 神 | 神 | god |
| U+7A7A | 空 | 空 | 空 | 空 | 空 | empty/air |
| U+8005 | 者 | 者 | 者 | 者 | 者 | one who does/-ist/-er |
| U+8349 | 草 | 草 | 草 | 草 | 草 | grass |
| U+89D2 | 角 | 角 | 角 | 角 | 角 | edge/horn |
| U+9053 | 道 | 道 | 道 | 道 | 道 | road |
| U+96C7 | 雇 | 雇 | 雇 | 雇 | 雇 | employ |
| U+9AA8 | 骨 | 骨 | 骨 | 骨 | 骨 | bone |
者 (U+8005) has an additional stroke (dot) on the right side in Korea. 全 (U+5168) has 入 (U+5165) as the top radical in Korea and elsewhere it is the 人 (U+4EBA) radical. No character that is a Korean or Vietnamese variant of a common character gets its own code point.
On the other hand, the source separation rule means that intentionally simplified characters in the PRC (Simplified Chinese) and in Japan (Shinjitai Reform) get unique code points.
The PRC and Japan in the twentieth century made their own respective encoding standards. Within each standard, there coexisted variants with unique code points, hence the unique code points in Unicode for certain sets of variants. Taking Simplified Chinese as an example, the difference in 內 (U+5167) and 内 (U+5185) is the same as the difference in Korean and non-Korean variants of 全 (U+5168), but here the variants in unique code points because the PRC encoded them separately when it designated 内 (U+5185) as simplified. Korea never had coexisting variants of 全 (U+5168). Korea only used its version with 入 as the radical at the top and never encoded the other version. Within the national standards in China, South Korea, and Japan, there was only version of 全 (U+5168) present in any single standard. Unicode never made separate code points for the two variants.
The cursive reduction of 糸 (U+7CF8) is just that, a cursive form. The radical components are semantically identical. Yet in mainland China, separate encoding of 紅 (U+7D05) and 红 (U+7EA2) meant separate code points in Unicode as well.
The cursive reduction of 艸 (U+8278) in characters like 草 (U+8349) had a different history with regards to encoding. The variants differ in that the top radical is one unbroken horizontal line in Simplified Chinese, while two separate horizontal lines in Traditional Chinese. Both 紅 (U+7D05) and 草 (U+8349) got new simplified forms in mainland China that changed the number of strokes, but unlike 紅, the PRC never encoded a separate 草 (U+8349). The result is reliance on language metadata for the variants of 草 (U+8349), but separate code points for the variants of 紅 (U+7D05).
Unicode used separate code points that were already in use to maintain round-trip compatibility in conversion. Later though, Unicode never declared full equivalence and the reference glyphs are different for variants like 內 (U+5167) and 内 (U+5185). Had it done so, all variants of all characters would be expressed through language tags in HTML and other metadata.
Unicode also refrained from going further in separation (barring some exceptions involving rare characters). Unicode did not separate any characters that were not already separately encoding in pre-existing standards in mainland China or Japan. Following the separate encoding of variants like 紅 (U+7D05) and 红 (U+7EA2), one might expect the same treatment for 草 (U+8349), but Unicode did not disunify the glyphs.
The result is that some characters with Simplified Chinese or shinjitai (Japan) variants got separate code points (e.g. 紅 and 红), but not all changes brought about by simplification were reflected in unique code points (e.g. three-stroke version of the radical at top of 草), and also variant characters that differ in shape, stroke count, stroke order or radical composition (e.g. variants of 全) often do not have unique code points.
Examples of some non-unified Han ideographs
For more striking variants, Unicode has encoded variant characters, making it unnecessary to switch between fonts or lang attributes. In the following table, each row compares variants that have been assigned different code points.[2] Note that for characters such as 入 (U+5165), the only way to display the two variants is to change font (or lang attribute) as described in the previous table. However, for 內 (U+5167), there is an alternate character 内 (U+5185) as illustrated below. For some characters, like 兌/兑 (U+514C/U+5151), either method can be used to display the different glyphs.
| Simplified | Traditional | Japanese | Other variant | English |
|---|---|---|---|---|
| U+4E22 丢 |
U+4E1F 丟 |
to lose | ||
| U+4E24 两 |
U+5169 兩 |
U+4E21 両 |
U+34B3 㒳 |
two, both |
| U+4E58 乘 |
U+4E57 乗 |
U+6909 椉 |
to ride | |
| U+4EA7 产 |
U+7522 產 |
U+7523 産 |
give birth | |
| U+4FA3 侣 |
U+4FB6 侶 |
companion | ||
| U+5151 兑 |
U+514C 兌 |
to cash | ||
| U+5185 内 |
U+5167 內 |
inside | ||
| U+522B 别 |
U+5225 別 |
to leave | ||
| U+7985 禅 |
U+894C 襌 |
meditation (Zen) | ||
| U+7A0E 税 |
U+7A05 稅 |
taxes | ||
| U+7EA2 红 |
U+7D05 紅 |
red | ||
| U+7EAA 纪 |
U+7D00 紀 |
discipline | ||
| U+997F 饿 |
U+9913 餓 |
hungry | ||
| U+9AD8 高 |
U+9AD9 髙 |
high | ||
| U+9F9F 龟 |
U+9F9C 龜 |
U+4E80 亀 |
tortoise | |
| Sources: MBDG Chinese-English Dictionary | ||||
Unicode ranges
Ideographic characters assigned by Unicode appear in the following blocks:
- CJK Unified Ideographs (4E00–9FFF)
- CJK Unified Ideographs Extension A (3400–4DBF)
- CJK Unified Ideographs Extension B (20000–2A6DF)
- CJK Unified Ideographs Extension C (2A700–2B73F)
- CJK Unified Ideographs Extension D (2B740–2B81F)
- CJK Unified Ideographs Extension E (2B820–2CEAF)
- CJK Compatibility Ideographs (F900–FAFF) (the twelve characters at FA0E, FA0F, FA11, FA13, FA14, FA1F, FA21, FA23, FA24, FA27, FA28 and FA29 are actually "unified ideographs" not "compatibility ideographs")
Unicode includes support of CJKV radicals, strokes, punctuation, marks and symbols in the following blocks:
- CJK Radicals Supplement (2E80–2EFF)
- CJK Strokes (31C0–31EF)
- CJK Symbols and Punctuation (3000–303F)
- Ideographic Description Characters (2FF0–2FFF)
Additional compatibility (discouraged use) characters appear in these blocks:
- CJK Compatibility (3300–33FF)
- CJK Compatibility Forms (FE30–FE4F)
- CJK Compatibility Ideographs (F900–FAFF)
- CJK Compatibility Ideographs Supplement (2F800–2FA1F)
- Enclosed CJK Letters and Months (3200–32FF)
- Enclosed Ideographic Supplement (1F200–1F2FF)
- Kangxi Radicals (2F00–2FDF)
These compatibility characters (excluding the twelve unified ideographs in the CJK Compatibility Ideographs block) are included for compatibility with legacy text handling systems and other legacy character sets. They include forms of characters for vertical text layout and rich text characters that Unicode recommends handling through other means.
International Ideographs Core
International Ideographs Core (IICore) is a subset of 9810 ideographs derived from the CJK Unified Ideographs tables, designed to be implemented in devices with limited memory, input/output capability, and/or applications where the use of complete ISO 10646 ideographs repertoire is not feasible. There are 9810 characters in current standard.[18]
Unihan database files
The Unihan project has always made an effort to make available their build database.[1]
The libUnihan project provides a normalized SQLite Unihan database and corresponding C library.[19] All tables in this database are in fifth normal form. libUnihan is released as LGPL, while its database, UnihanDb, is released as MIT License.
See also
- Chinese character encoding
- GB 18030
- Sinicization
- Z-variant
- List of CJK fonts
- Allography
- Variant Chinese character
References
- 1 2 "Unihan.zip". The Unicode Standard. Unicode Consortium.
- 1 2 "Unihan Database Lookup". The Unicode Standard. Unicode Consortium.
- ↑ "Unihan Database Lookup: Sample lookup for 中". The Unicode Standard. Unicode Consortium.
- ↑ "Chapter 18: East Asia, Principles of Han Unification" (PDF). The Unicode Standard. Unicode Consortium.
- ↑ Whistler, Ken (2010-10-25). "Unicode Technical Note 26: On the Encoding of Latin, Greek, Cyrillic, and Han".
- ↑ "Chapter 1: Introduction" (PDF). The Unicode Standard. Unicode Consortium.
- 1 2 "Ideographic Variation Database". Unicode Consortium.
- ↑ "Early Years of Unicode". Unicode Consortium.
- ↑ Becker, Joseph D. (1998-08-29). "Unicode 88" (PDF).
- ↑ "Unicode in Japan: Guide to a technical and psychological struggle".
- ↑ 5th Northeast Asia Trilateral Forum (NATF)
- ↑ RUC President Made Important Proposals on the 5th Northeast Asia Trilateral Forum
- ↑ 东北亚名人会公布中日韩共用常见汉字表草案
- ↑ 8th Northeast Asia Trilateral Forum (NATF)
- ↑ RUC holds International Symposium to compile the Chart of Commonly-Used 808 Chinese Characters in China, Japan and South Korea
- ↑ Forum agrees on common Chinese characters
- ↑ Global Times: Linked by language
- ↑ International Ideographs Core (IICORE)
- ↑ libunihan.sourceforge.net
| Early telecommunications |
|
|---|---|
| ISO/IEC 8859 | |
| Bibliographic use | |
| National standards | |
| EUC | |
| ISO/IEC 2022 | |
| MacOS code pages ("scripts") | |
| DOS code pages |
|
| IBM AIX code pages | |
| IBM Apple MacIntosh Emulations | |
| IBM Adobe Emulations |
|
| IBM DEC Emulations |
|
| IBM HP Emulations | |
| Windows code pages | |
| EBCDIC code pages |
|
| Platform specific |
|
| Unicode / ISO/IEC 10646 | |
| Miscellaneous code pages | |
| Related topics | |